







 本文深入探讨Spring框架如何解决循环依赖问题,通过三级缓存机制确保单例bean的正确初始化,避免死循环。详细分析了AbstractBeanFactory、DefaultListableBeanFactory等核心组件的工作原理。
本文深入探讨Spring框架如何解决循环依赖问题,通过三级缓存机制确保单例bean的正确初始化,避免死循环。详细分析了AbstractBeanFactory、DefaultListableBeanFactory等核心组件的工作原理。
文章目录
深入理解Spring循环依赖----删除三级缓存,二级缓存可不可以放代理对象和普通对象?
Spring如何解决循环依赖
循环依赖的过程
当有循环依赖时,AB之间相互依赖,A 对象 已经实例化,并未初始化,在进行填充属性之前,将bean工厂对象放入到三级缓存之中,当进行初始化填充属性时,又对B进行实例化,此时b对象也是未被初始化,在进行填充属性之前,将bean工厂对象放入到三级缓存之中,当进行初始化属性填充时,发现B对象中有A作为其属性,那么又对A进行初始化,此时逻辑将进入这个代码块。
此时返回实例化但未被初始化的A对象(A对象中的B属性仍然没有值),将这个A对象注入到B对象的A属性中,此时B对象已经实例化并且也已经初始化成功了,此时把B对象放入到一级缓存当中,并且删除二级缓存和三级缓存有关B对象的东西, 此时有又将B对象注入到A对象的B属性中。此时把A对象放入到一级缓存中,,并且删除二级缓存和三级缓存有关A对象的东西,完成循环依赖的注入。
测试代码
首先书写最简单的代码 创建两个相互依赖的对象
package com.test.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class Student {
@Autowired
private Person person;
public Person getPerson() {
return person;
}
}
package com.test.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class Person {
@Autowired
private Student student;
public Student getStudent() {
return student;
}
}
package com.test;
import com.test.config.AppConfig;
import com.test.service.Person;
import com.test.service.Student;
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class Main {
public static void main(String[] args) {
ApplicationContext applicationContext=new AnnotationConfigApplicationContext(AppConfig.class);
Person person=applicationContext.getBean(Person.class);
System.out.println(person);
System.out.println(person.getStudent());
Student student=applicationContext.getBean(Student.class);
System.out.println(student);
}
}
看到源代码中 AbstractApplicationContext 抽象类中的 finishBeanFactoryInitialization
源代码中的注释 Instantiate all remaining (non-lazy-init) singletons.
实例化非懒加载的单例对象
所以疑问?对于有循环引用的对象他是怎么初始化的呢?怎么解决死循环这个问题呢?是如何保证单例的呢?接着往下看
看到 finishBeanFactoryInitialization 的 beanFactory.preInstantiateSingletons();
这一行是看到 这个才是真正对非懒加载的单例对象进行实例化。
紧接着我们将关注到这个方法 是DefaultListableBeanFactory 来实现的。
着重看到getBean 方法.
以下是getBean的具体实现的重要细节。
// Eagerly check singleton cache for manually registered singletons.
// 对于手动注册的单例bean ,进行循环依赖的校验
Object sharedInstance = getSingleton(beanName);
紧接着我们看到其实现
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//从一级缓存当中获取bean对象
Object singletonObject = this.singletonObjects.get(beanName);
//如果一级缓存中没有,并且 单例对象正在创建当中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//从二级缓存当中拿出bean对象
singletonObject = this.earlySingletonObjects.get(beanName);
//如果bean对象没拿到并且是允许循环依赖的
if (singletonObject == null && allowEarlyReference) {
//那么就从三级缓存当中获取bean工厂对象,这里为什么是工厂对象呢?稍后进行阐述
//这个三级缓存什么时候有数据呢?当一个bean对象已经实例化但是未被初始化时,就是将这个半成品bean对象的Bean工厂对象放入到三级缓存当中
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
//二级缓存用来存放 三级缓存bean工厂创建的已经被实例化,但未被初始化的bean对象
//二级缓存的场景是什么样子的呢?
//循环依赖的过程 S
//当有循环依赖时,AB之间相互依赖,A 对象 已经实例化,并未初始化,在进行填充属性之前,将bean工厂对象放入到三级缓存之中,当进行初始化填充属性时,又对B进行实例化,此时b对象也是未被初始化,在进行填充属性之前,将bean工厂对象放入到三级缓存之中,当进行初始化属性填充时,发现B对象中有A作为其属性,那么又对A进行初始化,此时逻辑将进入这个代码块。
//此时返回实例化但未被初始化的A对象(A对象中的B属性仍然没有值),将这个A对象注入到B对象的A属性中,此时B对象已经实例化并且也已经初始化成功了,此时把B对象放入到一级缓存当中,并且删除二级缓存和三级缓存有关B对象的东西, 此时有又将B对象注入到A对象的B属性中。此时把A对象放入到一级缓存中,,并且删除二级缓存和三级缓存有关A对象的东西.
//完成循环依赖的注入。
//循环依赖的过程 E
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
紧接着我们看到这个,看getSingleton实现
//
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
destroySingleton(beanName);
throw ex;
}
});
getSingleton实现 简要
//开始单例对象的创建 将bean对象标记为正在创建中...
beforeSingletonCreation(beanName);
try {
//调用创建bean对象
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
//删除正在创建bean对象的标记
afterSingletonCreation(beanName);
//将创建好的bean对象放入到一级缓存中,并且删除二级和三级缓存中的有关bean对象的值
if (newSingleton) {
addSingleton(beanName, singletonObject);
}
紧接着我们看到创建bean对象的实现 createBean的实现doCreateBean
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
//可以继承MergedBeanDefinitionPostProcessor动态修改BeanDefinition
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
//判断是否具有循环依赖的权限
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
//将() -> getEarlyBeanReference(beanName, mbd, bean) 这个Bean工厂对象放入到三级缓存当中,并且删除二级缓存中的有关bean 并且bean工厂创建对象时 对于一些继承了SmartInstantiationAwareBeanPostProcessor的子类进行调用,对bean对象进行更改。
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
//初始化bean对象
// Initialize the bean instance.
Object exposedObject = bean;
try {
//填充bean对象的属性
populateBean(beanName, mbd, instanceWrapper);
//初始化bean对象自定义初始化逻辑
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
紧接着对populateBean 重要细节进行详解
//是否有感知bean的初始化的类
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
PropertyDescriptor[] filteredPds = null;
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
for (BeanPostProcessor bp : getBeanPostProcessors()) {
//有两个及其重要的对于填充属性的类
//AutoWiredAnnotationBeanPostProcessor 当使用@AutoWired注解时起作用
//CommonAnnotationBeanPostProcessor 当使用@Resource注解时起作用
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
PropertyValues pvsToUse = ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
//这个方法 如果属性是对象属性最终调用还是 会调用BeanFactory,getBean()方法,重新走一遍现在的整个逻辑。
pvsToUse = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
}
pvs = pvsToUse;
}
}
}
流程图
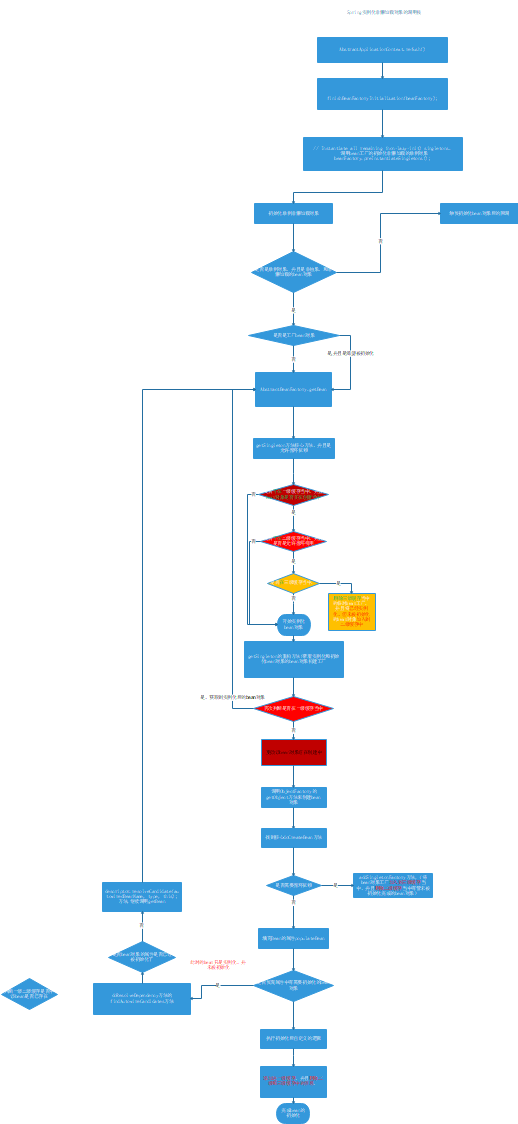
思考:为什么一定要使用3个缓存呢?
三级缓存是否可以去掉?二个缓存能不能实现?
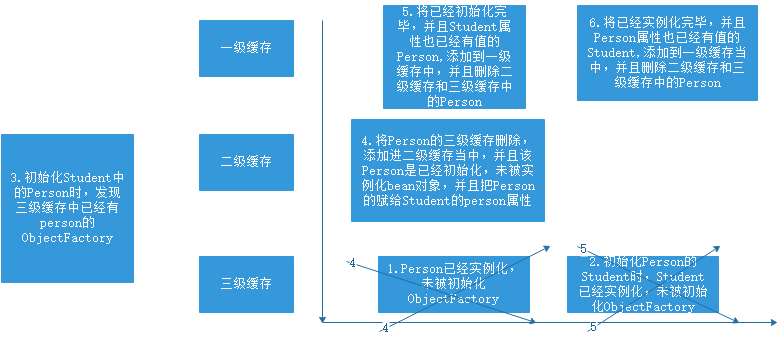
- 首先我们要搞清楚 一级,二级,三级缓存是干什么的
- 1级缓存 存储的是实例化,并且初始化后的 完整的bean对象
- 2级缓存 存储的是 循环依赖中的已经实例化但未被初始化(正在创建中的)的对象,并且二级缓存中的对象时三级缓存中的bean对象工厂生产的对象。
- 3级缓存 存储的是 循环依赖中的已经实例化但未被初始化的(正在创建中的)的对象的工厂
设想去除三级缓存,会发生什么?如果没了第三级缓存 将会影响这几段重要代码
//刚开始这段 AbstractBeanFactory.getSingleton S
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
//刚开始这段 getSingleton E
//当循环依赖时 DefaultSingletonBeanRegistry.addSingletonFactory S
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
//当循环依赖时 E
将改成
//刚开始这段 AbstractBeanFactory.getSingleton S
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
}
}
return singletonObject;
//刚开始这段 getSingleton E
//当循环依赖时 DefaultSingletonBeanRegistry.addSingletonFactory S
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
this.earlySingletonObjects.put(beanName, exposedObject);
this.registeredSingletons.add(beanName);
}
}
//当循环依赖时 E
依据上面的流程,两个缓存是可以满足循环依赖的需求的
所以综上所诉 是可以进行 两个缓存是可以满足循环依赖的。那为什么spring需要有第三级缓存呢?
看第三级缓存存的是bean对象的Bean工厂,二级缓存中的对象是通过三级缓存中bean工厂对象生产出来的bean
三级缓存存的是bean工厂,可以很好的与Bean的生产很好的解耦,如果你想要的什么样的bean,可以对这个ObjectFactory进行扩展,并且Spring这种函数式编程的实现更优雅。
总结
Spring通过使用多个缓存,来解决Spring的循环依赖,别且两个缓存也是可以解决循环依赖的,但是通过三级缓存有两个好处
- 第一可以很好地与构建bean对象进行解耦,当你想要创建任何的Bean对象通过继承ObjectFactory ,然后直接将继承后的对象放入到addSingletonFactory的形参中,可以做到快速替换。
- 使用函数式编码更优雅,更方便。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











