







BUG: ValueError: The model’s max seq len (32768) is larger than the maximum number of tokens that can be stored in KV cache (1152).
环境
linux
python 3.10
torch 2.1.2+cu118
vllm 0.3.3+cu118
xformers 0.0.23.post1
详情
使用vllm启动大模型出现的错误。
ValueError: The model’s max seq len (32768) is larger than the maximum number of tokens that can be stored in KV cache (1152). Try increasing gpu_memory_utilization or decreasing max_model_len when initializing the engine.
问题原因
大模型上下文长度max_model_len超出了所用显卡GPU的KV缓存限制。
解决方法
解决方法1:设置max-model-len或 gpu-memory-utilization
max-model-len 是设置模型支持的上下文大小,例如max-model-len=512,如果输入长度为1024,模型会报错。
我的 KV cache (1152) ,因此在启动命令最后加入:
#需要小于等于弹出错误声明的大小
--max-model-len 1152
# 如果gpu-memory-utilization 即占用gpu显存比例过少,可以适当增大
--gpu-memory-utilization 0.9
设置max-model-len为小于等于 KV cache 即可。
vllm正常启动后的样子

正常启动会输出访问的网址的。
解决方法2:取消使用KV cache
该方法适合想支持长上下文的情况。
方法是修改模型配置 config.json
例如 Qwen1.5-14B-Chat-GPTQ-Int8 大模型 KV cache 参数是 use_cache。
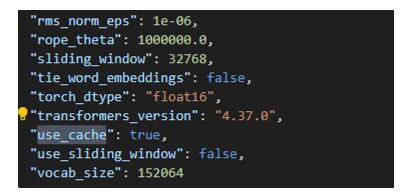
将 use_cache 设置为false即可
"use_cache": false
注意,不同大模型配置文件设置KV cache参数可能不一样。
考虑到显卡大小,应该考虑设置max-model-len小一些,例如设置为 4096。
KV cache 的作用是加速推理,但如果输入的长度不长和数量不多,我测试取消KV Cache 后速度没有太大差别。

















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









