







 本文介绍了Maven项目在构建过程中遇到的Nocompilerisprovidedinthisenvironment错误及其解决方法,通过正确配置JDK环境来避免此类问题。同时,文章还提到了因JDK版本不匹配导致的构建错误及解决方案。
本文介绍了Maven项目在构建过程中遇到的Nocompilerisprovidedinthisenvironment错误及其解决方法,通过正确配置JDK环境来避免此类问题。同时,文章还提到了因JDK版本不匹配导致的构建错误及解决方案。
1、Maven项目build时出现No compiler is provided in this environment的处理
Maven项目build时出现:
No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK?发现自己的java编译环境是![]() ,并没有配置成jdk目录,所以就需要配置为jdk
,并没有配置成jdk目录,所以就需要配置为jdk
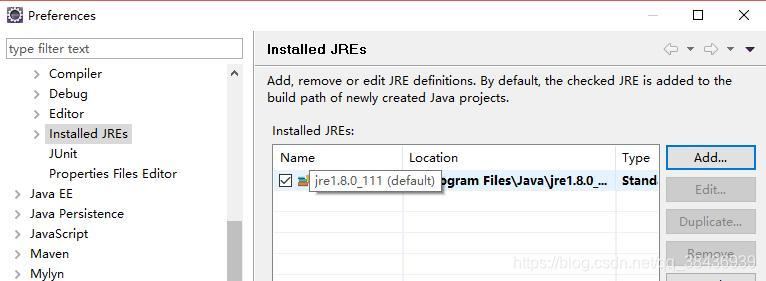
点击Add-->standard VM-->NEXT,选中JDK的目录,点击Finish

选中jdk的编译环境,点击Apply
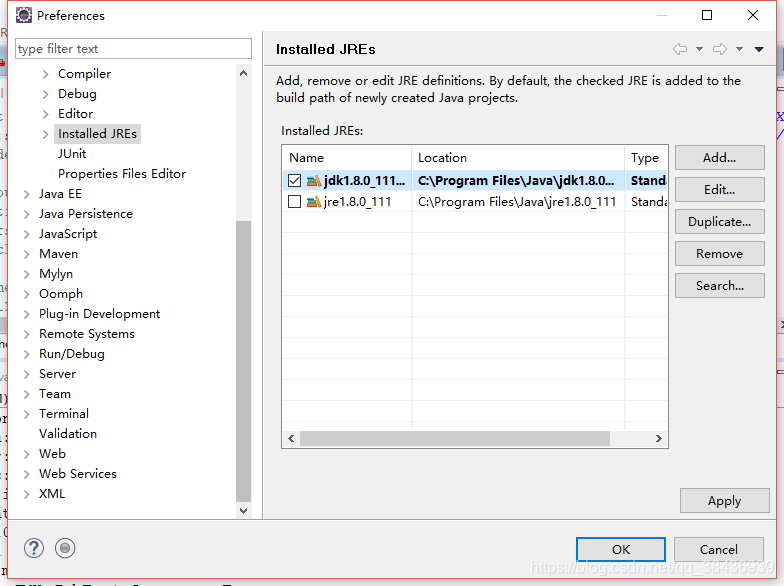
在该Maven项目,
![]()
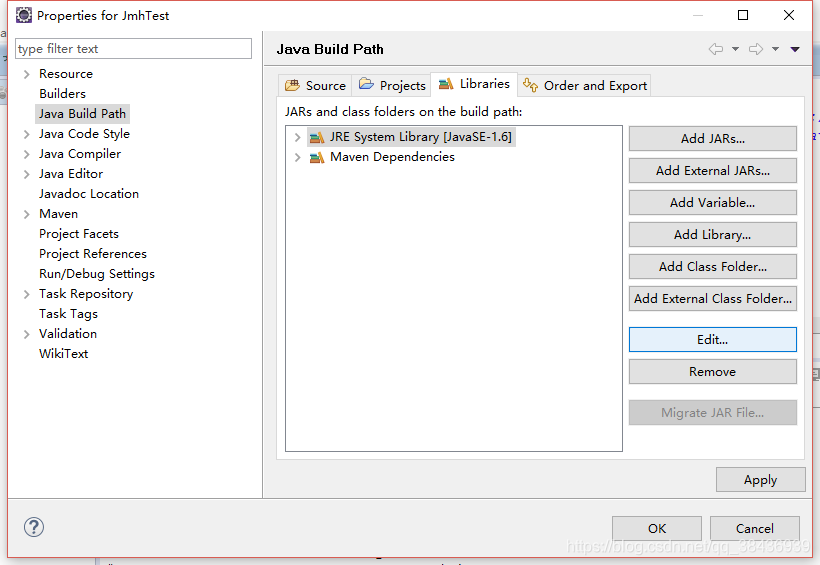
选中JRE System Library进行build path,点击Edit
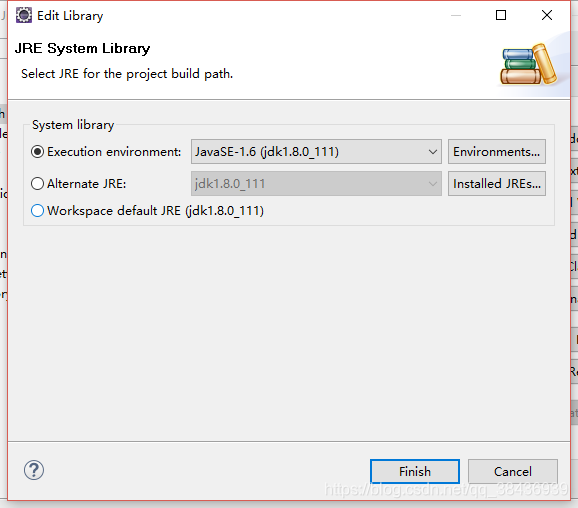
选择jdk的JavaSE,我的JavaSE-1.6为JDK,其他JavaSE-1.X为jre,我就选择了1.6,也可以选中高版本的,在Alternate JRE中选择jdk进行设置,设置完成后,重新进行maven clean install 步骤,可顺利解决该问题
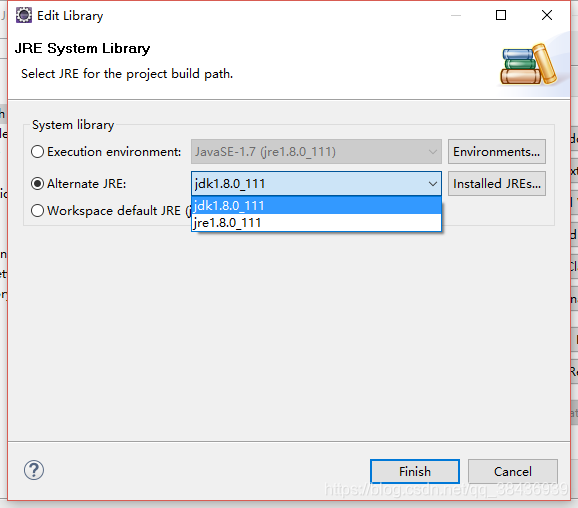
2、Maven项目build时出现问题,在build时出现的错误可能是jdk版本问题,更换一个更高版本的jdk就可以解决问题
总结:解决Maven问题关键在于查看maven install时出现的错误信息,根据错误信息提示寻找问题根源,你忽略掉的install时出现的ERROR可能会给你带来很大的麻烦,运行项目出错先去寻找install的ERROR信息,切勿盲目百度。
另外关于简单了解JRE和JDK的区别,可以去这个博客看一下https://blog.youkuaiyun.com/shaochenshuo/article/details/78507132

















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









