







Spring源码学习(一)Bean的生命周期以及循环依赖问题
网络上一些讲解Spring的依赖循环问题,使用的spring版本很多都比较久远,不是最新的版本。下面根据官方文档和源码分析5.3.9版本的spring中是如何创建Bean实例的,以及其整个生命周期。并且从源码的角度说明spring是如何通过三级缓存解决循环依赖问题的。
1. 实验准备
首先简单设计一个demo项目,构建两个实例A和B:
public class InstanceA {
private InstanceB b;
public InstanceB getB() {
return b;
}
public void setB(InstanceB b) {
this.b = b;
}
}
public class InstanceB {
private InstanceA a;
public InstanceA getA() {
return a;
}
public void setA(InstanceA a) {
this.a = a;
}
}
配置文件通过设置其property 使得其产生依赖循环
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="a" class="com.example.springcycledependency.config.InstanceA">
<property name="b" ref="b"></property>
</bean>
<bean id="b" class="com.example.springcycledependency.config.InstanceB">
<property name="a" ref="a"></property>
</bean>
</beans>
实现类为:
public class application {
public static void main(String[] args) {
ApplicationContext xc=new ClassPathXmlApplicationContext("aa.xml"); // 配置文件名字为aa.xml
InstanceA instanceA=xc.getBean(InstanceA.class);
String version= SpringVersion.getVersion(); // 获取spring的版本号
System.out.println(version);
}
}
2. 实验过程
首先debug进入ClassPathXmlApplicationContext进入refresh方法

refresh中主要进行以下两个步骤:完成Bean工厂的初始化以及结束Refresh()

进入finishBeanFactoryInitialization中,直接找到preInstantiateSingletons,这个方法的作用顾名思义就是提前初始化一些单例。

进入之后,可以看到最后会执行根据beanName获取Bean实例的方法

getBean中基本就是复写了一些doGetBean的方法,其中的核心就是根据当前维护的一级缓存 singletonObjects(基于ConcurrentHashMap),获取一个SharedInstance对象,这个对象可能为空。
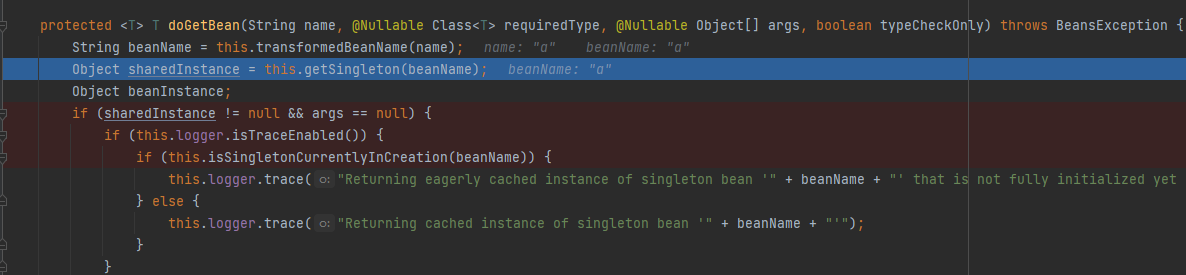
如果之前缓存中不存在该实例,则会跳转,执行doCreateBean方法,创建新的Bean实例。该方法中主要执行了下图中的三个步骤:
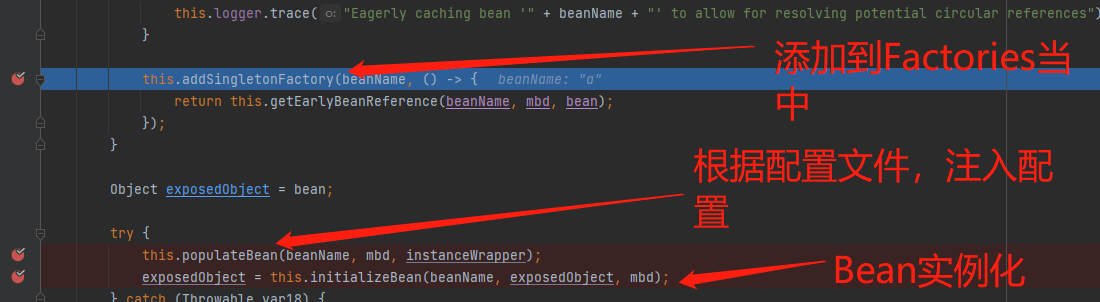
这时,首先跳转到addSingletonFactory方法中,这里主要逻辑为,当一级缓存中不存在对应的实例的话,说明该实例没有注入配置,所以首先将实例放在三级缓存中。

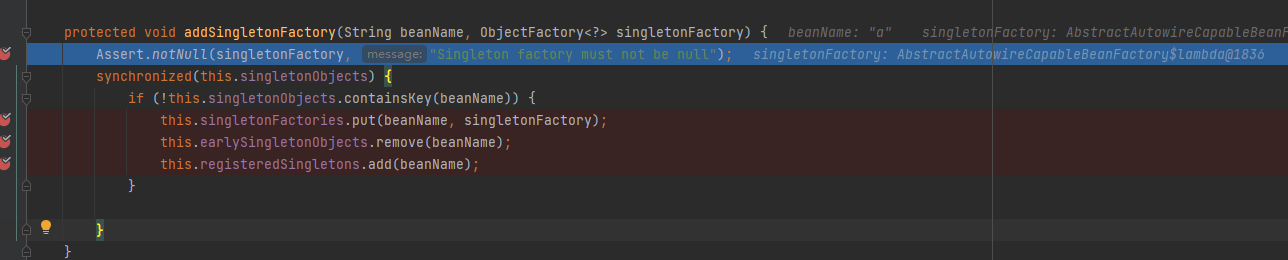
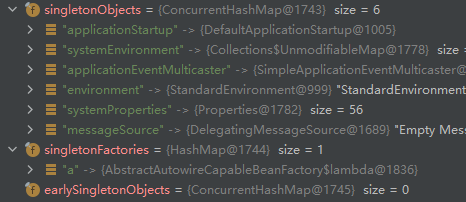
执行完成后,发现a实例已经初步被缓存到三级缓存当中了。
接下来,跳转回来,注入a对应的Bean实例在xml中的相关配置。执行populateBean方法。demo中仅对其赋予了Property的属性,因此跳转到方法applyPropertyValues

之后通过property的配置,发现其注入了Bean 对象,名称为b,调用resolveValueIfNecessary
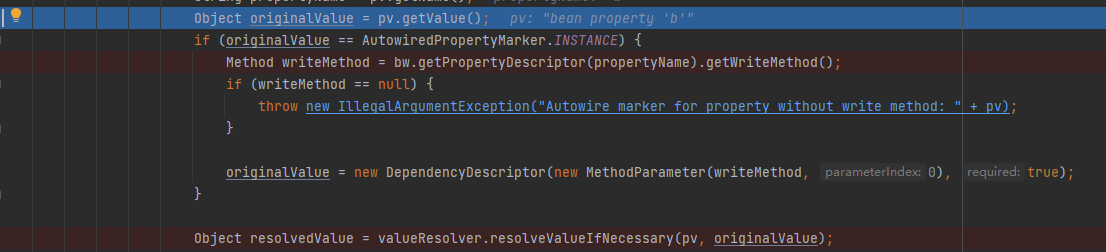
之后发现开始对Bean对象b进行了a之前相同的动作,doGetBean() -> getSingleton()->addSingletonFactory()等步骤。可以看到此时的三级缓存分别为:
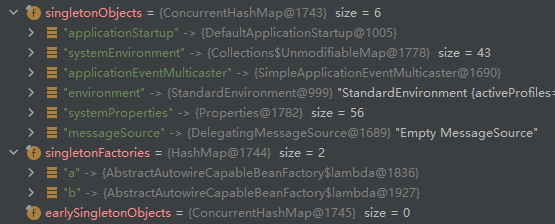
这个时候b也已经初步被注入到了三级缓存singletonFactories当中。之后同样的,进行populateBean的动作,发现xml配置里面有property的属性,执行applyPropertyValues,获取到propertyName为a,发生了循环依赖。

进一步执行调用resolveValueIfNecessary,a第二次执行调用doGetBean方法,获取a的Bean对象,跟一开始不同的地方在于,此时三级缓存中已经有初步的a和b的Bean实例对象了。此时进入getSingleton方法后,会首先再次嵌套调用doGetBean方法,第二次重新调用getSingleton后,singletonObject不再为null,此时a从三级缓存删除,放到二级缓存。
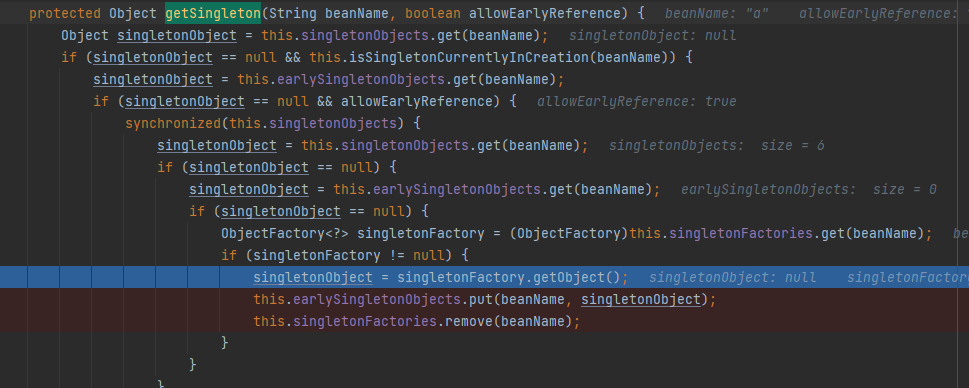
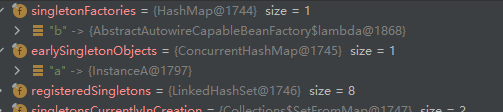
之后,跳出内部的嵌套,回到b这一层的配置注入,此时回到b执行applyPropertyValues方法的过程当中。之后,b完成属性的注入,执行initializeBean方法,完成Bean对象初始化的过程。

完成后,b由三级缓存跳转至一级缓存当中,此时说明b这个Bean实例已经实例化了。
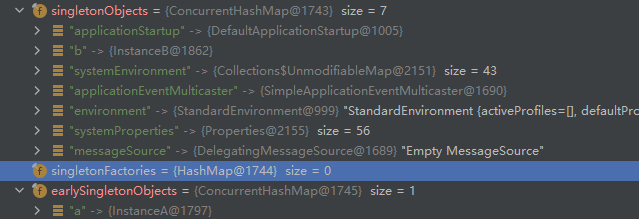
之后,跳出嵌套,回到a执行完成xml属性的配置,执行实例化,完成后a和b均放置到了一级缓存当中
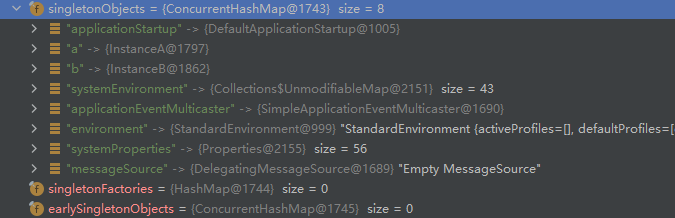
下一步,就跳出inishBeanFactoryInitialization,执行最后的finishRefresh操作。在此过程中,会生成一个被称为LifecycleProcessor的Bean实例。

spring官方文档中对LifeCycleProcessor的描述:

可以将LifeCycleProcessor的作用简单归纳为一种显示启动和停止。
3.个人总结
个人针对spring启动的大致流程可总结为以下几步:
1.创建初步的BeanFactory以及在其中存放类似于半成品的,不带有属性的Bean实例对象。
2.解析配置文件,获取到bean的所有属性、依赖及初始化用到的各类处理器等
3.刷新所有的bean容器,初始化所有的单例bean
4.注册所有的单例bean并返回可用的容器,一般为扩展的applicationContext
在出现循环依赖的情况下,spring采取的方式大致为,首先初始化Bean对象a,在三级缓存中存放一个半成品不带有属性的Bean实例对象。后续解析a的配置,并注入属性。在此过程中如果发现property引用了另一个对象b,此时以一种嵌套的形式,先处理b的Bean实例对象。假如,此时b中引用了a,即发生了循环依赖,在实例化b的过程中,会将三级缓存中的半成品a放入二级缓存当中,并将b先进行实例化。后续,回到a的属性注入的步骤,将b注入进a的Bean对象配置当中,完成a的实例化。至此,a和b均存储在一级缓存当中。二三级缓存就是为了解决循环依赖,且之所以是二三级缓存而不是二级缓存,主要是可以解决循环依赖对象需要提前被aop代理。
第一级缓存的作用?
- 用于存储单例模式下创建的Bean实例(已经创建完毕)。
- 该缓存是对外使用的。
第二级缓存的作用?
- 用于存储单例模式下创建的Bean实例(该Bean被提前暴露的引用,该Bean还在创建中)。
- 该缓存是对内使用的,指的就是Spring框架内部逻辑使用该缓存。
- 为了解决第一个classA引用最终如何替换为代理对象的问题(如果有代理对象)请爬楼参考演示案例。
第三级缓存的作用?
- 通过ObjectFactory对象来存储单例模式下提前暴露的Bean实例的引用(正在创建中)。
- 该缓存是对内使用的,指的就是Spring框架内部逻辑使用该缓存。
- 此缓存是解决循环依赖最大的功臣。
参考:官方文档

















 2835
2835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









