







什么是javaIO,I=input, O=output, javaIO指的是一系列负责与外部文件交互读写的对象。IO流根据数据传输方向分为
- 输入流 从外部文件或者网络设备读取数据到内存中
- 输出流 从内存中将数据输出到外部文件或者网络设备中
根据数据流的角色不同分为节点流和处理流(也称包装流)
- 节点流 直接与数据源连接的流,也被成为基础流
- 处理流 建立在节点流之上的流,通过封装一个已存在的流实现更强大的读写功能
根据传输数据的基本单位分为字节流和字符流
- 字节流 处理基本单元是单个字节,字节流通常用来处理二进制数据,用途比较广,比如视频、图片等数据源。
- 字符流 处理的基本单元是Unicode码元,字符流通常用来处理文本数据。
讲java IO流之前,先补充个类File,java中万物皆对象,当我们需要与外部文件进行交互读写时,java提供了File类对象对目标文件或者设备进行表示,也可以说是封装。File对象可以新建、删除、重命名文件,也可以检测当前file是文件还是目录、是否存在、可读、可写等功能,但是不能对文件内容进行读写,文件读写需要javaIO流实现。
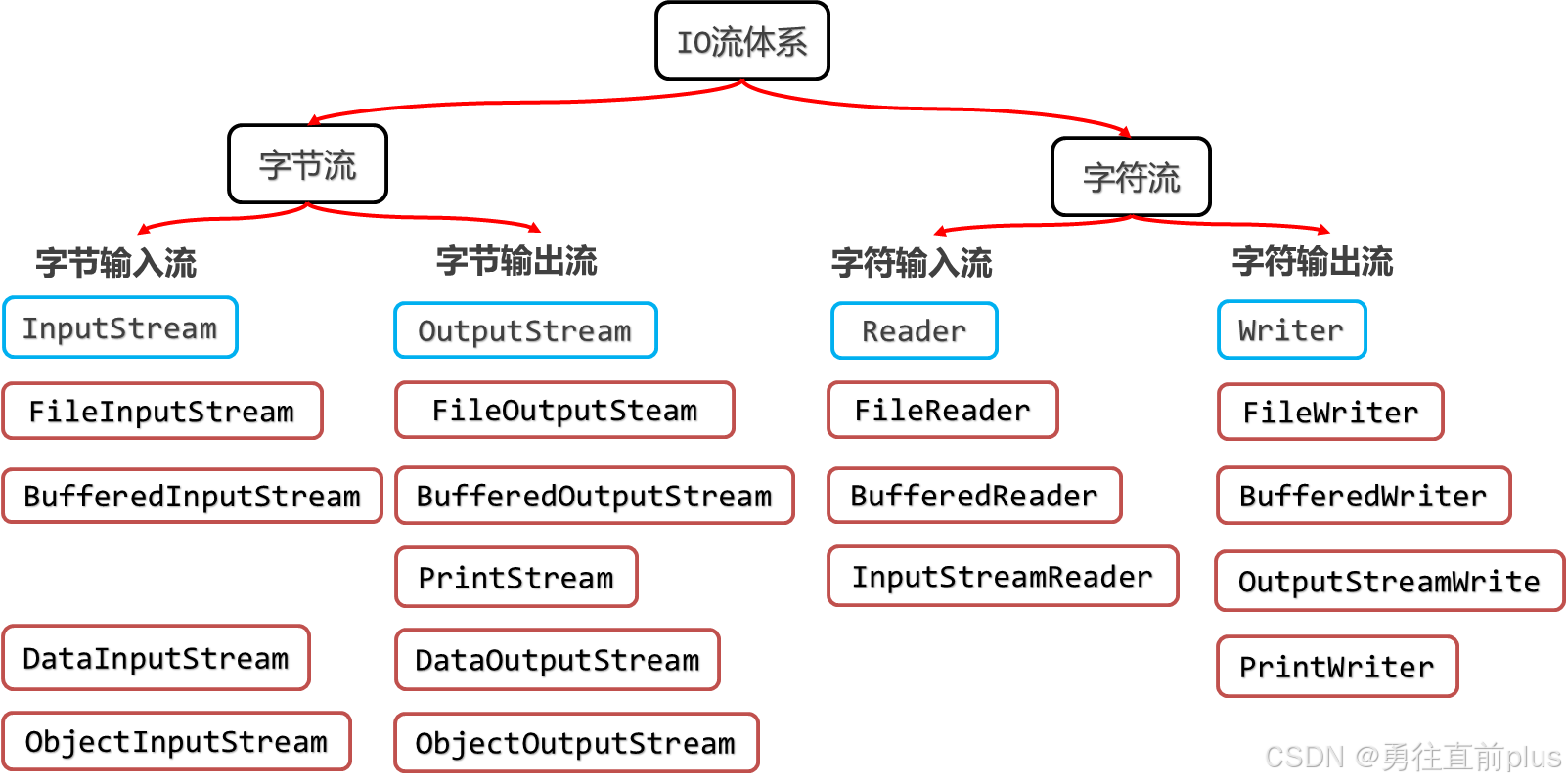
javaIO体系看着复杂,实际上都是InputStream、OutputStream、Reader、Writer这4个抽象类派生的,这4个基类分别是节点输入流、节点输出流,字符输入流、字符输出流。
- 其中FileInputStream,FileOutputStream,FileReader,FileWriter是整个javaIO体系最重要的节点流,其他处理流基本都会封装这4个节点流;其中前两个文件字节流不包含缓冲区,需要相对频繁地委托操作系统进行磁盘IO,读写效率较低;后两个文件字符流因为需要将读取的已编码的字节数据解码为码元序列,所以内置缓冲区。因此,当写入文件时,就算是没有close或者flush文件字节流,数据也会写入到磁盘文件中;而文件字符流因为内置缓冲区,所以最后close流资源时会将缓冲区数据写入到磁盘时,如果没有正常close流资源,可能会导致数据丢失,没有写入文件。
//文件字节输入流经典程序
FileInputStream fileInputStream = new FileInputStream("");
byte[] bytes = new byte[1024]; //在内存中定义一个字节数组,用于接收数据
int len = 0;
while ((len = fileInputStream.read(bytes)) != -1){
System.out.println(new String(bytes,0,len,"utf-8")); //将读取的字节数据解码
}
fileInputStream.close();
//文件字节输出流经典程序
FileOutputStream fileOutputStream = new FileOutputStream("");
byte[] data = "abcd".getBytes("utf-8");//将字符串utf8编码成字节数据,
//字节输出流只能传输字节数据,不能直接传输字符数据
fileOutputStream.write(data);
fileOutputStream.close();
//文件字符输入流经典程序
FileReader fileReader = new FileReader("");
char[] chars = new char[1024];//可以看到,fileReader一次读入的最小单元是一个字符
int len = 0;
while ((len = fileReader.read(chars)) != -1){
System.out.println(new String(chars,0,len));//将字符数组拼接成字符串打印
}
//文件字符输出流经典程序
FileWriter fileWriter = new FileWriter("");
String msg = "abcd";
fileWriter.write(msg);//字符输出流可以直接将字符数据编码后输出到文件中
fileWriter.flush();
fileWriter.close();
- 缓冲流是javaIO中用的最多的处理流,内置缓冲区,在创建流对象时会创建一个内置的默认大小的缓冲区,通过缓冲区读写,减少操作系统的磁盘IO,提高读写效率。
//缓冲文件字节输入流经典程序
FileInputStream fileInputStream = new FileInputStream("");
//因为是处理流,需要在构造函数内封装传入其他流
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
byte[] bytes = new byte[1024];
int len = 0;
//每次从文件读数据会先读到缓冲区,再从缓冲区吧数据放到字节数组
while ((len = bufferedInputStream.read(bytes))!=-1){
System.out.println(new String(bytes,0,len));
}
//缓冲文件字节输出流经典程序
FileOutputStream fileOutputStream = new FileOutputStream("");
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fileOutputStream);
bufferedOutputStream.write("abcd".getBytes("utf-8"));
//缓冲输出流,因为内置缓冲区,最后不要忘了flush或者close,否则数据丢失
bufferedOutputStream.flush();
bufferedOutputStream.close();
//缓冲文件字符输入流经典程序
FileReader fileReader = new FileReader("");
BufferedReader bufferedReader = new BufferedReader(fileReader);
//基本程序
// char[] chars = new char[1024];
// int len = 0;
// while ((len = bufferedReader.read(chars)) != -1){
// System.out.println(new String(chars,0,len));
// }
// BufferedReader提供了一个方法,每次从缓冲区解码读取一行字符串
String line; //声明一个String类型的变量
while ((line = bufferedReader.readLine()) != null){
System.out.println(line);
}
bufferedReader.close();
//缓冲文件字符输出流经典程序
FileWriter fileWriter = new FileWriter("");
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
bufferedWriter.write("abcd");
//BufferedWriter 新增了这个方法,向缓冲区输出一个换行符
bufferedWriter.newLine();
bufferedWriter.close(); // 调用close会先执行一次flush
- 需要补充的知识,因为字符输入流和字符输出流会对文件字符已编码的字节数据解码成Unicode码元,或者将内存中的字符串Unicode码元序列编码成字节数据,有人会问编码和解码的字符集是什么,我们是否在开发程序的时候可以指定,答案是fileReader和fileWriter会采用当前项目默认的字符集,我们在程序开发过程中不能指定
- 如果我们读取文件内容或者输出信息到文件时需要指定其他字符集怎么办,java为开发人员提供了两个转换流,InputStreamReader和OutputStreamWriter,这两个流首先是字符流,继承自Reader和Writer这两个抽象类,其次这两个流是处理流,在创建对象时都需要连接一个字节流对象;InputStreamReader是将字节输入流转换成字符输入流,用于将字节输入流读取的字节数据通过制度的字符集解码成unicode码元序列,OutputStreamWriter是将字节输出流转换成字符输出流,用于将Unicode码元序列按照制定的字符集编码成字节数据,再调用封装的字节输出流输出将字节数据输出到文件中。
//输入转换流
FileInputStream fileInputStream = new FileInputStream("");
//转换流可以指定解码字符集
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream,"utf-8");
char[] chars = new char[1024];
int len = 0;
while ((len = inputStreamReader.read(chars)) != -1){
System.out.println(new String(chars,0,len));
}
inputStreamReader.close();
//输出转换流,将字符串编码,再调用封装的字节输出流输出到文件中
FileOutputStream fileOutputStream = new FileOutputStream("");
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(fileOutputStream);
outputStreamWriter.write("abcd");
outputStreamWriter.close();
- 其他的IO流这里不再概述,学习的方式很简单,首先看是字符流还是字节流,字符流是处理字符数据的,涉及到编码解码,字节流是直接处理字节数据的,作用可能是将内存中某块区域,比如一个对象输入输出到文件中,最后再看是输入还是输出。
- 最后我们再谈一下编码解码知识,我们前文说的内存中的Unicode码元指的是解码后Unicode字符集单个字符的码点,是个整数,表示这个字符在unicode字符集的位置;在计算机系统中存在多个字符集,每个字符集对应的编码规则,以我们最常用的Unicode字符集为例,其对应的编码方式常用的就有3种:utf8编码、utf16编码、utf32编码;那字符集和其对应的编码方式有什么关系呢?一个字符在程序执行的内存中是以字符集码元的形式存在的,输出到文件中需要将这个码元按照对应的编码方式编码,把编码后的数据存储在文件中;解码正好相反,需要从文件中读取字节数据,根据编码规则将字节数据解码成码元,放到内存中。那为什么不直接吧Unicode字符集直接存储到文件中,这样就不需要编码和解码了?还是以Unicode字符集为例,以汉字“汉”为例,它的 Unicode 码元是 0x6c49,对应的二进制数是 110110001001001,二进制数有 15 位,这也就说明了该码元在内存中需要 2 个字节来表示,那有些字符的码元可能是3个字节,4个字节,如果我们直接将这些码元存储到文件中,后期我们从文件中读数据的时候,计算机不知道读取的这三个字节是代表一个码元还是前两个字节是一个码元;所以我们必须为每个字符集设计一个编码方式,按统一的规则将内存中的码元编码,再放到文件中,这样我们从文件中读取数据后,计算机再按照指定的规则将码元从编码的字节数据中解码出来,比如 当计算机读到第一个字节:11…时,计算机就知道该码元需要从两个连续字节里解码出来,假如读到的是111…,计算机就从这三个连续的字节将码元解码出来。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









