







 本文深入探讨了JavaWeb开发的基础,包括JavaEE的13种技术,重点讲解了Servlet和JSP的应用。同时,详细解析了HTTP协议的工作原理,包括请求和响应过程,以及GET、POST等请求方式的特点。
本文深入探讨了JavaWeb开发的基础,包括JavaEE的13种技术,重点讲解了Servlet和JSP的应用。同时,详细解析了HTTP协议的工作原理,包括请求和响应过程,以及GET、POST等请求方式的特点。
Web开发概述
javaSE:
javaEE:13种
javaME:
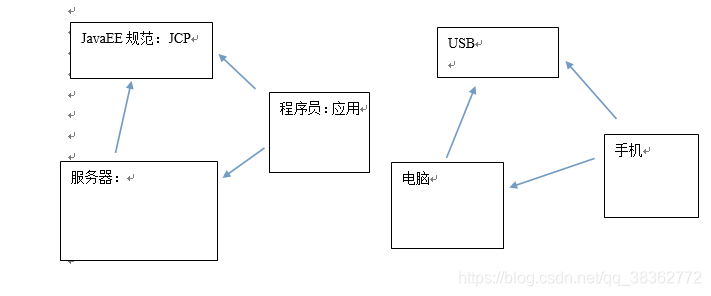
JavaEE规范: 13种技术的总称。Servlet/Jsp JDBC JNDI JTA...
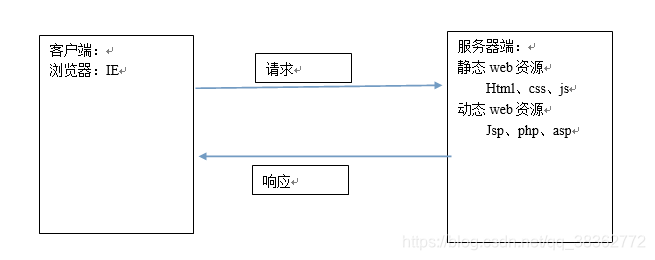
服务器请求和响应
Tomcat:Servlet/Jsp容器,轻量级服务器。
Tomcat的安装与配置
Tomcat的主要目录:

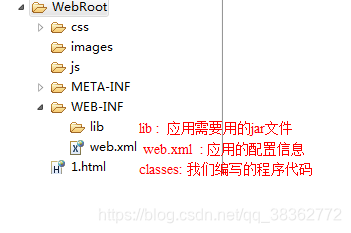
JavaWeb应用的目录结构
WEB-INF : 注意:固定写法。此目录下的文件不能被外部直接访问。
HTTP协议
HTTP协议概述
> HTTP是HyperText Transfer Protocol(超文本传输协议)的简写,传输HTML文件。
> 用于定义WEB浏览器与WEB服务器之间交换数据的过程及数据本身的格式。
请求部分
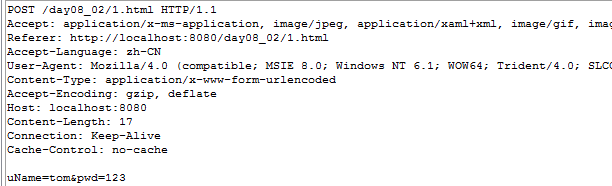
请求消息行
GET /day08_02/1.html HTTP/1.1
请求方式:Get(默认) POST DELETE HEAD等
GET:明文传输 不安全,数据量有限,不超过1kb
GET /day08_02/1.html?uName=tom&pwd=123 HTTP/1.1
POST: 暗文传输,安全。数据量没有限制。
URI:统一资源标识符。去协议和IP地址。
协议/版本 :
请求消息头
从第2行到空行处,都叫消息头
Accept:浏览器可接受的MIME类型
告诉服务器客户端能接收什么样类型的文件。
Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集
Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip
Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到。 可以在浏览器中进行设置。
Host:初始URL中的主机和端口
Referrer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面
Content-Type:内容类型
告诉服务器浏览器传输数据的MIME类型,文件传输的类型
application/x-www-form-urlencoded
If-Modified-Since: Wed, 02 Feb 2011 12:04:56 GMT利用这个头与服务器的文件进行比对,如果一致,则从缓存中直接读取文件。
User-Agent:浏览器类型.
Content-Length:表示请求消息正文的长度
Connection:表示是否需要持久连接。如果服务器看到这里的值为“Keep -Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接
Cookie:这是最重要的请求头信息之一 (在讲会话时解析)
Date:Date: Mon, 22 Aug 2011 01:55:39 GMT请求时间GMT
消息正文: 当请求方式是POST方式时,才能看见消息正文
uName=tom&pwd=123
响应部分
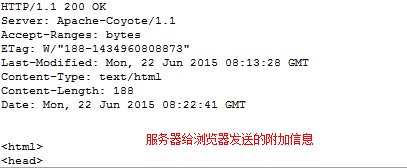
响应消息行
第一行:
HTTP/1.1 200 OK
协议/版本 响应状态码 对响应码的描述(一切正常)
响应状态码:
常用的就40多个。
200(正常) 一切正常
302/307(临时重定向)
304(未修改)
表示客户机缓存的版本是最新的,客户机可以继续使用它,无需到服务器请求。
404(找不到) 服务器上不存在客户机所请求的资源。
500(服务器内部错误)
响应消息头
Location: http://www.it315.org/index.jsp指示新的资源的位置
通常和302/307一起使用,完成请求重定向
Server:apache tomcat指示服务器的类型
Content-Encoding: gzip服务器发送的数据采用的编码类型
Content-Length: 80 告诉浏览器正文的长度
Content-Language: zh-cn服务发送的文本的语言
Content-Type: text/html; charset=GB2312服务器发送的内容的MIME类型
Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT文件的最后修改时间
Refresh: 1;url=http://www.it315.org指示客户端刷新频率。单位是秒
Content-Disposition: attachment; filename=aaa.zip指示客户端下载文件
Set-Cookie:SS=Q0=5Lb_nQ; path=/search服务器端发送的Cookie
Expires: -1
Cache-Control: no-cache (1.1)
Pragma: no-cache (1.0) 表示告诉客户端不要使用缓存
Connection: close/Keep-Alive
Date: Tue, 11 Jul 2000 18:23:51 GMT
响应正文
和网页右键“查看源码”看到的内容一样。

















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









