




 本文详细介绍了在Windows和Linux系统中如何安装和配置Python的图像文字识别环境,包括Pillow、pytesseract、tesseract-ocr的安装,中文语言包的配置,以及环境变量设置。在Windows中特别强调了安装过程中需选择中文语言包,并添加路径到环境变量。Linux环境下则相对简单,主要涉及tesseract和所需字体的安装。提供了相关资源链接和代码示例。
本文详细介绍了在Windows和Linux系统中如何安装和配置Python的图像文字识别环境,包括Pillow、pytesseract、tesseract-ocr的安装,中文语言包的配置,以及环境变量设置。在Windows中特别强调了安装过程中需选择中文语言包,并添加路径到环境变量。Linux环境下则相对简单,主要涉及tesseract和所需字体的安装。提供了相关资源链接和代码示例。
1. windons下安装
1.1 安装 Pillow 和 pytesseract
安装都很简单,在cmd命令行里直接pip3 install xxxxx就行
1.2 安装 tesseract-ocr
安装完库还不行,还要安装 tesseract 的软件,这样系统才能识别引擎成功读取文字。
可从github下载 tesseract-ocr-setup-4.00.00dev
https://github.com/tesseract-ocr/tesseract/wiki/4.0-with-LSTM#400-alpha-for-windows
也可以直接搜索 Tesseract-OCR下载即可
安装的时候要注意,tesseract的安装并不默认安装什么语言,如果自己需要简体中文的语言包,那么就不能一直点next点到finish。如下图,我安装了MATH和简体中文包。
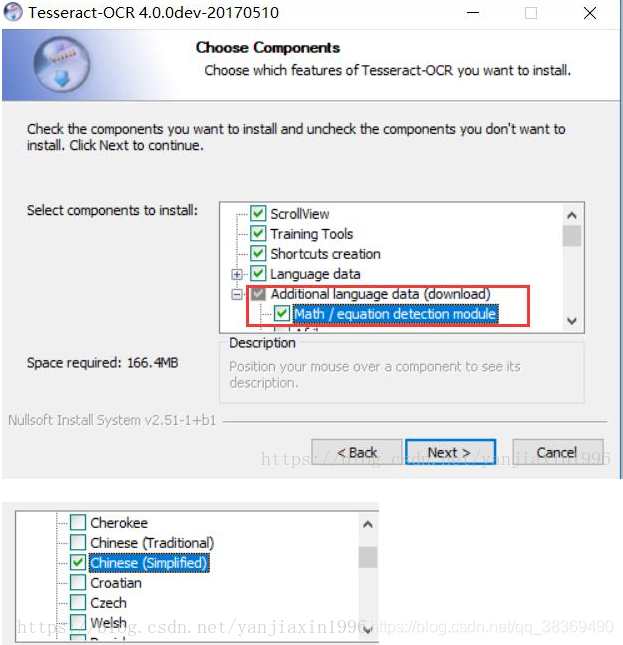
1.3 中文语言包
如果安装 tesseract-ocr 时没有设置安装中文,如果不是做英文的图文识别,还需要下载其他语言的识别包–
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









