







DNN深度神经网络,包括:CNN(要讲全连接层等),RNN,GAN(非监督学习),DBN
https://blog.youkuaiyun.com/qq_24690701/article/details/81868048
1.DNN,深度神经网络,或多层神经网络,或多层感知机(Multi-Layer perceptron,MLP),
参考链接:http://www.6ke.com.cn/seoxuetang/kj/2019/0802/10972.html
可以理解为有多个隐藏层的神经网络
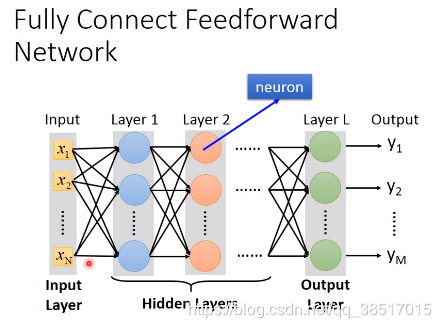
这是一个全连接的神经网络,前一层的一个神经元会和下一层的每一个神经元都有连接
2.CNN(c代表convolutional),卷积神经网络
CNN以一定的模型对事物进行特征提取,而后根据特征对该事物进行分类、识别、预测或决策等。
CNN是end-to-end端到端学习,直接让神经网络学习如何从原始输入得到期望结果,不需要人工参与其中类似特征提取的步骤。
CNN结构:
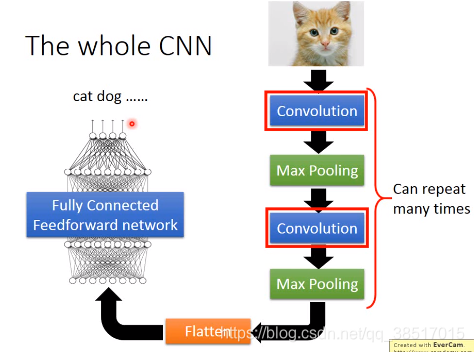
convolution和pooling层的作用:
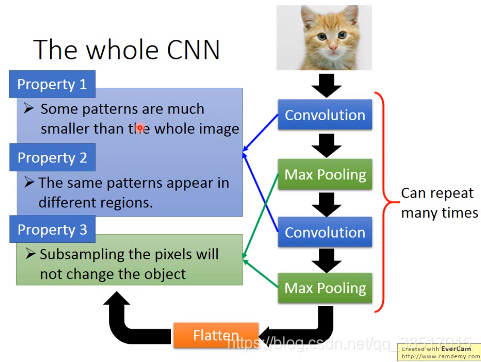
卷积层作用:有些特征占很小部分,不用处理整张图片;不同区域的相同特征可以看成一个特征
池化层:不改变目标图进行下(降)采样
(1)输入层
可直接将图片作为输入,输入的是二维数组,每个元素是代表一个像素点
对于黑白图片,只用输入一个二维数组;对于有颜色的RGB图片,需要输入三个二维数组,分别对应R通道、G通道和B通道
(2)卷积层
卷积:一个filter(一个矩阵)覆盖在图片上,和对应元素相乘后再累加得到一个位置的值,然后filter向后移动若干元素,再相乘累加得到下一个元素,不断重复此过程
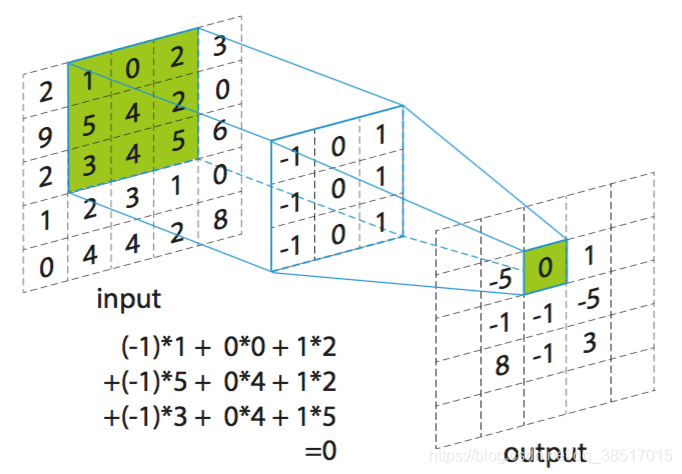
卷积层需要挑好filter,一般为331、551(对于RGB图,为333,553)等;然后确定步长,即每次filter移动几个单元
padding:图像边缘补充,一般填0,要不然边界特征全部丢掉了
注意:可能会有多个filter对输入矩阵进行卷积,得到多个特征图(这多个特征图如何使用见flattern层);另外,filter的值是由网络自己学出来的
(3)池化层
池化层是进行降采样操作:在一个小区域内,采取一个特定的值作为输出值。
池化层不会改变矩阵的深度,但是它可以缩小矩阵的大小,也可以进一步减少全连接层的节点数,从而减少整个神经网络的参数个数
max pooling:每一组找最大值输出(最常用)
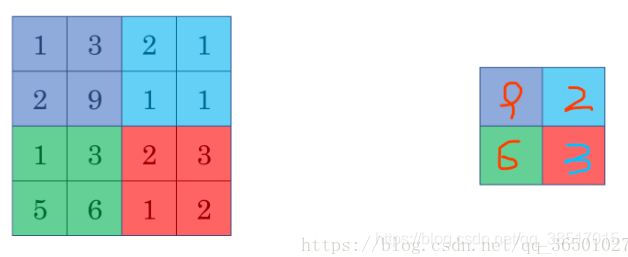
average pooling:每一组输出平均值
(4)全连接层
全连接层前有一个flattern操作:把多个二维数组中的元素拿出来拉直排成一列再作为全连接层的输入。
如果说卷积层、汇合层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的特征表示映射到样本的标记空间的作用,即起到分类器的作用
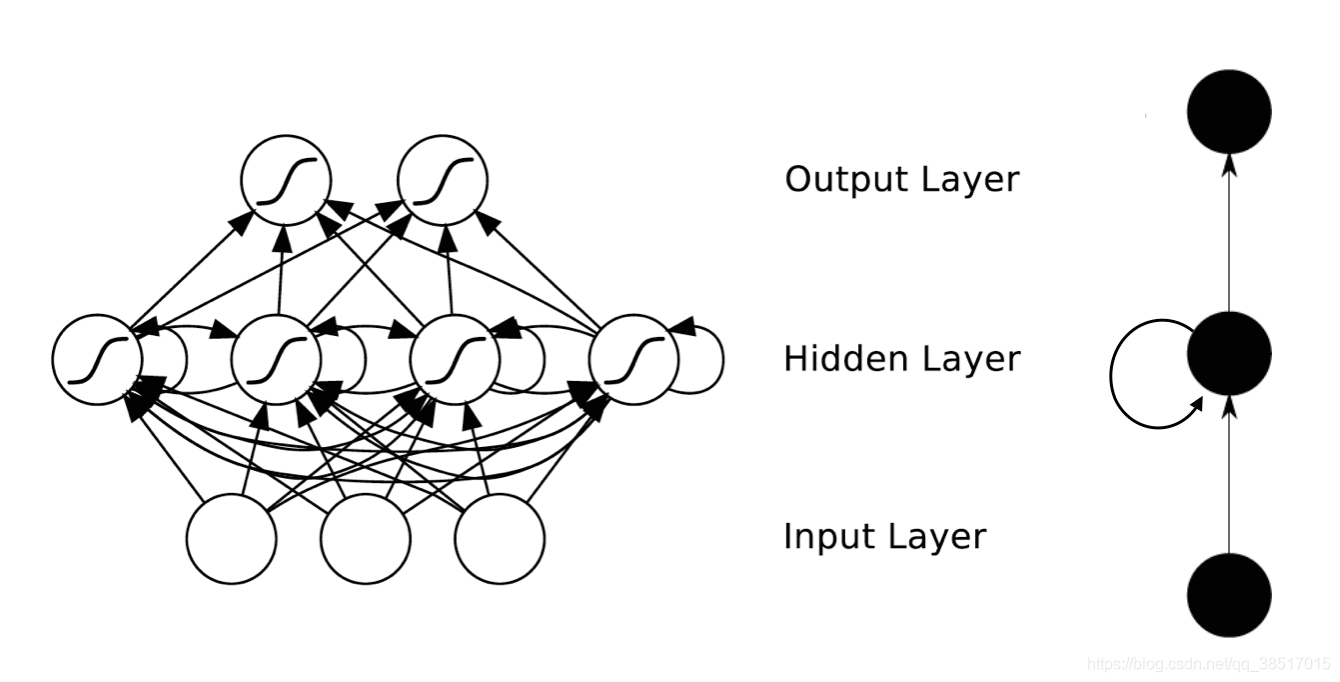
3.RNN(R代表recurrent),循环神经网络
(1)RNN经典结构图
循环展开的内部结构
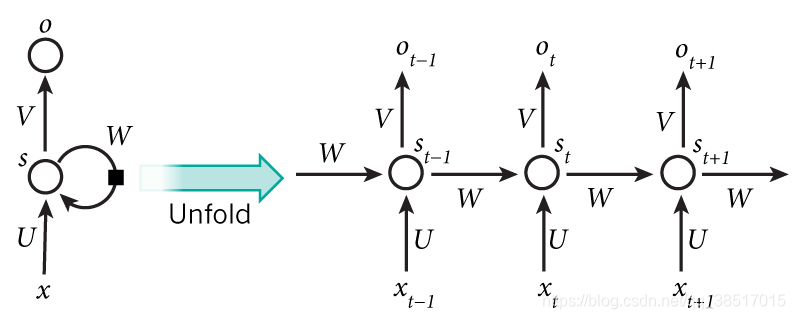
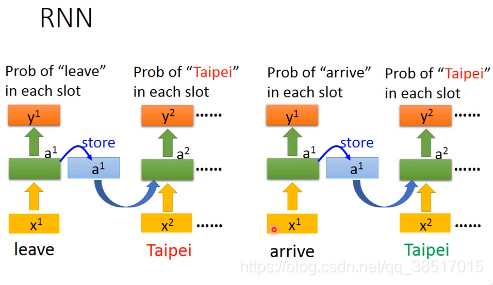
简单理解:RNN是有记忆的网络,这一时刻的输出不仅跟这一时刻的输入有关,还跟上一时刻的输出有关;注意每个时刻用的是同一个网络,同一个网络多次重复使用即循环
e.g.通过上一个单词leave/arrive判断这个单词Taipei是出发地还是目的地
(2)分类一:LSTM long short-term memory比较长的短期记忆
LSTM靠一些“门”的结构让信息有选择性地影响循环神经网络中每个时刻的状态
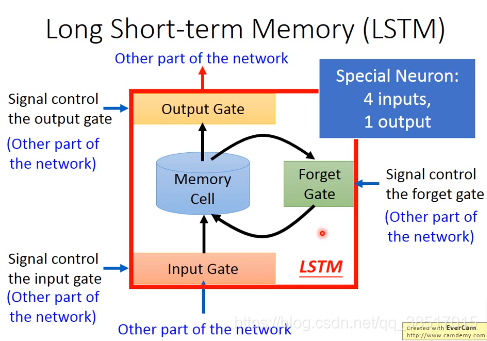
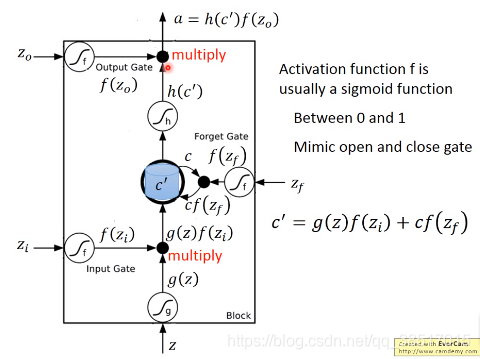
z是要写入的值,a是读出的值
这个memeory cell可以读出也可以写入,由三个门控制
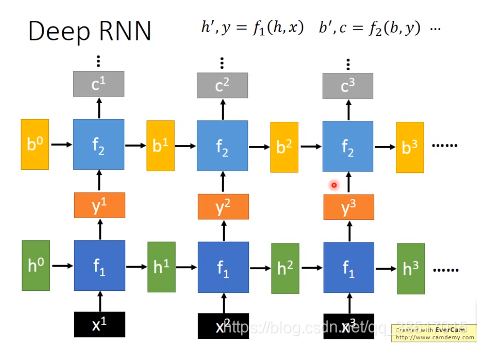
(3)分类二:DEEP RNN
横向是每个时刻之间的传递过程,纵向是深度,网络功能更强大
4.GAN( Generative adversarial network),生成对抗网络
链接:https://www.cnblogs.com/bonelee/p/9166084.html
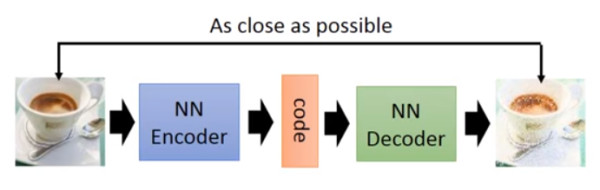
训练一个Encoder,把输入转化成一个code,然后训练Decoder从输入的code得到一个输出,把输出与输入比较作loss函数;然后拿出decode,随便输入一个code,就可以得到一个输出,但是效果不是很好
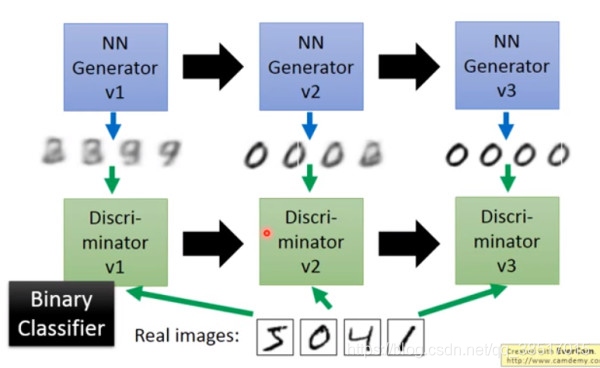
GAN:
首先,有一个一代的 generator,它能生成一些很差的图片,然后有一个一代的 discriminator,它能准确的把生成的图片,和真实的图片分类,简而言之,这个 discriminator 就是一个二分类器,对生成的图片输出 0,对真实的图片输出 1。
接着,开始训练出二代的 generator,它能生成稍好一点的图片,能够让一代的 discriminator 认为这些生成的图片是真实的图片。然后会训练出一个二代的 discriminator,它能准确的识别出真实的图片,和二代 generator 生成的图片。以此类推,会有三代,四代。。。n 代的 generator 和 discriminator,最后 discriminator 无法分辨生成的图片和真实图片,这个网络就拟合了。
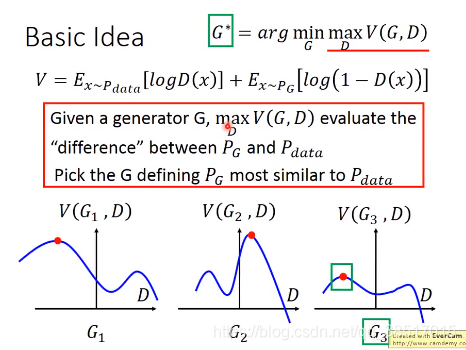
GAN具体的训练步骤:
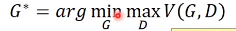



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









