






 本文介绍了一种优化的网页爬虫实现方法,通过改进球员信息爬取流程提高效率。采用多浏览器并发爬取策略,并利用正则表达式处理乱码问题,确保数据准确性。文章还讨论了异常处理和信息存储技巧。
本文介绍了一种优化的网页爬虫实现方法,通过改进球员信息爬取流程提高效率。采用多浏览器并发爬取策略,并利用正则表达式处理乱码问题,确保数据准确性。文章还讨论了异常处理和信息存储技巧。
挖了个坑,总是要填上比较好。
刚开始做时的思路是:
(1)获取排名页球员列表,遍历列表selenium模拟点击进入球员链接
(2)获取球员详细信息
(3)浏览器后退返回排名页,翻页回到上一次抓取的页数
(4)继续进入下一个球员链接或者翻页继续执行相同操作
这种方法缺点是进到球员页面获取完信息后浏览器后退会返回第一页,所以需要记录下当前爬取到第几页,然后翻到那一页继续进行爬取,效率相当慢并且还要确保浏览器不出问题的情况下才能完整爬下来(点击下一页时经常没反应,需要刷新页面然后又从第一页开始翻页……)
然后换个思路吧:
(1)同样必须要点击翻页,但是不进入球员页面,而是把每页的球员链接先存储下来
(2)将球员链接分成两部分,一部分使用Chrome浏览器,另一部分使用Firefox浏览器
(3)遍历这些链接去获取信息,每一个链接爬取完后就关闭浏览器,下一个链接再重新打开
这样速度快很多而且每个链接都是单独获取,即使出问题也不会影响前面的操作
主要步骤:
1、每页只显示10名球员链接,模拟点击翻页获取每个球员的链接并存储到本地
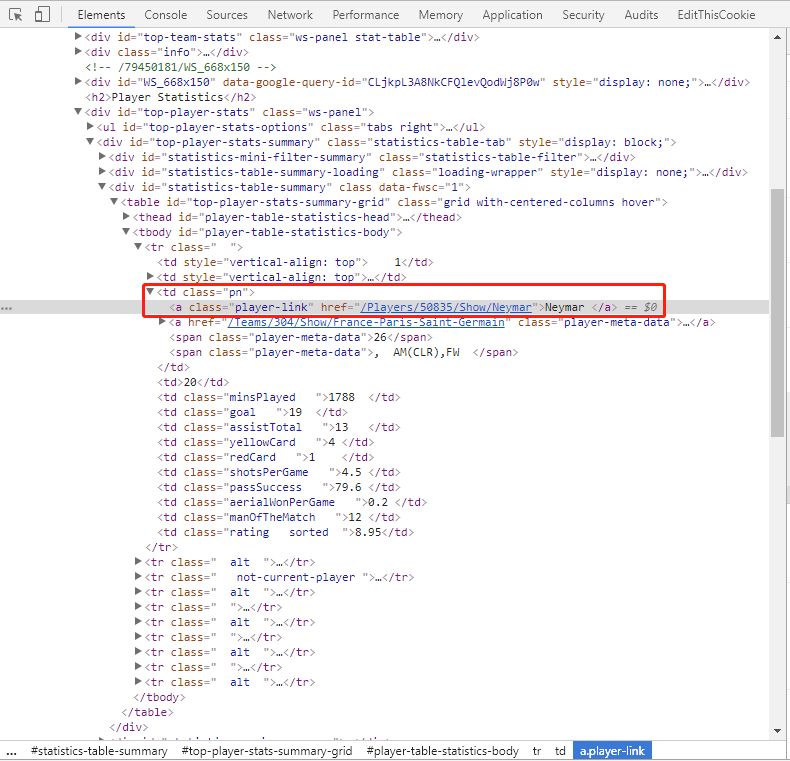
2、读取球员链接文件,有的链接球员姓名会有乱码的,跟第一列替换一下就好了,然后将这些链接分成两部分,一部分用Chrome浏览器,一部分用Firefox浏览器
wb = openpyxl.load_workbook('playersurl.xlsx')
ws = wb.active
player_list = []
for r in ws.iter_rows(min_row=2):
player = []
for cell in r:
player.append(cell.value)
player_list.append(player)# print(player_list)
for p in player_list:
# print(re.search('(?<=Show\/).*',p[1]))
# 网址最后名字会有乱码,用名字替换
p[1] = re.sub('(?<=Show\/).*', p[0], p[1])
print(player_list)
browser_url = {}
browser_url['Chrome'] = []
browser_url['Firefox'] = []
for i, p in enumerate(player_list):
if i < 723:
browser_url['Chrome'].append(p[1])
else:
browser_url['Firefox'].append(p[1])
print(browser_url)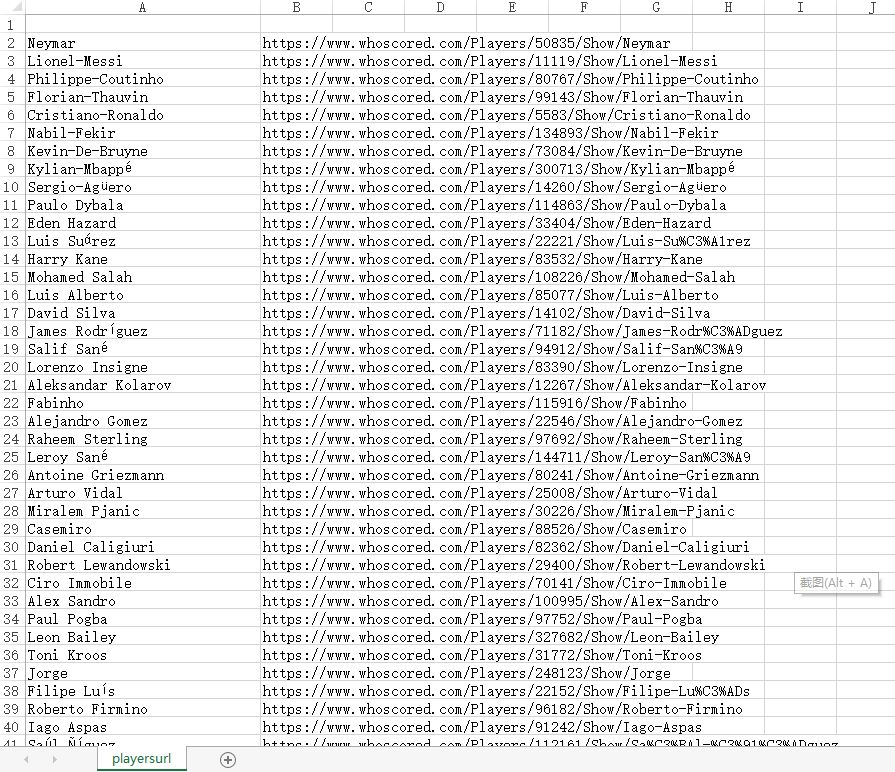
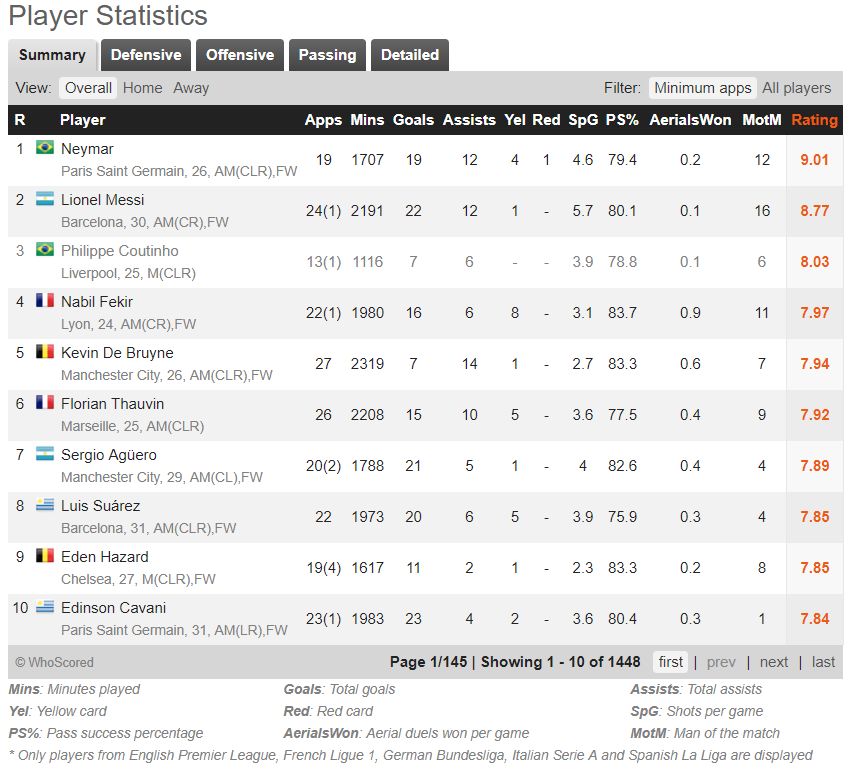
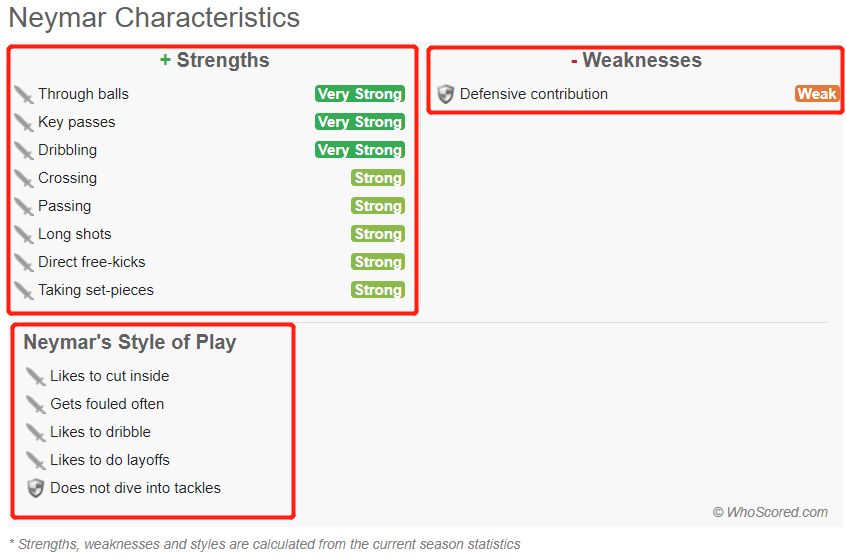
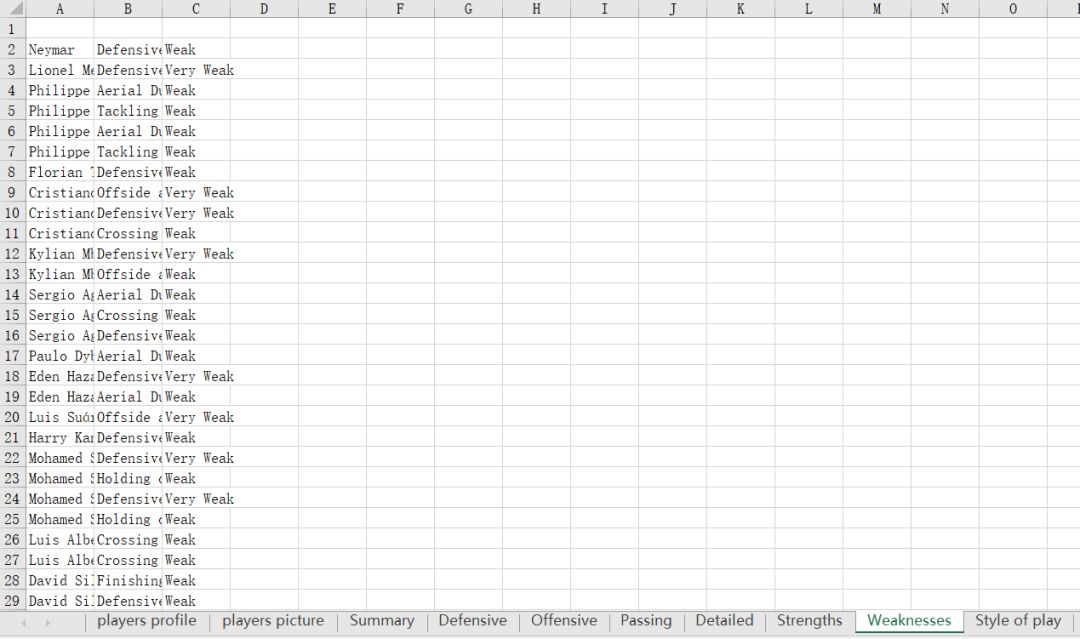
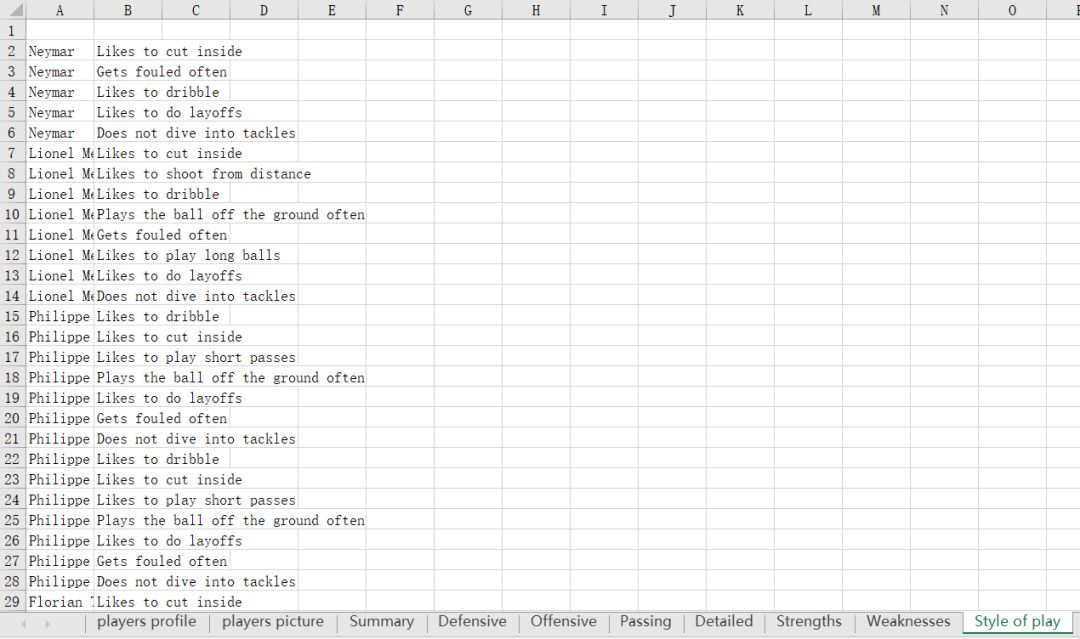
3、每个球员要获取的信息就是下面这些啦~有球员简介,球员参赛情况(summary,Defensive,Offensive,Passing,Detailed),球员强项,弱点,特点,数据存进excel表里,一共有10个sheet
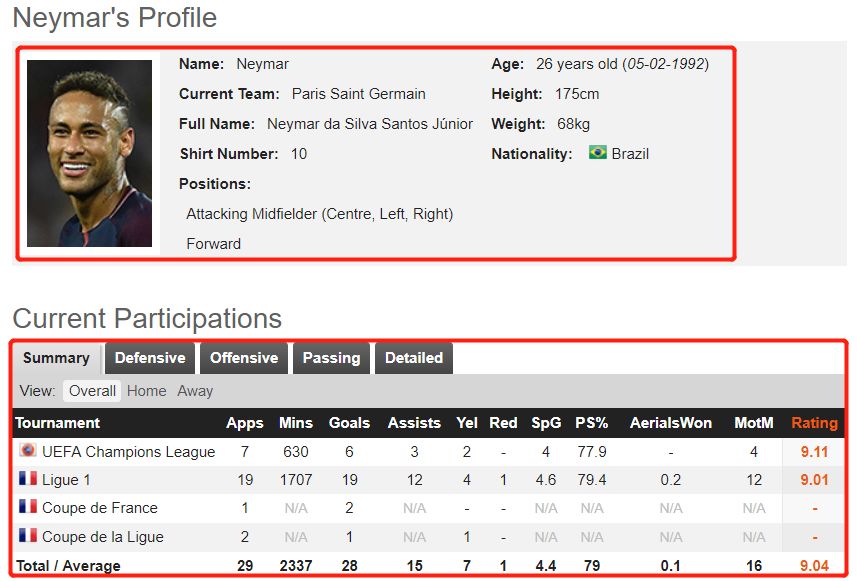
4、爬取过程中要写个while True…try…except…else的循环,也要记录下当前爬取到第几个链接,目的是当浏览器打不开页面或者获取不到页面信息等等的报错后还能回到出问题的这个链接继续爬取
while True:
try:
for b, url in browser_url.items():
if b == 'Firefox':
for index, url in enumerate(url):
if index < url_index:
continue
else:
browser = webdriver.Firefox()
browser.get(url)
get_player_information()
url_index = index
except Exception as e:
print(e)
print('打开浏览器错误')
print(url_index, url)
try:
browser.close()
except Exception as e:
pass
else:
break
5、要注意的是获取球员参赛情况时每次点击后都要设置time.sleep(),5~15秒左右,不然当前页面还没加载完就已经跳转到下一个页面或者爬不来的信息不对,另外如果当前在爬的链接如果出问题了,可能会重复获取上一个链接的球员信息,这里没有做一个去重的处理,最后爬下来的信息也还需要做一些整理
结果:

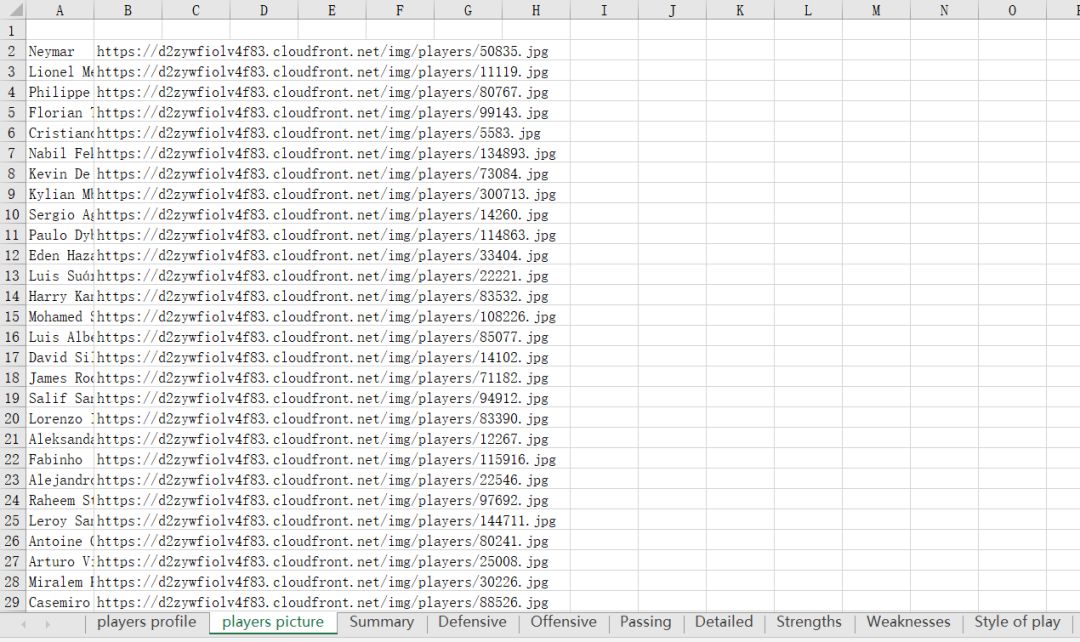
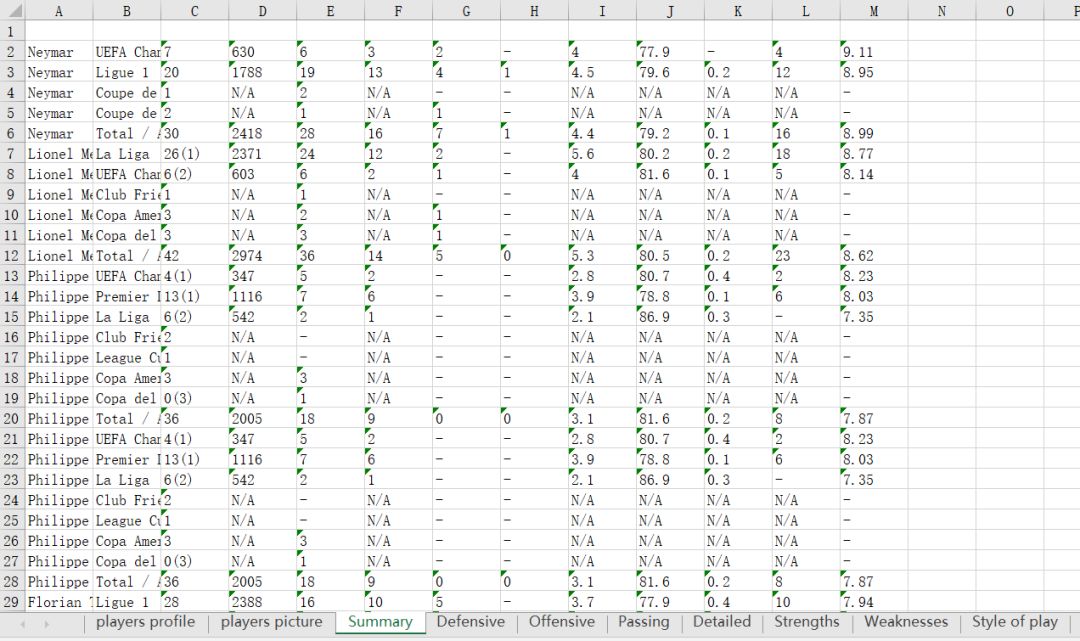
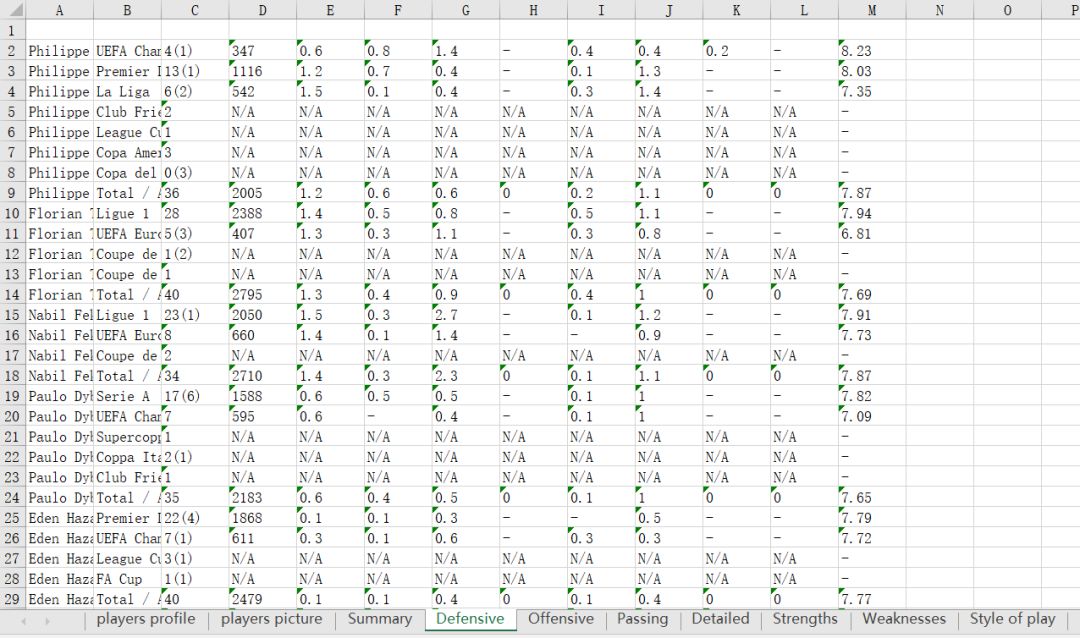
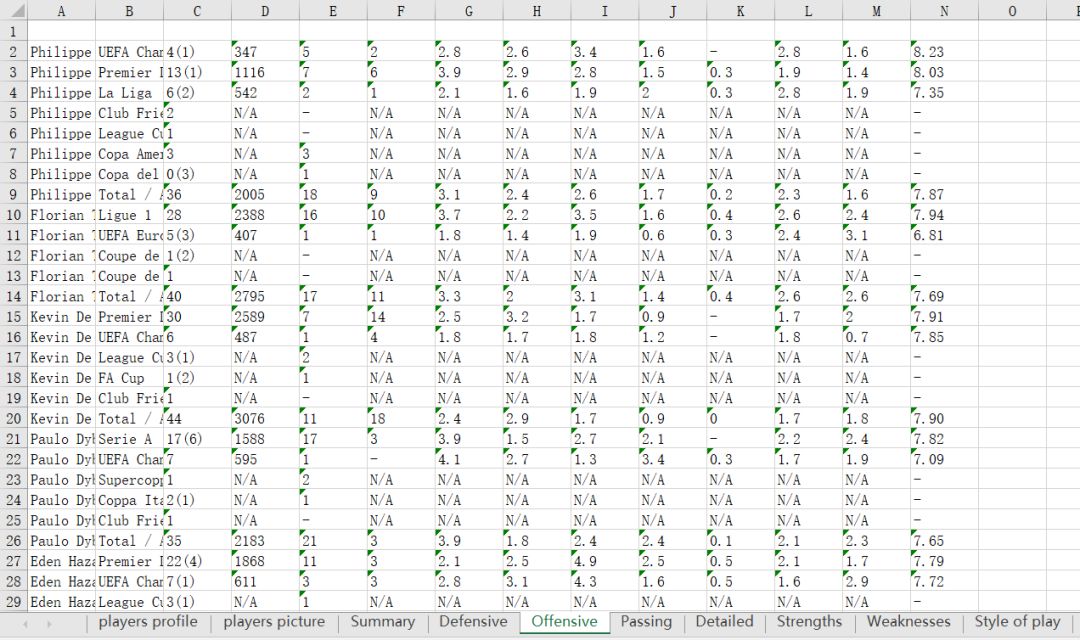
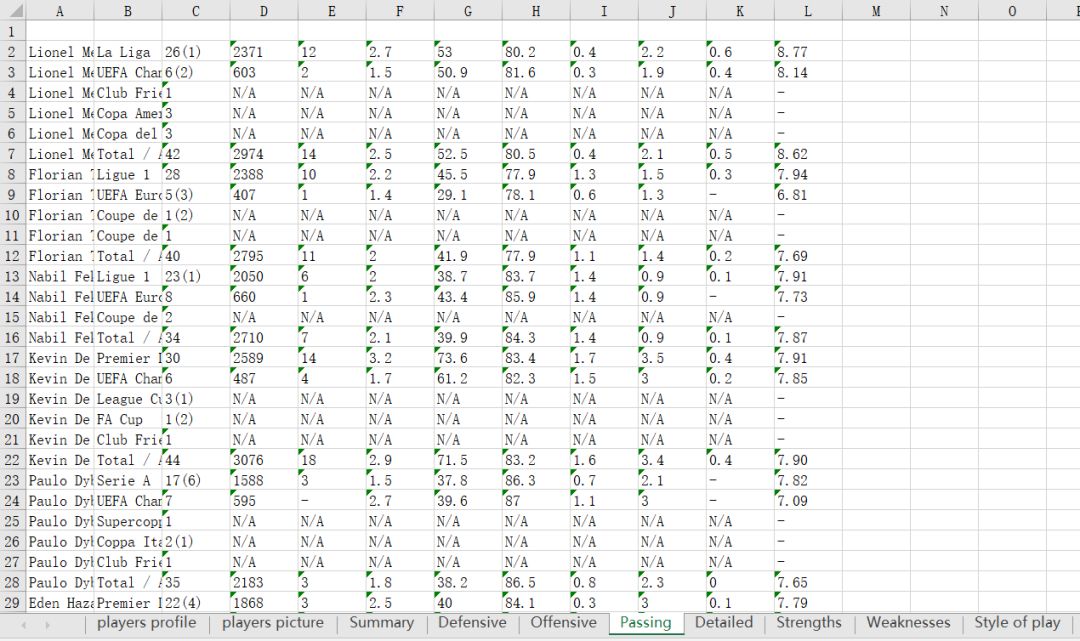
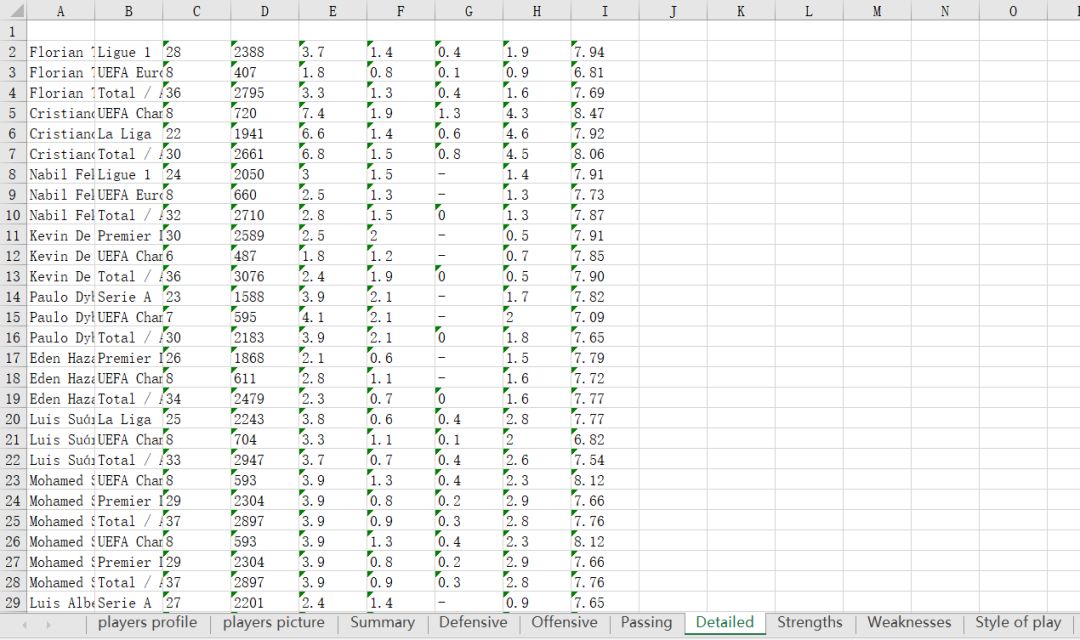
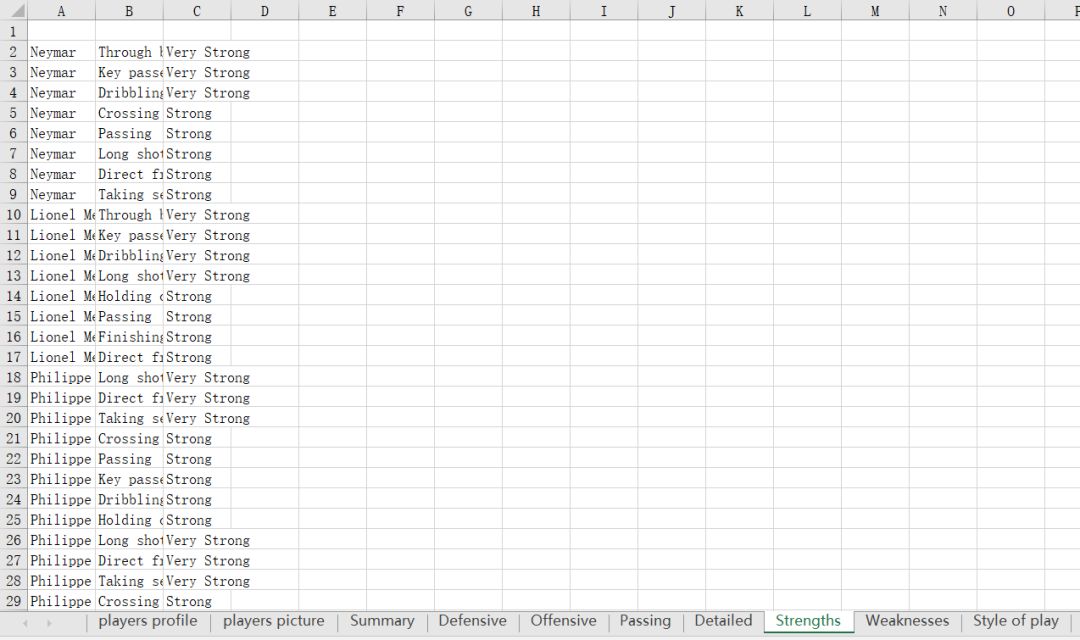

关注公众号获取个人分享的资源以及了解更多详情

















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









