




 本文介绍了如何使用Python进行简单的爬虫,针对数据样本不足的问题,特别是图像数据,通过爬取百度图片并按指定规则保存,以扩充计算机视觉(CV)项目的训练样本。
本文介绍了如何使用Python进行简单的爬虫,针对数据样本不足的问题,特别是图像数据,通过爬取百度图片并按指定规则保存,以扩充计算机视觉(CV)项目的训练样本。
实习的时候发现,有的时候某些类别的数据样本不太够,这时候就需要我们自己从其他渠道拿到这一类的样本,我这里的样本主要是指图片,因为我主要是做CV的。
Python的语法很简单,特别容易上手,也很适合拿来做爬虫。这里实现的功能就是,输入你要爬的图片的名称,然后通过百度图片爬取保存在本地文件夹中。
#!-*- coding:utf-8 -*-
# FileName : Web Crawler.py
# Author : Canran Lin
# Data : 2018/06/23
# 这个爬虫的作用就是:输入你想要爬的图片的名称,然后自动通过百度图片爬取保存在本地文件夹中
# 需要用到的模块:re(正则表达式),request,random
import re # 导入正则表达式模块
import requests # python HTTP客户端 编写爬虫和测试服务器经常用到的模块
import random # 随机生成一个数,范围[0,1]
# 定义函数方法
def CrawlerPic(html, keyword):
print('正在查找 ' + keyword + ' 对应的图片,下载中,请稍后......')
for addr in re.findall('"objURL":"(.*?)"', html, re.S): # 查找URL
print('正在爬取地址:' + str(addr)[0:40] + '...') # 爬取的地址长度超过40时,用'...'代替后面的内容
try:
pics = requests.get(addr, timeout=10) # 请求URL时间(最大10秒)
except requests.exceptions.ConnectionError:
print('您当前请求的地址出现错误')
continue
# 抓取的图片自动保存在本地文件夹并自动命名
fq = open('你想保存的文件夹的路径地址' + (keyword + '_' + str(random.randrange(0, 1000, 4)) + '.jpg'), 'wb') # 下载图片,并保存和命名
fq.write(pics.content)
fq.close()
# python的主方法
if __name__ == '__main__':
# "word"的作用就是接收你想要找的图片名称,然后拼接到“百度图片”的链接上
#
# 查看谷歌浏览器搜索栏百度图片“汽车”的链接
word = input('请输入你要搜索的图片关键字:')
result = requests.get(
'http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=' + word)
# 调用函数
CrawlerPic(result.text, word)
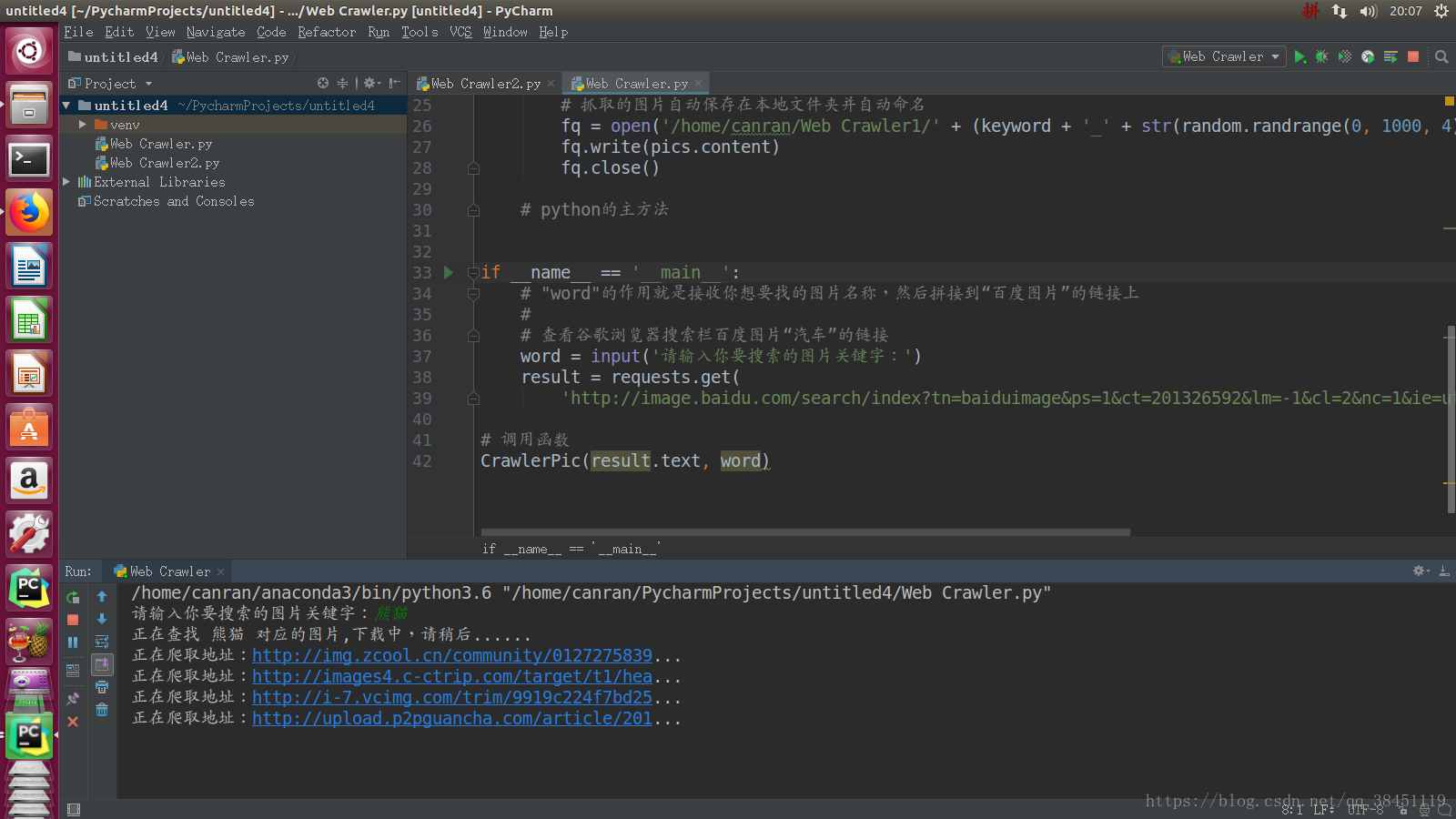
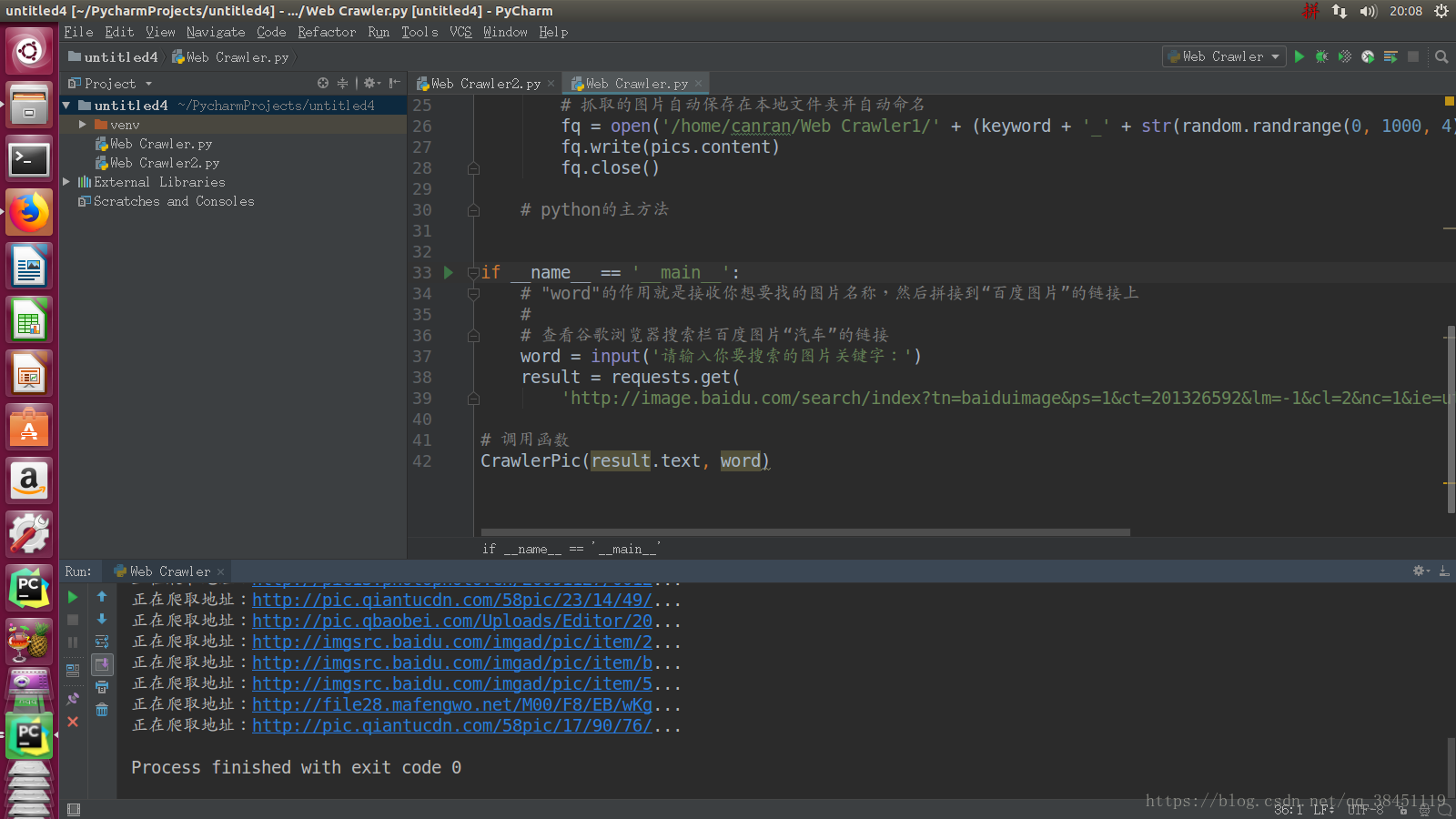

爬取到的图片会按照我们的命名规则来命名,并自动保存在我们的文件夹下。

















 1756
1756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









