









0 环境准备
0.1 安装 NCCL
NCCL(NVIDIA Collective Communications Library)是一个由 NVIDIA 开发的库,它提供了针对 NVIDIA GPU 的高性能集体通信原语。这些原语包括广播(broadcast)、规约(reduce)、全规约(all-reduce)、扫描(scan)等,这些都是并行计算中常用的操作。
NCCL 主要用于多 GPU 和多节点(即分布式)环境中的深度学习训练,以加速跨多个 GPU 或多个计算节点的数据交换。在深度学习训练过程中,特别是在使用数据并行和模型并行策略时,NCCL 可以显著提高通信效率,加速训练过程。
检查是否已经安装了 NCCL:
dpkg -l | grep nccl
NCCL下载页面:https://developer.nvidia.com/nccl/nccl-download
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt install libnccl2=2.24.3-1+cuda12.2 libnccl-dev=2.24.3-1+cuda12.2
安装说明文档:https://docs.nvidia.com/deeplearning/nccl/install-guide/index.html
验证是否安装成功:
import torch
print("nccl version: ",torch.cuda.nccl.version())
0.2 安装 deepspeed
pip install deepspeed
1 启动任务
1.1 环境变量配置
在使用 torch.distributed 时,通常需要设置以下几个环境变量:
MASTER_ADDR: 主节点的地址
MASTER_PORT: 主节点的端口
WORLD_SIZE: 参与训练的总进程数
RANK: 当前进程的排名(从0开始)
例如,有4个进程参与训练,可以这样设置:
MASTER_ADDR="127.0.0.1"
MASTER_PORT="29500"
WORLD_SIZE=4
RANK=0 # 对于每个进程,RANK 应该不同
1.2 启动训练脚本
如果使用的是torch.distributed.launch或其他启动工具,这些环境变量通常会自动设置。如果手动启动,确保每个进程都有正确的RANK和WORLD_SIZE。
例如,使用torch.distributed.launch启动脚本时,可以这样:
python3 -m torch.distributed.launch --nproc_per_node=4 --master_port=29500 your_script.py
这样torch.distributed.launch会自动设置这些环境变量。确保在每个参与训练的节点上都正确设置了这些环境变量。
1.3 DeepSpeed 中配置多个服务器多个GPU
DeepSpeed 是一个用于加速大规模模型训练的深度学习优化库,它支持在多个服务器上进行分布式训练。在 DeepSpeed 的分布式训练中,通常只需要在一台服务器上运行启动脚本。这台服务器通常被称为主节点(master node)或主服务器(master server)。主节点负责协调和管理整个分布式训练过程。
DeepSpeed 中可能有两个配置文件,一个是.json文件配置超参数,一个是服务器与 GPU 数量文本文件,前一个也可以在启动.sh脚本中配置或在运行配置中通过传参方式配置。后一个可传可不传。若不传,只能是在当前服务器上进行训练。
1.3.1 主节点运行启动脚本
在主节点上运行启动脚本(如 launch.sh)。这个脚本会使用 DeepSpeed的 分布式启动工具(如 deepspeed 命令)来启动训练过程,并自动在所有参与的服务器上启动相应的进程。
1.3.2 配置文件和主机列表
确保启动脚本中指定了正确的配置文件(如 deepspeed_config.json)和主机列表文件(如 hostfile)。主机列表文件中包含了所有参与训练的服务器的IP地址和可用GPU数量。
deepspeed_config.json通常如下:
{
"train_batch_size": 4,
"steps_per_print": 2000,
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.001,
"betas": [
0.8,
0.999
],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000
}
},
"wall_clock_breakdown": false
}
1.3.3 SSH无密码登录
确保主节点可以通过SSH无密码登录到所有其他服务器。这样,主节点可以自动在其他服务器上启动训练进程,而无需手动干预。
1.3.4 示例启动脚本
以下是一个示例启动脚本 launch.sh:
#!/bin/bash
deepspeed --hostfile hostfile your_script.py --deepspeed_config deepspeed_config.json
其中 hostfile 是一个文本文件,包含所有服务器的IP地址和可用GPU数量。例如:
server1 slots=4
server2 slots=4
1.3.5 运行启动脚本
在主节点上运行启动脚本:
./launch.sh
通过这种方式,主节点会自动在所有参与的服务器上启动训练进程,并协调它们之间的通信和数据同步。其他服务器(从节点)会根据主节点的指令执行相应的训练任务。
只需要在主节点上运行启动脚本,它会自动在所有其他服务器上启动相应的训练进程。
1.4 确定主服务器
在 DeepSpeed 的分布式训练中,主服务器(也称为主节点或master node)通常是启动分布式训练过程的服务器。主服务器负责协调和管理整个分布式训练集群。确定主服务器的方法如下:
1.4.1 手动指定:
在启动脚本中,你可以手动指定哪台服务器作为主服务器。通常,你会在主服务器上运行启动脚本,并在脚本中指定主机列表文件(如 hostfile)。
1.4.2 主机列表文件
主机列表文件(如 hostfile)中列出了所有参与训练的服务器的 IP 地址和可用 GPU 数量。**通常,列表中的第一台服务器会被默认作为主服务器。**例如:
server1 slots=4
server2 slots=4
server3 slots=4
这里server1 会被默认作为主服务器。
1.4.3 启动脚本示例
以下是一个示例启动脚本 launch.sh,它会在主服务器上运行:
#!/bin/bash
deepspeed --hostfile hostfile your_script.py --deepspeed_config deepspeed_config.json
这里,hostfile 文件的第一行对应的服务器会被作为主服务器。
1.4.4 自动选择
DeepSpeed 的分布式启动工具(如 deepspeed 命令)会自动选择主机列表文件中的第一台服务器作为主服务器。因此,确保主机列表文件中的第一台服务器是希望作为主服务器的机器。
1.4.5 环境变量
也可以通过环境变量来指定主服务器。例如,可以使用 MASTER_ADDR 和 MASTER_PORT 环境变量来指定主服务器的IP地址和端口。
export MASTER_ADDR=server1
export MASTER_PORT=29500
通过以上方法,可以指定主服务器。通常情况下,只需要在主服务器上运行启动脚本,并确保主机列表文件中的第一台服务器是希望作为主服务器的机器即可。
2 DeepSpeed训练、推理、压缩实例
代码地址:https://github.com/microsoft/DeepSpeedExamples
2.1 训练
代码位置:DeepSpeedExamples/applications/DeepSpeed-Chat
- 永久设置
TORCH_CUDA_ARCH_LIST变量
echo 'export TORCH_CUDA_ARCH_LIST="7.5"' >> ~/.bashrc
source ~/.bashrc
其中 7.5 是对应的 GPU 的CUDA架构。我这里使用的是 2080Ti,对应的就是 7.5。其他型号的卡,可以在 NVIDIA 官网找到对应的值。也可以用如下命令来查看:
python3 -c "import torch; print(torch.cuda.get_device_capability())"
# (7, 5)
MAX_JOBS环境变量设置
MAX_JOBS环境变量用于指定在编译过程中允许的最大并行任务数。设置这个变量可以控制编译时的CPU和内存资源使用,避免因并行任务过多导致系统资源耗尽。
在Linux上设置
# 1. 临时设置(仅对当前终端会话有效):
export MAX_JOBS=4
# 2. 永久设置(对所有终端会话有效):
# 将上述命令添加到Shell配置文件中,例如`~/.bashrc`、`~/.zshrc`或`~/.profile`
echo 'export MAX_JOBS=4' >> ~/.bashrc
source ~/.bashrc
设置的一般原则:
CPU核心数:通常建议将`MAX_JOBS`设置为CPU核心数。例如,如果CPU有8个核心,可以设置`MAX_JOBS=8`。
内存限制:如果系统内存有限,可以适当减少`MAX_JOBS`的值,以避免内存不足导致编译失败。
编译速度和资源平衡:根据系统资源和编译需求,调整`MAX_JOBS`的值,以达到最佳的编译速度和资源使用平衡。
通过合理设置`MAX_JOBS`环境变量,可以更好地控制编译过程中的资源使用,避免系统过载,并提高编译效率。
- 训练过程中检查内存使用情况
free -m
# 可以使用 -a 选项来查看当前 shell 会话的所有资源限制
ulimit -a
- 启动训练:
DeepSpeedExamples/training/cifar/cifar10_deepspeed.py
上面的脚本默认只会使用一张卡。
可以使用下面的命令启动训练,可以调用多张卡:
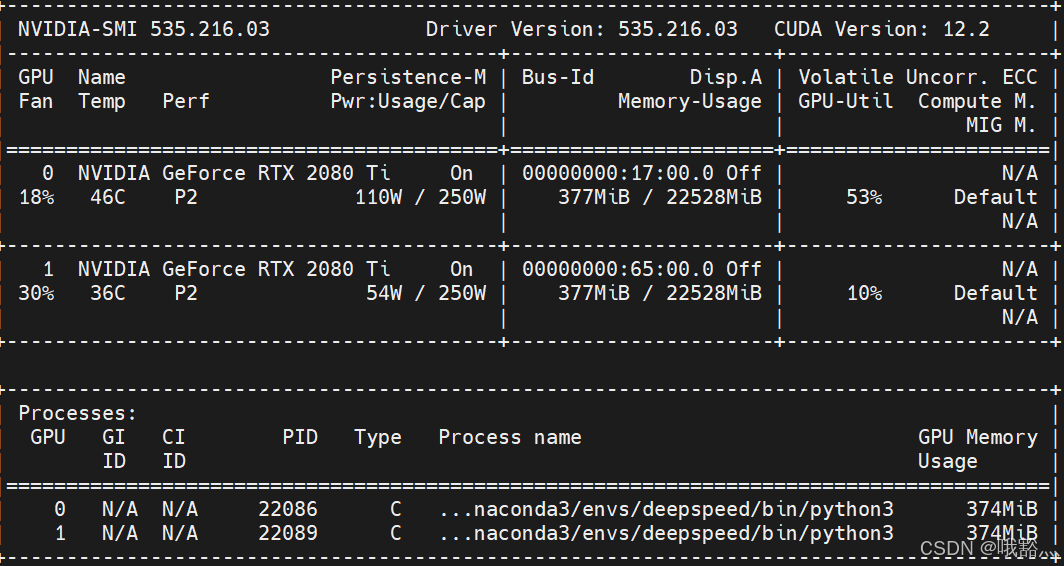
deepspeed --num_nodes=1 --num_gpus=2 --bind_cores_to_rank cifar10_deepspeed.py --log-interval 100 --deepspeed --moe --ep-world-size 2 --num-experts 2 --top-k 1 --noisy-gate-policy 'RSample' --moe-param-group
看起来两张卡负载不太一样?
2.2 推理
- 启动推理
DeepSpeedExamples/training/stable_diffusion/inf_txt2img_loop.py
2.3 模型压缩
可运行DeepSpeedExamples/compression/cifar/run_compress.sh,在训练模型后,对保存的模型执行压缩。
3 报错解决
3.1 如果安装了 CUDA 但运行中报类似下面问题
deepspeed/ops/csrc/adam/cpu_adam_impl.cpp -o cpu_adam_impl.o
[3/3] c++ cpu_adam.o cpu_adam_impl.o -shared -lcurand -L/opt/venv/python39venv/lib/python3.9/site-packages/torch/lib -lc10 -ltorch_cpu -ltorch -ltorch_python -o cpu_adam.so
FAILED: cpu_adam.so
c++ cpu_adam.o cpu_adam_impl.o -shared -lcurand -L/opt/venv/python39venv/lib/python3.9/site-packages/torch/lib -lc10 -ltorch_cpu -ltorch -ltorch_python -o cpu_adam.so
/usr/bin/ld: 找不到 -lcurand: 没有那个文件或目录
collect2: error: ld returned 1 exit status
ninja: build stopped: subcommand failed.
可以用下面方法解决:
sudo cp /usr/local/cuda/lib64/libcurand.so /usr/lib64
sudo cp /usr/local/cuda/lib64/libcurand.so.10 /usr/lib64
sudo cp /usr/local/cuda/lib64/libcurand.so.10.3.3.141 /usr/lib64
3.2 libcusparse.so.12: undefined symbol: __nvJitLinkComplete_12_4, version libnvJitLink.so.12
本地环境说明:
CUDA 12.2
cuDNN 8.9
pytorch 2.5.1
gpu 2080Ti
可能是 pytorch 的依赖问题,缺少相关库导致 gpu 加载失败。
3.2.1 尝试修复
conda install pytorch pytorch-cuda=12.1 -c pytorch -c nvidia
等待安装新的包:
不出意外的话,此时就 OK 了。要是出意外了,就得另寻他法了。
3.2.2 另寻他法
ldd /home/taot/.local/lib/python3.10/site-packages/torch/lib/../../nvidia/cusparse/lib/libcusparse.so.12
# 输出如下
/../nvidia/cusparse/lib/libcusparse.so.12
linux-vdso.so.1 (0x00007ffccf9cc000)
libnvJitLink.so.12 => /usr/local/cuda-12.1//lib64/libnvJitLink.so.12 (0x00007eff08e00000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007eff1cf0b000)
librt.so.1 => /lib/x86_64-linux-gnu/librt.so.1 (0x00007eff1cf06000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007eff1cf01000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007eff0bf19000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007eff1cedf000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007eff08bd7000)
/lib64/ld-linux-x86-64.so.2 (0x00007eff1cf1d000)
libnvJitLink.so.12的所依赖的这些链接信息都是系统的。应该是 pytorch 安装过程中也安装了配套的 nvidia 的动态库,但链接的时候没有链接正确。把libnvJitLink.so.12加上nvidia库对应的软链,并把nvjitlink加到动态库中:
ln -s /home/taot/.local/lib/python3.10/site-packages/nvidia/nvjitlink/lib/libnvJitLink.so.12 /home/taot/.local/lib/python3.10/site-packages/nvidia/cusparse/lib/libnvJitLink.so.12
export LD_LIBRARY_PATH=/home/taot/.local/lib/python3.10/site-packages/nvidia/cusparse/lib:$LD_LIBRARY_PATH
不出意外的话是没有意外了。要是再出意外的话,那就继续另寻他法吧。
3.2.3 安装 mpi4py 失败
安装此模块需要首先安装mpich,
sudo apt install mpich
如果提示没有mpich可以首先更新一下:sudo apt-get update,在进行安装mpich。
讲道理之后再进行pip install mpi4py即可。
可是我的机器貌似不讲道理,还是继续报错:
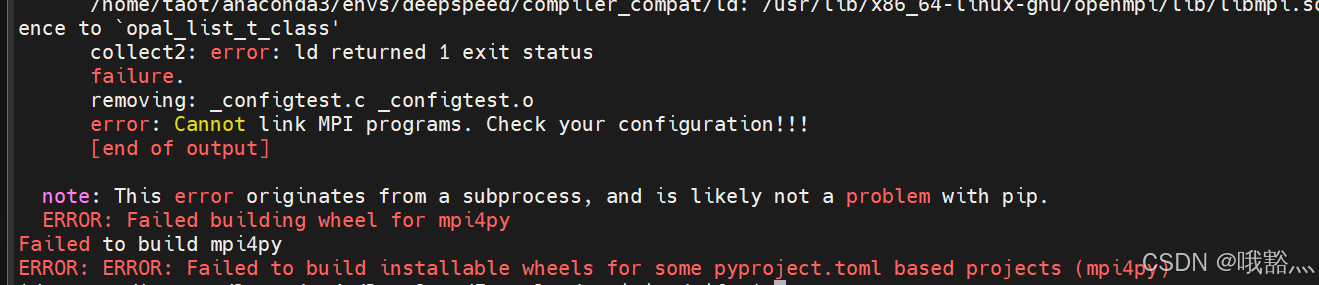
继续想办法:
看到一位大佬说 这个问题是miniconda/conda使用了不合适的MPI路径:mpi4py安装不上的解决方案(终极版)
这里有两种解决方法:
- pip:
sudo apt install openmpi-bin libopenmpi-dev升级一下再装 - conda:
conda install -c conda-forge mpich mpi4py直接用conda装
我这里 pip 的方法无效,直接用 conda 装是 OK 的。
当然了,还有一个更直接的方法:
rm /home/taot/anaconda3/envs/deepspeed/compiler_compat/ld
这个实际上是 conda 的一个 bug。
以上是使用 deepspeed 进行训练、推理和模型压缩的整体流程,以及其中遇到的一些问题和解决问题的思路与方法。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









