






 这是2018最新李宏毅深度学习学习笔记。探讨在相同精确度下,浅网络和深网络拟合函数的情况。以relu网络为例,证明浅网络参数足够多时能拟合目标函数,深网络可用更少参数做到,还介绍了浅网络拟合连续函数的方法。
这是2018最新李宏毅深度学习学习笔记。探讨在相同精确度下,浅网络和深网络拟合函数的情况。以relu网络为例,证明浅网络参数足够多时能拟合目标函数,深网络可用更少参数做到,还介绍了浅网络拟合连续函数的方法。
这是2018最新李宏毅深度学习的学习笔记
1-1_ Can shallow network fit any function
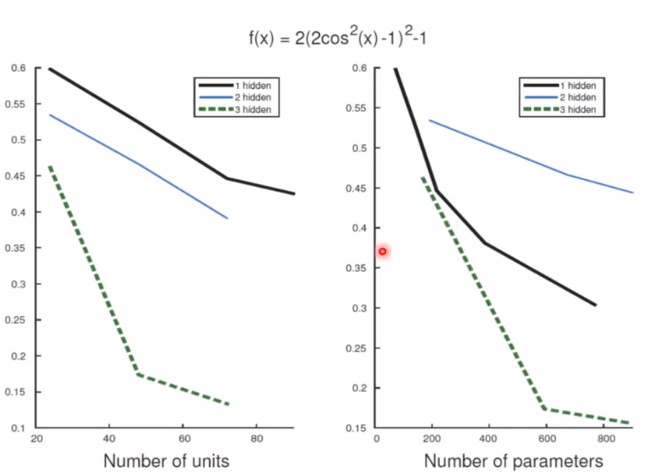
同样的精确度下,deep的network需要的参数比较少
这节课的outline
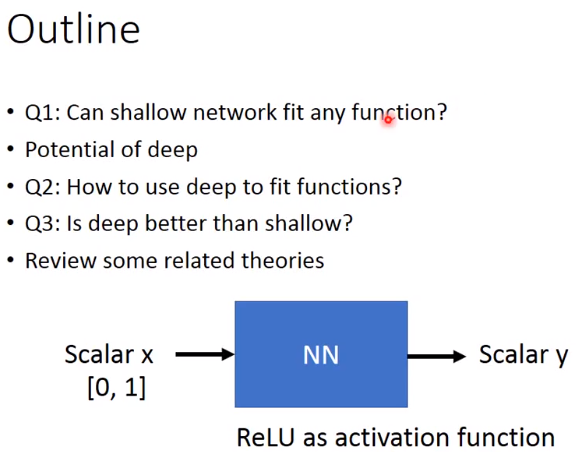
假设今天的是一个relu的network,也就是activation function是RELU
现在大部分的network是RELU
假设输入和输出都是一个scalar
且假设目标function是y=x^2
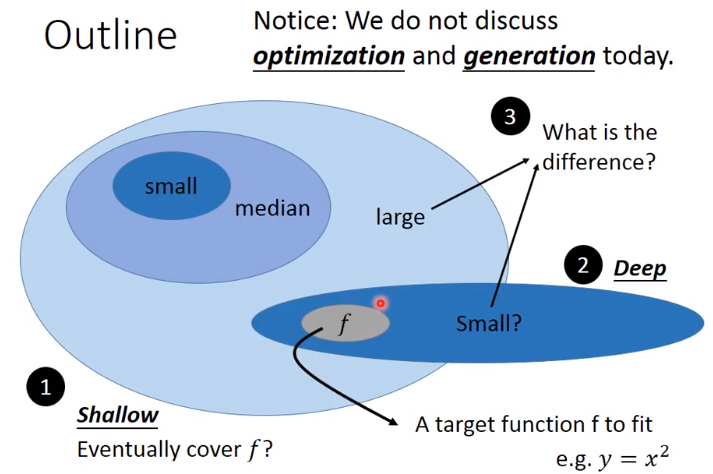
今天要证明的是,shallow的network 只要参数足够多,或者说neural足够多,那么它一定能fit f*,而deep network可以用更少的参数做到这件事,最后讨论两者之间的差别,但这次不讨论如何找到f*,以及如何在testing data上做generalization.
1:shallow network 如何fit any continue function
relu function 组成的线段都是piece-wise linear 的function,就是由一段一段的线段组成的。
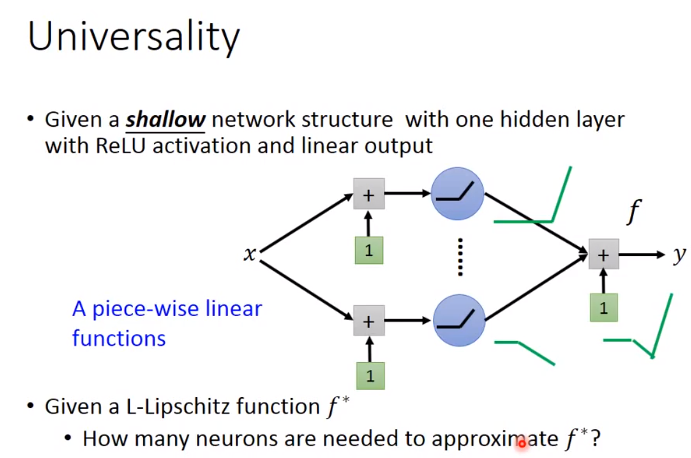
什么才算得上L-lipschitz function?
output 的变化不会大,比较平滑,下图绿色才为L-lipschitz function

找到一个f,它与f*的差距小于ε

假设f*如下图黑色线段,那么error<=l×L,此结论由下面的那个式子推到出来。
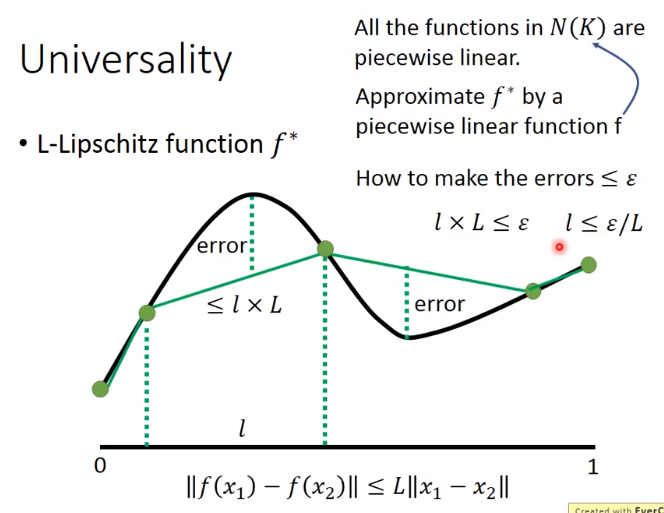
这样可以就知道 L-lipschitz function应该被分成几段
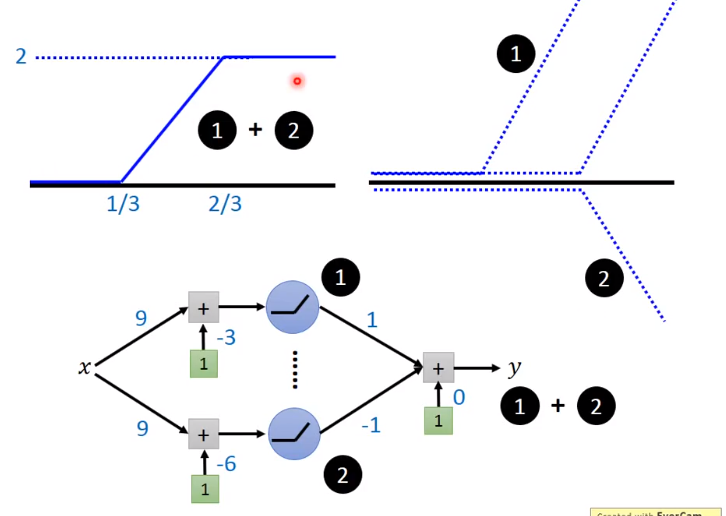
蓝色的线段相加就可以成为绿色的线段

每条蓝色的线条可以被两个relu制造出来
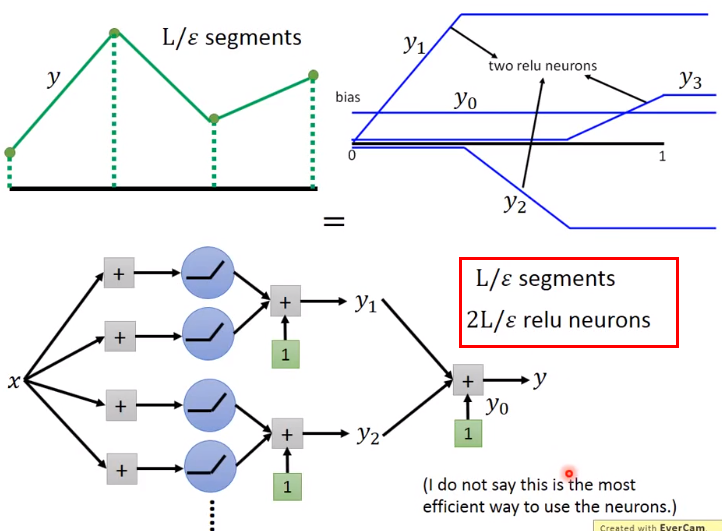
多少个segment就用2倍的数目的neurons


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









