







时间差分算法
Sarsa算法
Derive TD Target
- 回顾Discounted Return,不难推出这个时刻的回报等于这个时刻的奖励加上下个时刻的回报乘以 γ \gamma γ
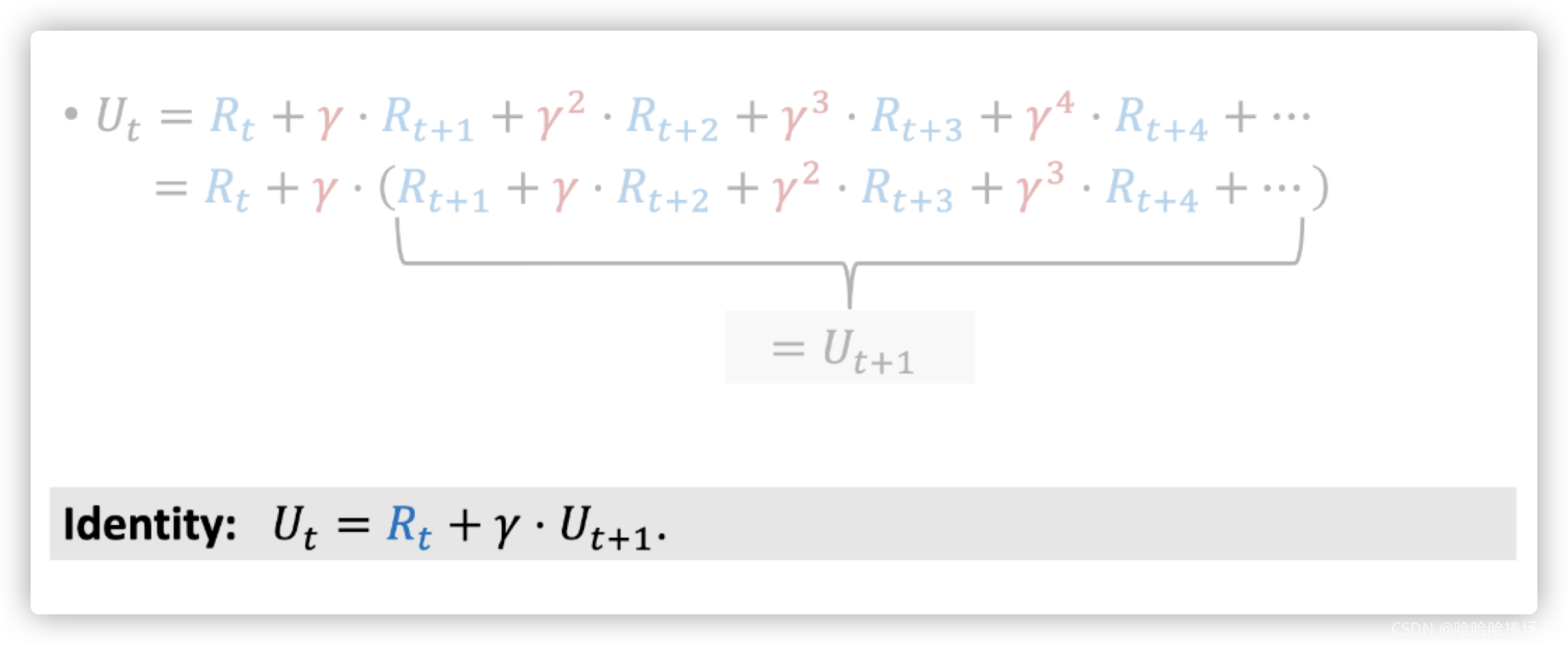
-
我们使用 U t = R t + γ ⋅ U t + 1 U_t = R_t + \gamma \cdot U_{t+1} Ut=Rt+γ⋅Ut+1来推导TD target,通常认为奖励 R t R_t Rt依赖于t时刻的动作 A t A_t At和状态 S t S_t St,以及t+1时刻的状态 S t + 1 S_{t+1} St+1,根据定义状态价值函数 Q π ( s t , a t ) Q_{\pi}(s_t,a_t) Qπ(st,at)是回报 U t U_t Ut的条件期望,这里我们假设已经观测到了当前的状态 s t s_t st和动作 a t a_t at,期望是对未来的所有的动作和状态求的,消除掉未来的不确定性。这个时候我们可以将期望中的 U t U_t Ut使用上面得到的等式替换掉。这样我们就可以将期望分解为 R t R_t Rt的期望和 U t + 1 U_{t+1} Ut+1的期望。研究 U t + 1 U_{t+1} Ut+1的期望的研究,因为 Q π ( S t + 1 , A t + 1 ) = U t + 1 Q_{\pi}(S_{t+1}, A_{t+1})=U_{t+1} Qπ(St+1,At+1)=Ut+1,所以可以替换。

-
通过上面的推导我们可以得到 Q π ( s t . a t ) = E [ R t + γ ⋅ Q π ( S t + 1 , A t + 1 ) ] Q_{\pi}(s_t.a_t)=\mathbb{E}[R_t+\gamma \cdot Q_{\pi}(S_{t+1}, A_{t+1})] Qπ(st.at)=E[Rt+γ⋅Qπ(St+1,At+1)],因为左右两边都有 π \pi π函数,所以这个等式对任何的策略 π \pi π都成立,等式右边有期望,因为求期望很困难,通常我们对期望做蒙特卡洛近似。可以将等式右边的 R t R_t Rt近似为观测到的奖励 r t r_t rt, S t + 1 , A t + 1 S_{t+1},A_{t+1} St+1,At+1都是随机变量,我们可以用观测到的值 s t + 1 , a t + 1 s_{t+1},a_{t+1} st+1,at+1,这样我们就可以得到近似值 Q π ( s t + 1 , a t + 1 ) Q_{\pi}(s_{t+1},a_{t+1}) Qπ(st+1,at+1),这样我们就得到了期望的蒙特卡洛近似,将这个近似值叫做TD target y t y_t yt。
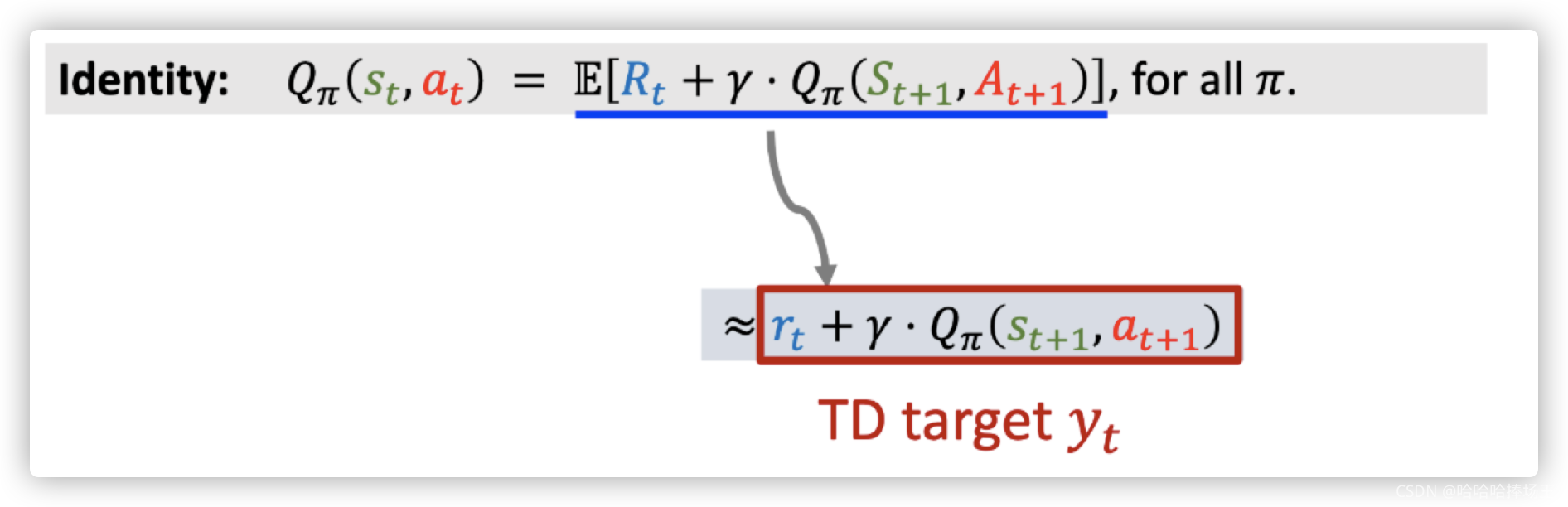
-
通过上一步推导我们将t+1时刻的期望近似成了TD target y t y_t yt, y t y_t yt部分基于真实观测到的奖励,部分基于预测。TD Learning的想法就是鼓励动作价值函数 Q π ( s t , a t ) Q_{\pi}(s_t,a_t) Qπ(st,at)接近 y t y_t yt,这是因为动作价值函数 Q π ( s t , a t ) Q_{\pi}(s_t,a_t) Qπ(st,at)全是估计,而 y t y_t yt部分基于真实值,所以我们认为 y t y_t yt更可靠。

Sarsa: Tabular Version
- 我们想要学习动作价值函数 Q π ( s , a ) Q_{\pi}(s,a) Qπ(s,a),它的输入状态s和动作a,如果输入的状态和动作是有限的,那么我们可以画一个表格,表格中的一列对应一个动作,一行对应一个状态,表格的一个元素对应一个动作价值。我们要做的就是使用Sarsa算法来更新表格,每次更新一个元素。

- 每次观测到一个四元组, ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1),一个四元组称为一个transition。将动作记为: a t + 1 a_{t+1} at+1。然后计算TD target y t y_t yt,一部分是真实的奖励 r t r_t rt,另一部分是动作价值函数给下一个动作打的分数。动作价值函数可以通过查阅表格得到 s t + 1 s_{t+1} st+1行, a t + 1 a_{t+1} at+1列的元素, 通过查表还可以知道 Q π ( s t , a t ) Q_{\pi}(s_t,a_t) Qπ(st,at)的值,这样就可以得到TD error了,这样就可以使用可以使用TD error来更新,将更新的值写入表格相应的位置。

Sarsa’s Name
- Sarsa名字的由来

Sarsa: Neural Network Version
- 如果状态空间很大,使用表格法就会很难学习。可以用神经网络来近似动作价值函数,得到的神经网络就叫做价值网络。
- 使用神经网络来近似动作价值函数,记为: q ( s , a ; w ) q(s,a;w) q(s,a;w),参数记为:w。这里的动作价值函数和价值网络都和策略 π \pi π有关。价值网络的输入是当前的状态,输出是所有动作的价值的向量。
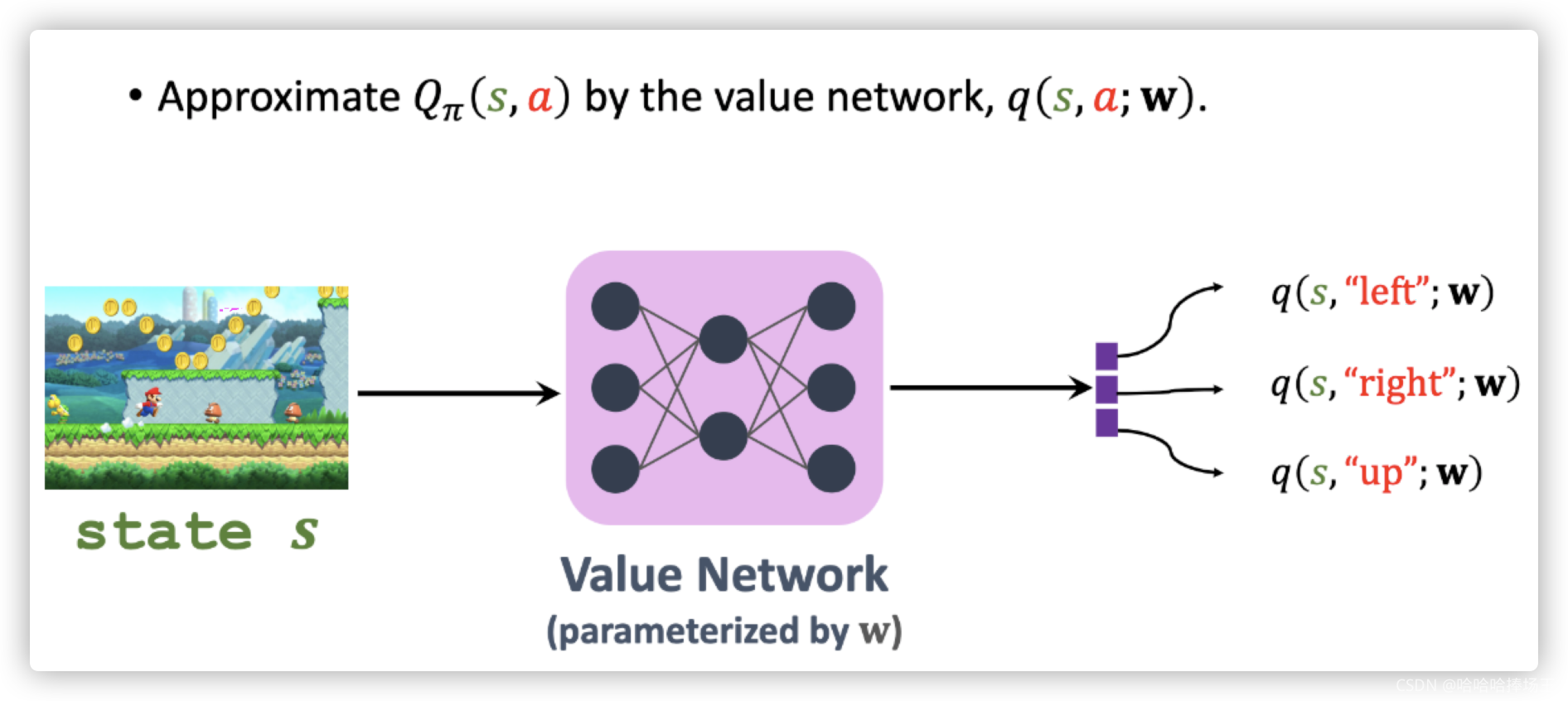
- 之前我们在Actor-Critic方法中使用到了价值网络q,它被称为Critic,用来评价Actor的表现。价值网络的参数w,一开始是随机初始化的,我们要用观测到的奖励来更新w。TD target y t y_t yt一部分是真实的奖励 r t r_t rt,另一部分是价值网络q对t+1时刻价值的估计,这样我们可以计算TD error,我们希望TD error的值越小越好。我们将损失函数记为: δ 2 / 2 \delta ^2 /2 δ2/2. 对损失函数关于参数求梯度,最后使用梯度下降更新w。

Summary

Q-Learning
Sarsa VS Q-Learning
- Sarsa和Q-Learning都是TD算法,但是他们解决的问题不同。Sarsa用来训练动作价值函数 Q π ( s , a ) Q_{\pi}(s,a) Qπ(s,a)
- TD target为当前时刻的奖励 r t r_t rt以及 γ ⋅ Q π ( s t + 1 , a t + 1 ) \gamma \cdot Q_{\pi}(s_{t+1}, a_{t+1}) γ⋅Qπ(st+1,at+1)的和
- 我们之前使用Sarsa来更新价值网络

- Q-learning用来训练最优动作价值函数 Q ∗ ( s , a ) Q^{*}(s,a) Q∗(s,a)
- Q-learning的TD target: y t = r t + γ ⋅ m a x a Q ∗ ( s t + 1 , a ) y_t=r_t+\gamma \cdot \underset{a}{max}Q^{*}(s_{t+1},a) yt=rt+γ⋅amaxQ∗(st+1,a)
- 我们使用Q-learning来更新DQN
Derive TD Target
- 首先推导Q-learning的TD target
- 在之前我们证明了 Q π = E [ R t + γ ⋅ Q π ( S t + 1 , A t + 1 ) ] Q_{\pi}=\mathbb{E}[R_t+\gamma \cdot Q_{\pi}(S_{t+1}, A_{t+1})] Qπ=E[Rt+γ⋅Qπ(St+1,At+1)],对于任何的策略 π \pi π该等式都成立
- 我们将最优的策略记为: π ∗ \pi^* π∗,上面的等式对最优的策略 π ∗ \pi^* π∗也成立,所以我们就可以得到 Q π ∗ = E [ R t + γ ⋅ Q π ∗ ( S t + 1 , A t + 1 ) ] Q_{\pi ^*}=\mathbb{E}[R_t+\gamma \cdot Q_{\pi ^*}(S_{t+1}, A_{t+1})] Qπ∗=E[Rt+γ⋅Qπ∗(St+1,At+1)],我们通常将 Q π ∗ Q_{\pi ^*} Qπ∗记为: Q ∗ Q^* Q∗,他们都表示最优动作价值函数。所以我们可以写为期望的形式 Q ∗ ( s t , a t ) = E [ R t + γ ⋅ Q ∗ ( S t + 1 , A t + 1 ) ] Q^*(s_t,a_t)=\mathbb{E}[R_t + \gamma \cdot Q^*(S_{t+1}, A_{t+1})] Q∗(st,at)=E[Rt+γ⋅Q∗(St+1,At+1)]

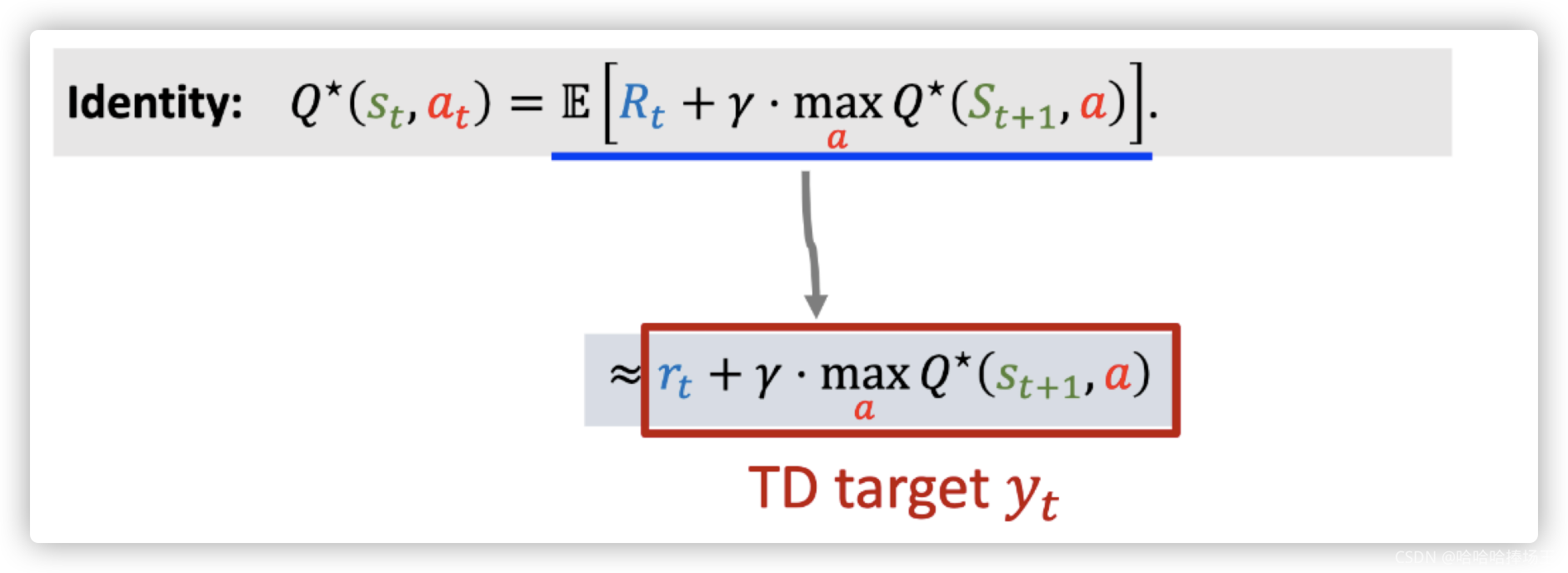
- Q ∗ ( s t , a t ) = E [ R t + γ ⋅ Q ∗ ( S t + 1 , A t + 1 ) ] Q^*(s_t,a_t)=\mathbb{E}[R_t + \gamma \cdot Q^*(S_{t+1}, A_{t+1})] Q∗(st,at)=E[Rt+γ⋅Q∗(St+1,At+1)], Q ∗ Q^* Q∗可以评价动作的好坏,给定状态 S t + 1 S_{t+1} St+1, Q ∗ Q^* Q∗可以给所有的动作打分,然后Agent会执行分数最高的动作,给定状态 S t + 1 S_{t+1} St+1选出的动作,一定是使 Q ∗ Q^* Q∗最大化的动作。所以 A t + 1 = a r g m a x a Q ∗ ( S t + 1 , a ) A_{t+1}=\underset{a}{argmax}Q^*(S_{t+1}, a) At+1=aargmaxQ∗(St+1,a),所以 Q ∗ ( S + t + 1 , A t + 1 ) Q^*(S_+{t+1},A_{t+1}) Q∗(S+t+1,At+1)可以写为对 Q ∗ ( S t + 1 , a ) Q^*(S_{t+1},a) Q∗(St+1,a)关于动作a求最大化,因为 A t + 1 A_{t+1} At+1是最优动作,所以可以最大化 Q ∗ Q^* Q∗

- 由上面我们可以推导出下面的公式,可以得到下面的等式

- 由于我们求期望很复杂,所以我们可以对期望求蒙特卡洛近似,我们可以将奖励
R
t
R_t
Rt近似成为观测到的奖励
r
t
r_t
rt,期望中有状态
S
t
+
1
S_{t+1}
St+1我们使用观测到的状态
s
t
+
1
s_{t+1}
st+1代替,这样我们就可以得到近似值
m
a
x
a
Q
∗
(
s
t
+
1
,
a
)
\underset{a}{max}Q^{*}(s_{t+1}, a)
amaxQ∗(st+1,a),这样我们就得到了期望的蒙特卡洛近似
r
t
+
γ
⋅
m
a
x
a
Q
∗
(
s
t
+
1
,
a
)
r_t+\gamma \cdot \underset{a}{max} Q^*(s_{t+1}, a)
rt+γ⋅amaxQ∗(st+1,a),将这个近似值记作TD target
y
t
y_t
yt,因为
y
t
y_t
yt是基于真实值的,所以它比等式左边更加接近真实值。
Q-Learning: Tabular Version
- 每次观测到一个transition: ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)
- 用 s t + 1 s_{t+1} st+1来计算TD target y t y_t yt,这里要对 Q ∗ Q^* Q∗关于a求最大化, Q ∗ Q^* Q∗就是表格,我们要查表,找到状态 s t + 1 s_{t+1} st+1对应的行,找出这一行最大的元素,最大的元素就是最大值

- 然后计算TD error,最后使用TD error来更新 Q ∗ Q^{*} Q∗
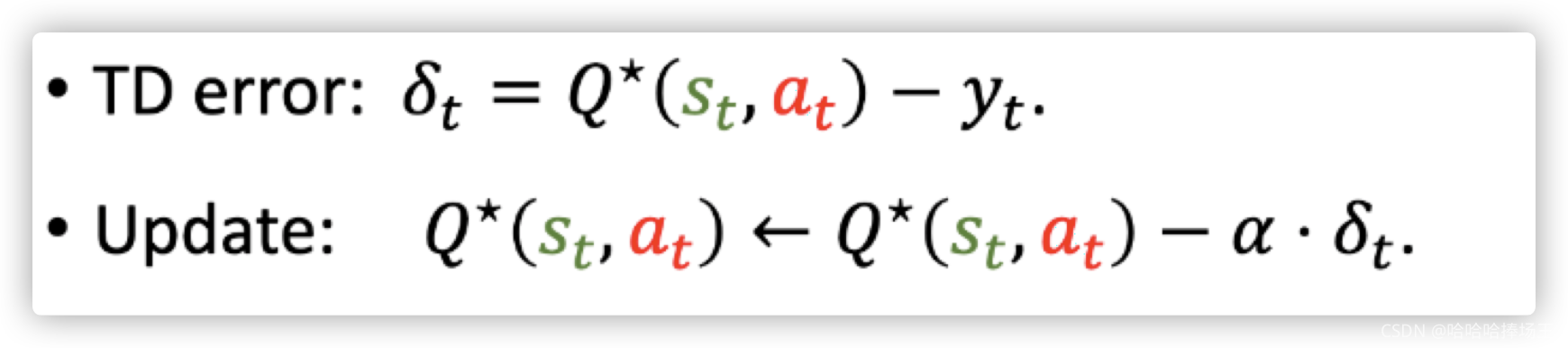
Q-Learning: DQN Version
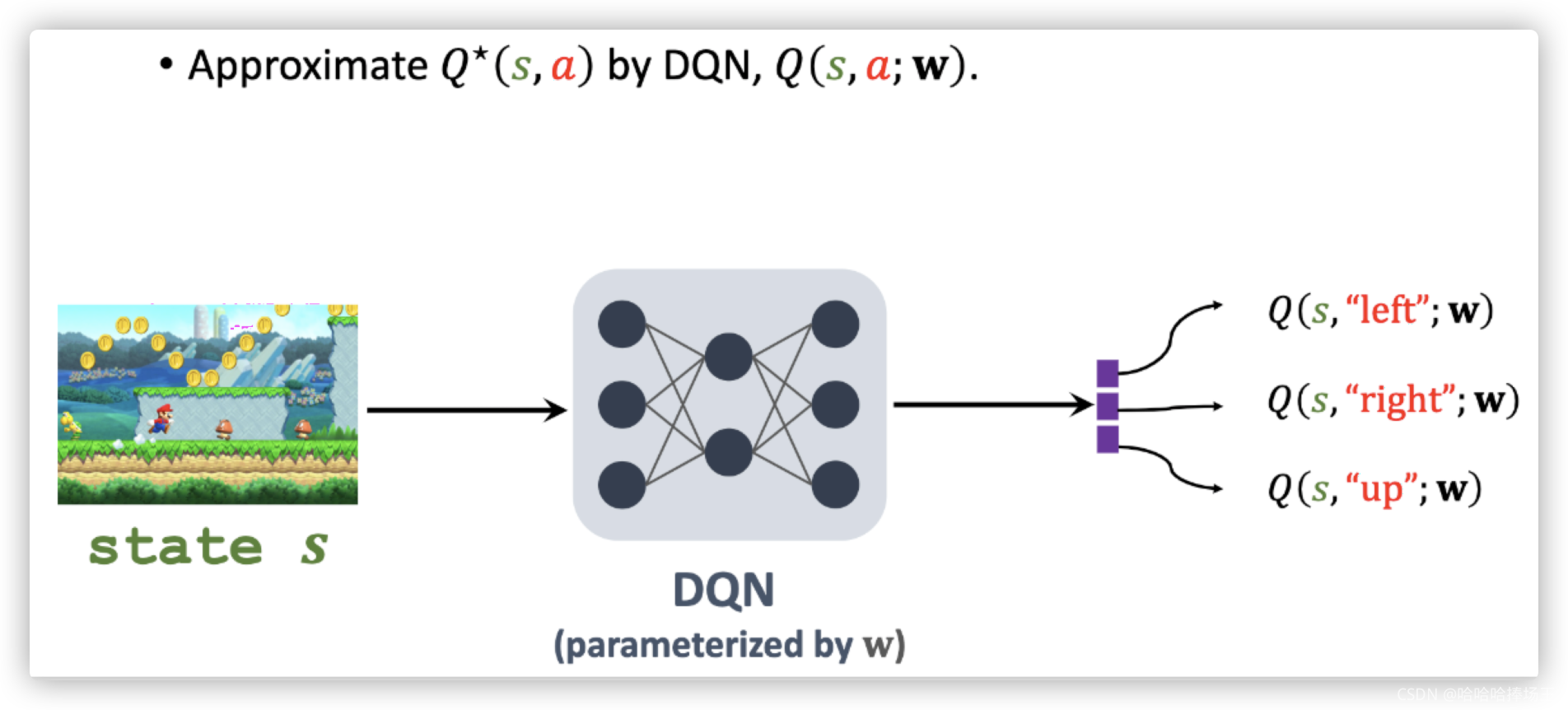
- DQN是对最优动作价值函数 Q ∗ Q^* Q∗的近似,
-
DQN控制Ageng,通过最大化Q函数,得到动作,让Agent执行
-
我们使用收集到的transition来更新w,让DQN得到的价值更加准确

-
训练DQN最常用的算法就是Q-Learning,它是一种TD算法,以前说过,这里回顾一下。
- 每次观测到一个transition
- 然后计算TD target,既要用到真实值,也要用到预测
- 计算TD error,我们的算法希望得到的TD error尽量小
- 所以做一次梯度下降来更新网络的参数,这样就可以见效TD error了
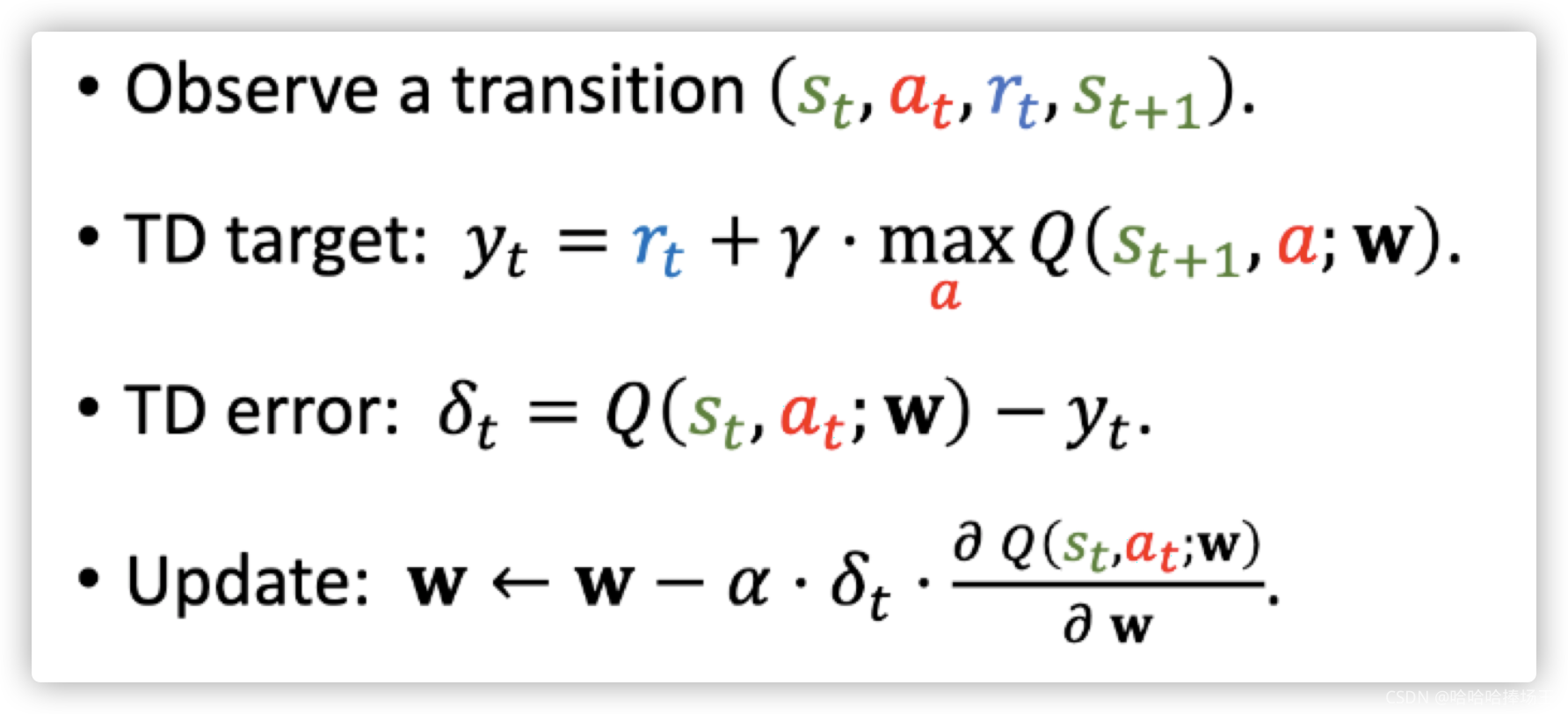
Summary

Multi-Step TD Target
Sarsa vs Q-Learning

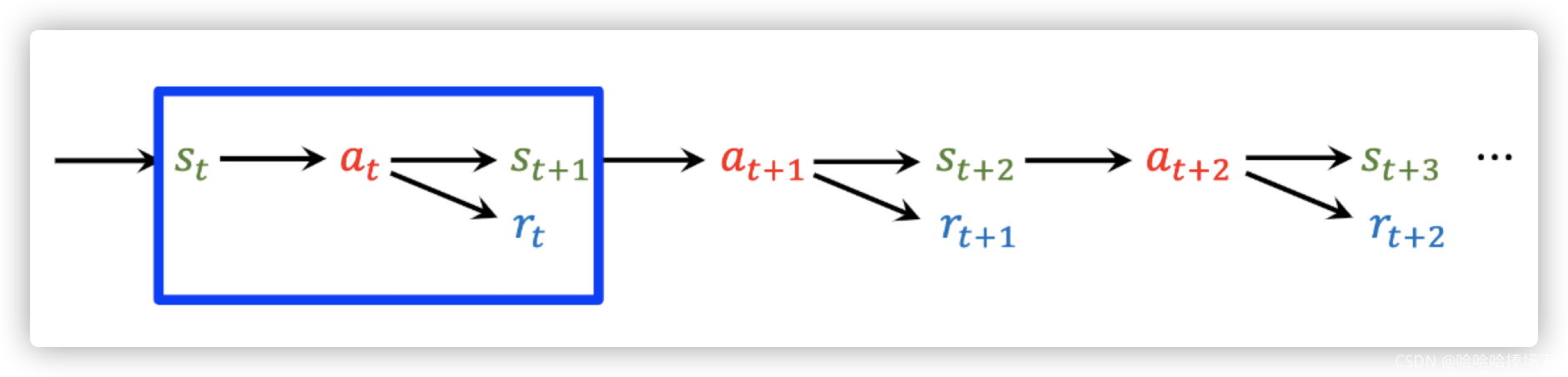
- 上面我们可以看到不管我们使用什么方法,它都包含一个奖励 r t r_t rt
Using One Reward
- 使用两个奖励来更新,效果更好
Multi-Step Return
- 之前我们得到: U t = R t + γ ⋅ U t + 1 U_t = R_t + \gamma \cdot U_{t+1} Ut=Rt+γ⋅Ut+1,我们可以使用 R t + 1 + γ ⋅ U t + 2 R_{t+1}+\gamma \cdot U_{t+2} Rt+1+γ⋅Ut+2来替换 U t + 1 U_{t+1} Ut+1,这样我们就可以得到 U t = R t + γ ⋅ R t + 1 + γ 2 ⋅ U t + 2 U_t=R_t + \gamma \cdot R_{t+1} + \gamma ^2 \cdot U_{t+2} Ut=Rt+γ⋅Rt+1+γ2⋅Ut+2,这样我们可以让回报包含两个奖励,同样的道理我们可以让回报包含多个奖励,将下面最后得到的公式叫做Multi-Step Return
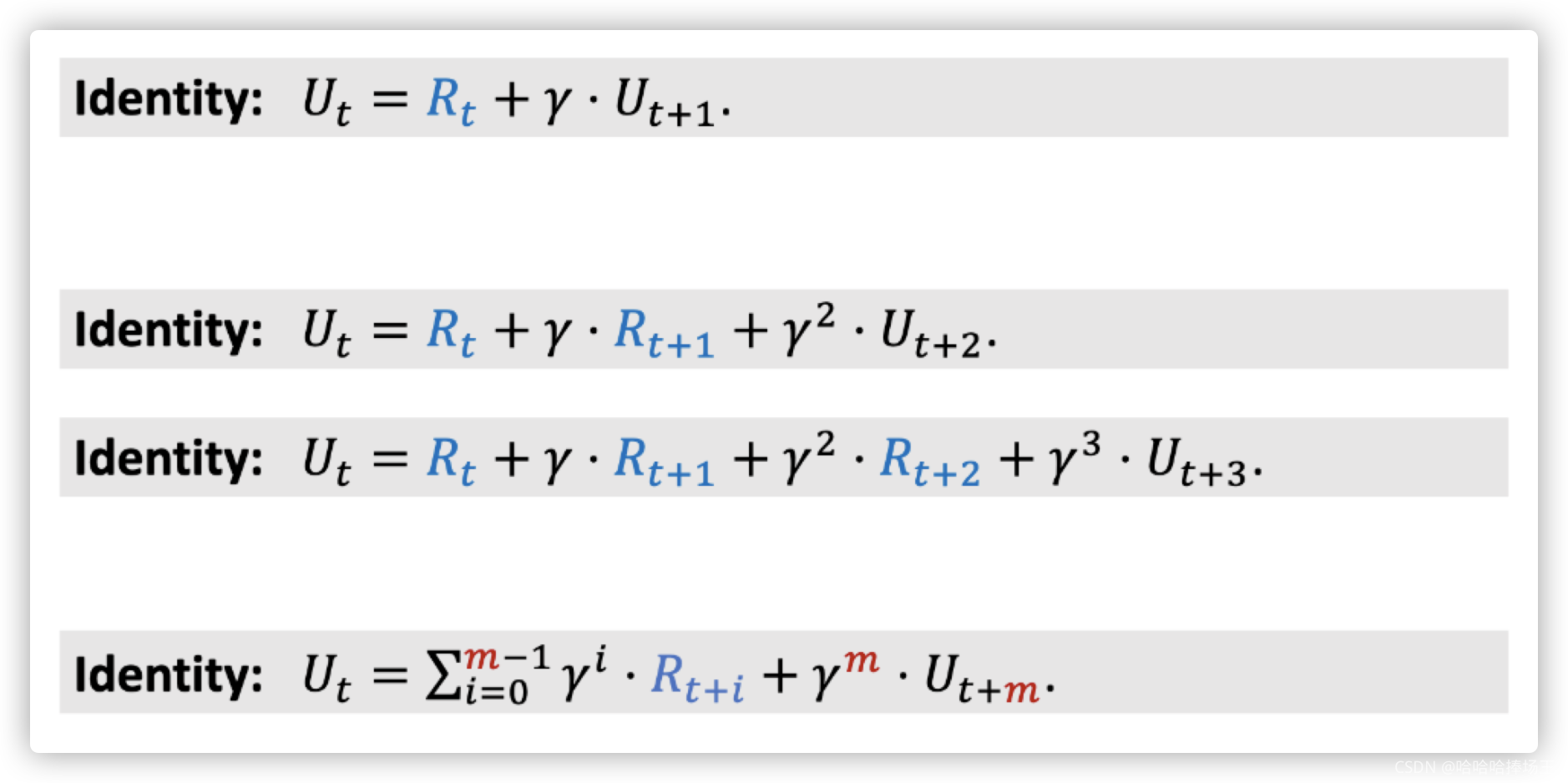
- 由上面我们得到的回报的公式,我们可以推导出TD target
y
t
y_t
yt的公式,下面就是得到的公式,其中小r表示真实的奖励,后面一项是期望。


One-Step vs Multi-Step



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









