







1.盛最多水的容器,提供一个数组,为板子的高度,索引差为宽度,选出两块板子,是的组成的容器容积最大。暴力选择为C(n,2),当然搜索时,为了简化,注意短板效应,容积大小取决于短板和宽度。使用双指针指向数组两端,每次比较两个指针指向板子的高度,固定高的板子,向内移动短的板子,因为向内移动宽度减少,同时,由于短板效应,只能说固定长版,移动短板,期望短板变长以此来获得更大值。
class Solution:
def maxArea(self, height: List[int]) -> int:
i,j,res = 0,len(height)-1,0
while i<j:
if height[i]<height[j]:
res = max(res,height[i]*(j-i))
i+=1
else:
res = max(res,height[j]*(j-i))
j-=1
return res2.N叉树的前序遍历,使用递归或者迭代,注意两者之间的区别。
# N叉树通用递归模板
class Solution:
def preorder(self, root: 'Node') -> List[int]:
res = []
def helper(root):
if not root: # 递归中止条件
return
res.append(root.val) # 操作处理
for child in root.children:
helper(child) # 调用递归函数
helper(root)
return res
# N叉树迭代方法
class Solution:
def preorder(self, root: 'Node') -> List[int]:
if not root:
return []
s = [root]
# s.append(root)
res = [] # 记录子节点的堆栈
while s:
node = s.pop()
res.append(node.val)
# for child in node.children[::-1]:
# s.append(child)
s.extend(node.children[::-1]) # extend()直接加上一个list。和append()不同。
return res
3.有三种葡萄,每种分别有a,b,c颗。有三个人,第一个人只吃第1,2种葡萄,第二个人只吃第2,3种葡萄,第三个人只吃第1,3种葡萄。适当安排三个人使得必须吃完所有的葡萄,并且且三个人中吃的最多的那个人吃得尽量少(主要)。
将三个葡萄数想像成三条线段,三个人想象为三个顶点,则如果能构成三角形(符合两短相加大于长),则三个人一人吃掉相邻两条边的一部分就可以;如果不能构成三角形(即有一超长边),那么要把超长边平分给两个人吃,相当于折断长边,现在有4条边构成四边形,则只要两个人吃完长边后继续吃相应短边那么也没有问题,但要是两个人吃完长边后不再吃相应短边有两种情况:
- 两个人吃完长边后不再吃短边,第三人吃完短边也没有超出另两个人;
- 两人吃完长边后,如果不帮第三人吃两个短边,会使第三人吃的超过2人。
在尽量少的情况下,第一种情况的吃的最多的就是长边的1/2;第二种情况则与三角形情况相同,需要所有人均分。
因此,综合来看只有两种情况:所有人平分,或者其中两人平分最多的那种葡萄。这两个哪个大,输出哪个。
t=int(input())
for _ in range(t):
a,b,c=map(int,input().split())
maxnum=max(a,b,c)
total=a+b+c
if maxnum//2>=total-maxnum: # 两短边之和小于长边的一半
if maxnum%2==0:
print(maxnum//2)
else:
print((maxnum+1)//2) # 为了向上取整
else: # 两短边之和大于长边的一半
if total%3==0:
print(total//3)
elif total%3==1:
print((total+2)//3)
else:
print((total+1)//3)4.将一个数拆分成多个素数之和,求出所有可能的情况。
- 给定的数字下有哪些质数,通过遍历找到比该数下的质数列。
- 在遍历时,需要判断一个数是否为质数。
- 得到质数列后,需要DFS搜索出所有可能的情况。
def judge_prime(n):
if (n == 0 or n == 1): return False
if (n == 2): return True
if (n % 2 == 0): return False
# 判断
if 0 in [n % i for i in range(2, int(sqrt(n) + 1))]: # 判断一个数是否为质数
return False
return True
def equal_prime(n):
'''n拆分成素数之和'''
plist = [i for i in range(n + 1) if judge_prime(i)] # 遍历得到不大于它的质数列
DFS(n, 0, 0, plist, S=set()) # 进行DFS搜索
def DFS(n, index=0, sum_num=0, primes=[], L=[], S=set()): # L存储一次可能情况,S存所有情况
if (sum_num > n): # 搜索结束的条件1
return
if (sum_num == n): # 搜索结束时的条件2,找到了这样的一组数字
if (tuple(L) not in S): # 避免重复输出
print(L)
S.add(tuple(L)) # S是一个集合,L也要转化为元组,是为了避免append()的浅拷贝
# 只要index没有超过素数表primes的长度,就可以继续选择,超过了则不操作,迭代返回上一层
if (index < len(primes)):
L.append(primes[index]) # 存入后向下搜索
DFS(n, index + 1, sum_num + primes[index], primes, L, S)
L.pop() # 进行回溯
DFS(n, index + 1, sum_num, primes, L, S) # sum跳过了当前值
equal_prime(30)2020/08/08 网易算法内推笔试题
5.牛牛现在有n个正整数的数组a,牛牛可以将其中的每个数a[i]都拆成若干个和为a[i]的正整数,牛牛想知道拆后(也可以一个都不拆)这个数组最多能有多少个素数。示例1 输入 3 1 1 1 输出 0 说明:由于1不能再拆,并且1不是素数,所以拆后最多有0个素数
# 想要尽可能多的素数,则尽可能分解为2,除不尽的可以变成3。
n = int(input())
a = [int(item) for item in input().strip().split()]
count = 0
for i in range(n):
count += a[i] // 2 # 变相求该数最多由多少个2组成。
print(count)6.现在有n个人排队买票,已知是早上8点开始卖票,这几个人买票有两种方式:
第一种是每一个人都可以单独去买自己的票,第1个人花费a秒。
第二种是每一个人都可以选择和自己后面的人起买票,第i个人和第i+1个人共花费印秒。
最后一个人只能和前面的人起买票或单独买票。
由于卖票的地方想早些关门,所以他想知道他最早几点可以关门,请输出一个时间格式形如:08:00.40 am/pm。时间的数字要保持2位,若是上午结束,是am,下午结束是pm
输入描述:
第一行输入一个整数T,接下来对于每组测试数据:输入一个数n,代表有n个人买票。
接下来n个数,代表每一个人单独买票的时间a[i].
接下来n个数,代表每一个人和他前面那个人起买票需要的时间b[i]
输出:对于每组数据,输出一个时间表示关门的时间
# dp[i]是前i个人完成排队的最小时间。dp[0]=0,为前0个人,dp[1]为前1个人,dp[n]为前n个人。
# 由于dp的设定,虽然题目说是第i个人要么自己买,要么和i+1买,但若两人一起买,则是dp[i+1]的值,因
# 此可以看作,每个人有两种选择,第一种自己买,第二种和前面一个人一起买,因为是前i个人,所以不考虑# 和后面那个人一起买的情况
T = int(input())
for t in range(T):
n = int(input())
if n == 0:
print('08:00:00 am') # 注意特殊值
continue
elif n == 1:
ans = int(input())
else:
a = [int(item) for item in input().strip().split()]
b = [int(item) for item in input().strip().split()]
dp = [0 for _ in range(n + 1)] # 申请dp数组
dp[1] = a[0] # 前1个人,则dp[1]=a[0],但若人数大于1,则不一定第一个人就自己买。
for i in range(2, n + 1):
dp[i] = min(dp[i - 1] + a[i - 1], dp[i - 2] + b[i - 2]) # 要么单独自己买,要么和前面的人一起买
ans = dp[n]
hour = ans // 3600 + 8
mins = ans % 3600 // 60
miao = ans % 3600 % 60
if hour <= 12:
print(str(hour).rjust(2,'0') + ':' + str(mins).rjust(2,'0') + ':' + str(miao).rjust(2,'0') + ' ' + 'am')
else:
print(str(hour-12).rjust(2,'0') + ':' + str(mins).rjust(2,'0') + ':' + str(miao).rjust(2,'0') + ' ' + 'pm')7.给出n个物品和它对应的价值,可以舍弃几件物品,现在要将物品分给两个人,两个人得到的物品数量可以不一样,但是得到的价值必须是一样的,问最少可以舍弃多少价值的物品?
输入为T(有多少组案例),n(物品数量),a(有n个数字,a[i]表示第i个物品的价值)。
输出为一个数字,表示最少可以丢弃的物品价值。
思路:对于每一件物品,都会存在三种选择:1、给第一个人。2、给第二个人。3、舍弃这件物品。所以可以将问题转化为树,进行深度优先搜索,只需要搜索时寻找到达最后一件物品时,两个人手里物品的价值相同,并且找到舍弃价值最小的那一个节点即可。
import sys
T = int(sys.stdin.readline().strip())
res = float('inf')
def dfs(op, x, y):
global res # 重新声明为全局变量,调用函数外的变量
global length
global sum1
global nums
if op >= length: # op为选择货物的index
if x == y:
res = min(res, sum1-x-y) # 目前的最小值和sum1-x-y得到的比较
return
dfs(op+1, x+nums[op], y)
dfs(op+1, x, y+nums[op])
dfs(op+1, x, y) # 进行回溯
for idx in range(T):
n = int(sys.stdin.readline().strip())
nums = list(map(int, sys.stdin.readline().split()))
length = len(nums)
sum1 = sum(nums)
dfs(0, 0, 0)
print(res)
2020/08/21 滴滴笔试题
8.小明希望你能够编写一个程序,输入一个正整数n,然后逐行逐列输出斐波那契蛇形矩阵中的元素。
样例输入
3
样例输出
34 21 13
1 1 8
2 3 5
思路:先用数组求出所需的斐波拉且数列,然后按照蛇形进行排列,这里和顺时针打印数组稍有不同,顺时针打印数组可以利用list队列特性,按照规律,pop()出相应的元素,将二维的矩阵变成了一维的输出数组。但本题可以借鉴该题的其它思路,当然前面提到的pop()肯定不可以,先构建一个蛇形矩阵的框架,然后按照蛇形(顺时针)的方式去找到框架中的元素,然后将赋值斐波拉且数列赋值进去。
def func(n):
if n<2:
print(n)
return
a,b = 0,1
fab = [1]
for i in range(n*n-1):
fab.append(a+b)
a,b = b,a+b
temp = fab[::-1]
# 得到斐波拉且数列后,构建框架,按照蛇形将数列赋值进去
res = [[0]*n for _ in range(n)]
l,r,t,b,m = 0,n-1,0,n-1,0 # 蛇形输出时的四边的记录变量left,right,top,bottom
# 按照蛇形的方式,→,↓,←,↑,出现t>b or l>r就break,结束死循环。
while True:
for i in range(l,r+1): # →
res[t][i] = temp[m]
m+=1
t+=1 # 按照规则加一
if t>b:break
for i in range(t,b+1):
res[i][r] = temp[m]
m+=1
r-=1
if l>r:break
for i in range(r,l-1,-1):
res[b][i] = temp[m]
m+=1
b-=1
if t>b:break
for i in range(b,t-1,-1):
res[i][l] = temp[m]
m+=1
l+=1
if l>r:break
print(res)
if __name__ == "__main__":
n = int(input())
func(n)
9.输入字符矩阵,判断其中“CHINA”个数。该题使用递归的方法。注意回溯,方法中采用标志数组记录当前匹配过的状态。
def test02(matrix, china, rows, cols):
tmp = [True] * rows * cols # 设立标志符,如果查找到匹配的就设为Flase。
count = 0
for i in range(rows):
for j in range(cols):
res = find(matrix, tmp, rows, cols, i, j, china)#对每个二维矩阵中的元素进行尝试
count += res
print(count // 4) # 在递归中匹配完成后还要进入一次递归发现path为空,返回一,此时四个都返回
def find(matrix, tmp, rows, cols, i, j, path):
count = 0
if not path:
return 1 # 搜索完成就返回1
index = i * cols + j
if i < 0 or i >= rows or j < 0 or j >= cols \
or matrix[index] != path[0] or not tmp[index]: # 首字符不匹配,或者刚被匹配过
return 0
tmp[index] = False # 没有执行if的return,则说明匹配
# 进行递归下,向当前位置的四周搜索,抛开当前字符,匹配剩下的
count = find(matrix, tmp, rows, cols, i - 1, j, path[1:]) + \
find(matrix, tmp, rows, cols, i + 1, j, path[1:]) + \
find(matrix, tmp, rows, cols, i, j - 1, path[1:]) + \
find(matrix, tmp, rows, cols, i, j + 1, path[1:])
tmp[index] = True # 进行回溯
return count
if __name__ == '__main__':
n = int(input().strip())
matrix = []
for i in range(n):
matrix.extend(input().strip()) # extend()将一个整体list或str,按照元素加入。
test02(matrix, "CHINA", n, n) # 将字符矩阵变成一维,变成一个字典形式10.分词结果修改。输入:第一行是分好词的一句话(字符串),词与词间由空格分开,但存在一些问题;第二行是若干个需要匹配的词,词与词间有空格分开。输出:修改后的分词结果(一个字符串),词与词间由空格分开。
思路:遍历存在分词结果错误的字符串s,遇到空格直接复制到res,遇到字符进行匹配尝试,尝试当前字符与关键字中每个的首字母是否相同,相同继续匹配该关键字剩下的部分与遍历时当前字符后面的部分,遇到后面部分为空格跳过,设置标志位显示是否匹配成功。匹配成功将该关键之加入res并向前更新index,匹配失败则直接复制遍历时的当前字符。总之,暴力遍历,按照常规思维完成操作。
s = input().strip() # 存在问题的分词结果,存为一个字符串
temp = input().strip().split(" ") # 需要匹配的词
res = ""
index = 0
while index < len(s): # 遍历存在问题的分词结果,如果碰到空格复制给res,碰到字符进行判断
flag = 0
if s[index] == " ":
res += " "
index += 1
continue
for i in range(len(temp)): # 遍历碰到字符,则进行匹配
if s[index] == temp[i][0]: # 遍历时,当前字符和temp中的某个词的首字母相同,进一步匹配
t_index = index
g = 0 # 匹配是否成功的标志,1为失败
for j in range(len(temp[i])):
if s[t_index] == " ": t_index += 1 # 进一步匹配,遇到空格跳过
if s[t_index] == temp[i][j]:
t_index += 1
else:
g = 1
break
if g == 0:
flag = 1 # 匹配成功
index = t_index # 匹配成功,向前更新index
if res[-1] == " ":
res += temp[i]+" "
else:
res += " "+temp[i]+" "
break
if flag == 0: # 匹配失败,直接复制
res += s[index]
index += 1
print(res)
11.牛牛的背包问题:牛牛的背包容量为w。牛牛家里一共有n袋零食, 第i袋零食体积为v[i]。牛牛想知道在总体积不超过背包容量的情况下,他一共有多少种零食放法(总体积为0也算一种放法)。第一行输入n和w,第二行输入n个v[i]。
思路:背包问题,一般使用dp和递归。
N,W = list(map(int,input().split()))
V = list(map(int, input().split()))
def count(W, V):
if W<=0:return 1
if len(V)<=0:return 1
if sum(V)<=W: # v中的物品都可以放进去。
return 2**len(V) # v中的每个物品有两种情况
if V[0]<=W: # 开始递归
return count(W-V[0], V[1:]) + count(W, V[1:]) # 放或者不放
else:
return count(W, V[1:]) # 放不下
print(count(W,V))阿里笔试题:
12.x∈[1,A],y∈[1,B],x和y都是整数,找出这样的两个整数 x/y = a/b,且xy乘积最大。系统输入A,B,a,b。
思路:使用暴力的两重循环或者一重循环在资源限制下无法通过,只有使用数学的方法来去求解。首先需要对a/b进行约分,找到他们的最大公约数,使用辗转相除法。化简后为a1,b1,由于要使得x/y = a1/b1,即x = ka1,y = kb1,此时a1,b1已知,需要找到满足条件得最大的k,用A去除以a取整求得A中能得到的的最大k1,用B去除以b取整求得B中能得到的最大k2,为了相满足在范围内,取min(k1,k2)得到k。求出x,y。O(1)&O(1)
def compute(m, n):
if not n:
return m
else:
return compute(n, m % n)
def get_max(m,n,a,b):
num = compute(a,b)
a //= num
b //= num
k = min(n//b,m//a)
x = k*a
y = k*b
return str(x)+' '+str(y)
temp = list(map(int,input().split()))
if len(temp) == 4 :
s = get_max(temp[0],temp[1],temp[2],temp[3])
print(s)
2020/08/28 京东笔试题
13.一个三角形二维数组,小球从最上层中间进入,每次可以向下、左下或右下移动一格,求小球滚到最底部时最大的积分总和。
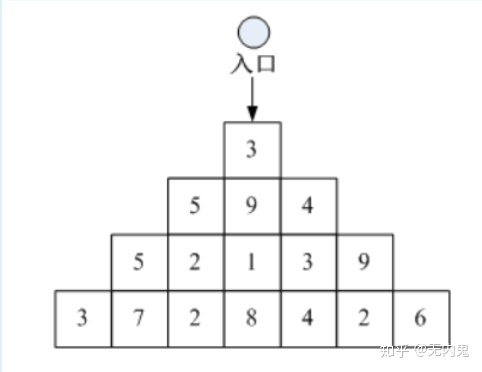
接受到这个数组,用strip()去掉前后的空格,发现每次移动,横坐标要么不变,要么+1,要么+2,而纵坐标显然每次向下移动+1
![]()
计算之前要先判断j, j-1, j-2是否越界,只计算不越界的。
def method(nums):
if nums==0:
return 0
game = []
for _ in range(nums):
game.append(list(map(int, input().strip().split())))
for i in range(1, nums):
for j in range(len(game[i])):
item_1 = game[i-1][j] if 0<=j<(2*i-1) else 0 # 过滤越界的
item_2 = game[i-1][j-1] if 0<=(j-1)<(2*i-1) else 0
item_3 = game[i-1][j-2] if 0<=(j-2)<(2*i-1) else 0
game[i][j] += max((item_1,item_2,item_3)) # 状态转移方程
return max(game[-1]) # 自上而下,找到最后一行最大的
if __name__ == '__main__':
nums = int(input().strip())
res = method(nums)
print(res)
2020/09/05 B站
14.现有N条鱼,A数组记录每条鱼的体积,每轮执行一次大鱼吃小鱼,对于每条鱼,它在每次操作时会吃掉右边比自己小的第一条鱼,在一次操作中,每条鱼吃比自己小的鱼的时间是同时发生的,比如[5,4,3],一次操作后,剩下[5]。求最多的可以操作的次数。
n = eval(input())
fish = list(map(int, input().split()))
fish.append("#") # 在尾部增加哨兵
stack, cnt, pre = [], 0, len(fish) # stack存储可以一组可以大鱼吃小鱼的鱼,pre用于判断是否变化
while fish:
if fish[0] == "#": # 一次操作后,首位为哨兵
fish.append(fish.pop(0)) # 将哨兵放到后面去
if len(fish) == pre:
break
else:
pre = len(fish)
cnt += 1
stack.append(fish.pop(0))
while fish[0] != "#" and int(stack[-1]) > int(fish[0]): # 将小鱼放入stack
stack.append(fish.pop(0))
fish.append(stack.pop(0)) # 提取stack中吃完后的大鱼到fish中,准备下一次操作。
while stack: # 清空stack,其他鱼被吃掉。
stack.pop()
print(cnt)
15.寻找公共最长子串,动态规划,dp[i][j]为分别以s1[i],s2[j]结尾的相同子串的长度,额外添加一行一列“0”方便初始化。求出相同子串的长度和结尾的位置,然后在s1中去切片出来。
str1 = input()
str2 = input()
def func(s1,s2):
res = ''
s = 0 # 记录最长的长度
p = 0 # 记录最长长度的结尾位置
dp = [[0 for _ in range(len(s2)+1)]for _ in range(len(s1)+1)] # 1.定义好状态
i = 0
while i<len(s1)+1: # 2.初始化
dp[i][0] = 0
i+=1
j=0
while j<len(s2)+1:
dp[0][j] = 0
j+=1
i = 1
while i < (len(s1)+1):
j=1 # 一行一行的比较
while j<len(s2)+1:
if list(s1)[i-1] == list(s2)[j-1]: # 3.状态转换方程
dp[i][j] = dp[i-1][j-1]+1
if dp[i][j]>s: # 寻找最长长度和位置
s = dp[i][j]
p = i
else:
dp[i][j] = 0
j+=1
i+=1
i = p - s # 逆向求出起始位置
while i <p:
res += list(s1)[i]
i+=1
return res
a = func(str1,str2)
print(a)
寻找最长公共子序列,与最长公共子串的区别是,不需要保证相同字符的连续性。同样也是使用dp。
"""
"helloworld" "loop"->3
"""
s1 = list(input())
s2 = list(input())
dp = [[0 for _ in range(len(s1)+1)]for _ in range(len(s2)+1)] # 状态转移矩阵初始化
for i in range(1,len(s2)+1):
for j in range(1,len(s1)+1):
if s2[i-1]==s1[j-1]: # dp中存储的是以i,j为结尾的字符串中最长的公共子序列的长度
dp[i][j] = dp[i-1][j-1]+1
else:
dp[i][j] = max(dp[i-1][j],dp[i][j-1]) # 状态转移方程
print(dp[-1][-1])
16.斜对角线打印矩阵,按照副对角线的走向打印。
"""
1 3 6
2 5 9
4 8 11
7 10 12 m = 4, n = 3
可以看出每条对角线的起始元素的横坐标变化:先增大,翻转后一直为m-1。纵坐标先一直为0,反转后增大。
"""
m,n = map(int,input().split())
res = [[0 for _ in range(n)] for _ in range(m)]
s = 1
def func(res):
start = 0 # 记录翻转时刻,如在7的位置,即m-1,后面每条对角线的起始元素的横坐标都为m-1
global s
for j in range(n): # 控制输出下半部分,列值一直增大。
for i in range(start,m): # 此时纵坐标为0,行值一直增大,控制上半部分
i1,j1 = i,j
while i1 >= 0 and j1<=n-1: # 打印每条对角线上的元素
res[i1][j1] = s
s +=1
i1-=1
j1+=1
if i == m-1 and j == 0: # 纵坐标为0下,横坐标增大到m-1翻转后面i一直定于m-1
start = m-1
return res
func(res)
print(res)
17.走出迷宫最少的步数,使用dfs。
maze=[[1,1,1,1,1,1,1,1,1],
[1,0,0,1,0,0,1,0,1],
[1,0,0,1,1,0,0,0,1],
[1,0,1,0,1,1,0,1,1],
[1,0,0,0,0,1,0,0,1],
[1,1,0,1,0,1,0,0,1],
[1,1,0,1,0,1,0,0,1],
[1,1,0,1,0,0,0,0,1],
[1,1,1,1,1,1,1,1,1]] # 迷宫,1为障碍
a,b,c,d = 3,1,5,7 # 起点与终点坐标
s,m = 0,float('inf') # s缓存步数,m缓存最小值。
def dfs(x,y,s):
global m
if maze[x][y] :return # 递归终止条件
if x==c and y==d:
m = min(s,m)
return
s+=1
maze[x][y] = 1 # 递归处理
dfs(x+1,y,s) # 继续递归
dfs(x,y+1,s)
dfs(x-1,y,s)
dfs(x,y-1,s)
maze[x][y]=0 # 此问题需要回溯
dfs(a,b,s)
print(m)
18.输入n组特征进行排列组合,注意输出的顺序。时间O(nm),后一特征在前一特征被遍历完后才变化。DFS

n = int(input())
tmp,res = [],[]
for _ in range(n):
list1 = list(input().split())
tmp.append(list1) # 接收特征
cur = [] # DFS搜索,缓存结果,根据观察,最后一个特征变化较慢,第一个特征变化较快。从后往前搜索。
def dfs(cur,i):
if i == -1: # 搜索到第一个特征
a = []
a = a + cur
res.append(a) # 由于append(cur)是浅拷贝,cur后面还会变化,故用a来获取cur值
return
for j in range(len(tmp[i])):
cur.append(tmp[i][j]) # 压入cur栈
dfs(cur,i-1)
cur.pop() # 进行回溯
dfs(cur,n-1)
for i in range(len(res)):
print("-".join(res[i][::-1])) # 由于从后往前搜,res中的结果为倒序。19.字符串中,长度大于1的子回文字符串的个数。dp。
s = input()
if len(s) <= 1:print(0)
n = len(s)
tmp = list(s)
dp = [[0 for _ in range(n)]for _ in range(n)] # dp数组,起始位置和结束位置所组成字符串状态
sum = 0
for i in range(n): # 将单个字符标记为是
dp[i][i] = 1
for j in range(1,n): # j为结束位置,i为起始位置
for i in range(0,j):
if s[i] == s[j] and (i == j-1 or dp[i+1][j-1]): # 上一状态或者已经相邻
dp[i][j] =1
sum +=1
print(dp)
print(sum)
20.检查图是否为有向无环图,可以使用bfs,dfs。课程表安排图。BFS:如果按照BFS遍历,遍历一次入度减1,还是存在入度不为0,则存在环。DFS:按照DFS遍历,被遍历过的课程置为-1,本轮访问的置为1,初始化为0,再次访问本轮访问的点,即为有环。
from collections import deque # 引入双端队列作记录预先课程学完,可以学习的课程。
class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
indegrees = [0 for _ in range(numCourses)] # 入度表,记录每门课需要预学习的课程数量
adjacency = [[] for _ in range(numCourses)] # 图的邻接表,记录连接
queue = deque()
for cur, pre in prerequisites: # cur为当前课程,pre为需要预学习的课程
indegrees[cur] += 1 #
adjacency[pre].append(cur)
for i in range(len(indegrees)): # 让入度为0的课程进入代表可以学习的queue
if not indegrees[i]: queue.append(i)
while queue:
pre = queue.popleft() # 代表pre这门课程入度为0,已经学习了
numCourses -= 1
for cur in adjacency[pre]:
indegrees[cur] -= 1
if not indegrees[cur]: queue.append(cur)
return not numCourses
21.全排列,时间O(n*n!),递归
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
"""
1.递归这种题一定要把问题简单化,不能复杂化,用两位或三位的nums想问题。
2.全排列是位与位交换的问题。
3.如1,2,3,4. 先把1固定,递归地求2,3,4的全排列,又把2固定,递归地求3,4的全排列……直到剩一个数,输出这个排列
"""
def func(first):
if first == n: # 递归终结的情况,处理,下一步递归,回溯
res.append(nums[:])
for i in range(first,n):
nums[first],nums[i] = nums[i],nums[first] # 假设只有两位或者三位的nums;
func(first+1)
nums[first],nums[i] = nums[i],nums[first]
n = len(nums)
res = []
first = 0
func(first)
return res22.零钱兑换,动态规划。时间O(Sn),S为金额,n是零钱面额数量。空间O(S)。
class Solution:
def coinChange(self, coins: List[int], amount: int) -> int:
dp = [float('inf')] * (amount + 1) # dp数组存储相应金额所需的最少硬币数量
dp[0] = 0 # 0元所需0个硬币
for i in range(1,amount+1): # 填满dp每个状态
for j in coins: # 每个状态下遍历零钱面额,寻找最少的情况
if j <= i: # 面额小于当前状态金额时
dp[i]=min(dp[i],dp[i-j]+1) # 初始为"inf"
if dp[amount] == float('inf'): #如果目标金额没有改变,说明无法兑换。
return -1
else:
return dp[amount]
23.求图的连通子图的个数并保存每个子图的节点:https://www.cnblogs.com/sunupo/p/13510172.html
24.字符串是否由子串拼接,遍历每一种情况
"""
abcabc->abc;
"""
def copy(s):
if len(s)<2:
return s
res = ""
for i in range(1,len(s)//2+1): # 寻找能拼接的子串,最长为长度的一半
ss = s[:i] # 遍历所有情况
if is_copy(ss,s):
res = ss
return res if res else 'false'
def is_copy(ss,s):
i = len(s)//len(ss)
if len(s)%len(ss) != 0:
return False
if ss*i == s: # 由i次重复构成
return True
else:
return False
s = input()
print(copy(s))25.整数乘积最大化,动态规划,dp数组中存储当前情况下最大的乘积。
"""
10=3+3+4->36
"""
def main():
n = int(input())
dp = [0 for _ in range(n + 1)]
dp[0] = 0
dp[1] = 0
dp[2] = 1
for i in range(2, n + 1):
for j in range(2, i):
dp[i] = max(dp[i], j * max(dp[i - j], i - j))
return dp[n]
print(main())26.奖牌榜排序,输入信息为国家名和金银铜奖牌数量,按照相应奖牌数量等排序。
import sys
M = int(input()) # number
if M>=31 or M<=0:
print("参赛国家数量不正确,范围应在(0,31)中!")
sys.exit()
country = []
flag = 0
for i in range(M):
temp = list(input().split())
if len(temp)!=4:
print("输入参赛国奖牌信息有误!应包含国名,金银铜牌数量四个信息。")
flag = 1
break
if len(temp[0])>20:
print("输入的国家名称数量超过了20个字符!")
flag = 1
break
for j in range(3):
if not(int(temp[j+1]) in range(0,201)):
print("输入的奖牌数量不正确!")
flag = 1
if flag:break
country.append(temp)
# 按国家首字母排序
country.sort(key=lambda x: x[0])
# 按铜牌数量排序
country.sort(key=lambda x: int(x[3]), reverse=True)
# 按银牌数量排序
country.sort(key=lambda x: int(x[2]), reverse=True)
# 按金牌数量排序
country.sort(key=lambda x: int(x[1]), reverse=True)
if flag == 0:
for i in range(M):
print(country[i][0])


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









