







 本文介绍了如何在Flask项目中使用x-spreadsheet库,从数据库读取数据并转换为表格格式,同时探讨了在Windows环境下解决引用问题的方法。文章详细阐述了将DataFrame转换为x-spreadsheet兼容的JSON格式,并展示了在Flask应用中创建、加载和渲染大型数据集的流程。最后,作者提到了x-spreadsheet的编辑功能以及后续的保存数据研究。
本文介绍了如何在Flask项目中使用x-spreadsheet库,从数据库读取数据并转换为表格格式,同时探讨了在Windows环境下解决引用问题的方法。文章详细阐述了将DataFrame转换为x-spreadsheet兼容的JSON格式,并展示了在Flask应用中创建、加载和渲染大型数据集的流程。最后,作者提到了x-spreadsheet的编辑功能以及后续的保存数据研究。
项目地址; link
使用
一个最简单的demo,只用一个html,不需要任何其它配置
<link rel="stylesheet" href="https://unpkg.com/x-data-spreadsheet@1.1.1/dist/xspreadsheet.css">
<script src="https://unpkg.com/x-data-spreadsheet@1.1.1/dist/xspreadsheet.js"></script>
<script src="https://unpkg.com/x-data-spreadsheet@1.1.1/dist/locale/zh-cn.js"></script>
<div id="x-spreadsheet-demo">
<script>
x_spreadsheet.locale('zh-cn'); //中文
var htmlout = document.getElementById('x-spreadsheet-demo')
var xs = x_spreadsheet(htmlout
</script>
</body>
</div>
现在的问题是如何把插件加载json数据,以及处理保存的问题。数据导出成excel应该没问题。
在npm中使用
作者说不推荐,放弃
导入和导出
作者给的例子是另一个项目里的:link
这个例子下载后在win上有bug:
- index.html第45,46行,引用的两个文件是链接,在win是不生效的,手动下载这两个文件
- index.html 第55行,var xspr = x.spreadsheet(HTMLOUT),变量x未定义,改成x_spreadsheet(HTMLOUT)
改了之后就,浏览器打开index.html后就可以使用了,效果还不错。导出之后会丢失所有格式。
从数据库读取数据解析为表格
先看一个加载json的例子
<link rel="stylesheet"
href="https://unpkg.com/x-data-spreadsheet@1.1.1/dist/xspreadsheet.css">
<script src="https://unpkg.com/x-data-spreadsheet@1.1.1/dist/xspreadsheet.js"></script>
<script src="https://unpkg.com/x-data-spreadsheet@1.1.1/dist/locale/zh-cn.js"></script>
<div id="x-spreadsheet-demo">
<script>
x_spreadsheet.locale('zh-cn'); //中文
var htmlout = document.getElementById('x-spreadsheet-demo')
data = [{
"name":"Sheet1","freeze":"A1","styles":[],"merges":[],
"rows":{
"0":{
"cells":{
"0":{
"text":"id"},"1":{
"text":"name"}}},
"1":{
"cells":{
"0":{
"text":"1"},"1":{
"text":"Tom"}}},
"2":{
"cells":{
"0":{
"text":"2"},"1":{
"text":"Hall"}}},
"3":{
"cells":{
"0":{
"text":"3"},"1":{
"text":"Sure"}}},
"len":5},
"cols":{
"len":6},
"validations":[],
"autofilter":{
}}]
var xs = x_spreadsheet(htmlout).loadData(data)
console.log("表格返回的数据为:\n", xs.getData()) // getData得到一个object对象,要把它转为json用JSON.stringify()
console.log("json字符串格式为:\n", JSON.stringify(xs.getData()))
</script>
</div>
上面的例子中,各出的json格式和从数据库拿到的不一样,所以我们如果想把从数据库拿出的直接json样式展示出来,需要自己写一个转换函数。这个在后端还是前端都可以,我们就在后端完成这个工作。
假设由数据库得到一个df对象,现在把它拼接成这种形式的json字符串。
- 我们发现json中指定的行和列,如果新增行列是在前面加,所以指定的时候就比数据库的数据多一行一列。
现在用 python 来实现格式转换:
dataframe -> dict -> dict2 -> list
dict2的格式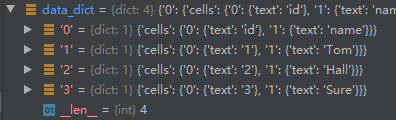
这是一个四维字典,用
dict2['0']['cells']['0']['text']
可以访问到 第一个数据,这里就是 id, 但实际上数据是二维的,二四维是固定的‘cells’和’text’。
方案一:直接用字符串拼接
def df2xspreadsheetjson(df) -> str:
'''
df对象转为 x-spreadsheet格式的json字符串
:param df: 从数据库得到的dataframe
:return: str
'''
cols = []
# 重命名标题行,主要考虑标题行空等情况
for col in df.columns:
if col == "":
cols.append("N/A") # 标题行空,一般不可能
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1695
1695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









