




 本文介绍了一种使用Java和正则表达式从销售小票中提取商品种类及数量的方法,通过实例演示了如何利用HashMap进行商品数量的统计汇总。
本文介绍了一种使用Java和正则表达式从销售小票中提取商品种类及数量的方法,通过实例演示了如何利用HashMap进行商品数量的统计汇总。
如题,例如从小票中提取卖出去的商品种类及其总数:

package demo;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test {
public static void main(String[] args) {
//用来存放临时数据
String[] tmp1;
String[] tmp2;
String tmp3;
int num1;
//直接用流读文件会去掉换行符,所以这里用String直接模拟读入的小票
String Music3 =
"2018-09-12 12:13:16"
+ "\n"
+ "流水号:98673456093773611"
+ "\n"
+ "== 欢迎光临大润发超市 =="
+ "\n"
+ "苹果 5.00 ×2 10.00"
+ "\n"
+"苹果 5.00 ×2 10.00"
+ "\n"
+ "香蕉 6.00 ×2 12.00"
+ "\n"
+ "牛仔裤 198.00 ×1 198.00"
+ "\n"
+ "总计: 220.00"
+ "\n"
+ "流水号:98673456093773611"
+ "\n"
+ "付款方式: 微信"
;
//定义一个map对象并且添加泛型,用来当计数器
Map<String,Integer> map = new HashMap<>();
//用换行符切割,得到每一行
String[] demo = Music3.split("\n");
//对每一行用正则表达式去判断,若符合 "苹果 5.00 ×2 10.00" 则对其再分割
//得到"苹果 ×2",再分割"×2",得到"2",并将其转换成整型
//最后将"苹果 2"当作键值对存入map
//若读到另一张小票的苹果记录,则将原本map对应的值再加上现在的数量
for (int i = 0; i < demo.length; i++) {
String line = demo[i];
//正则表达式
String reg = "^[\u4e00-\u9fa5]+\\s+\\d+.\\d+\\s+×\\d+\\s+\\d+.\\d+$";
// 创建 Pattern 对象
Pattern r = Pattern.compile(reg);
// 现在创建 matcher 对象
Matcher matcher = r.matcher(line);
//判断是否匹配成功
boolean rs = matcher.matches();
if (rs == true) {
tmp1 = line.split("\\s");
tmp2 = tmp1[2].split("×");
tmp3 = tmp2[1];
num1=Integer.parseInt(tmp3);
if (map.containsKey(tmp1[0])){
//将对应key的值加上num1
map.put(tmp1[0],map.get(tmp1[0])+num1);
}else {
//第一次出现的向map添加单词为key,值为num1
map.put(tmp1[0],num1);
}
}
}
//输出map的键值
System.out.println(map.keySet()+":"+map.values());
//若想在Hadoop上运行,则对TokenizerMapper里面的方法做对应的修改即可
}
}
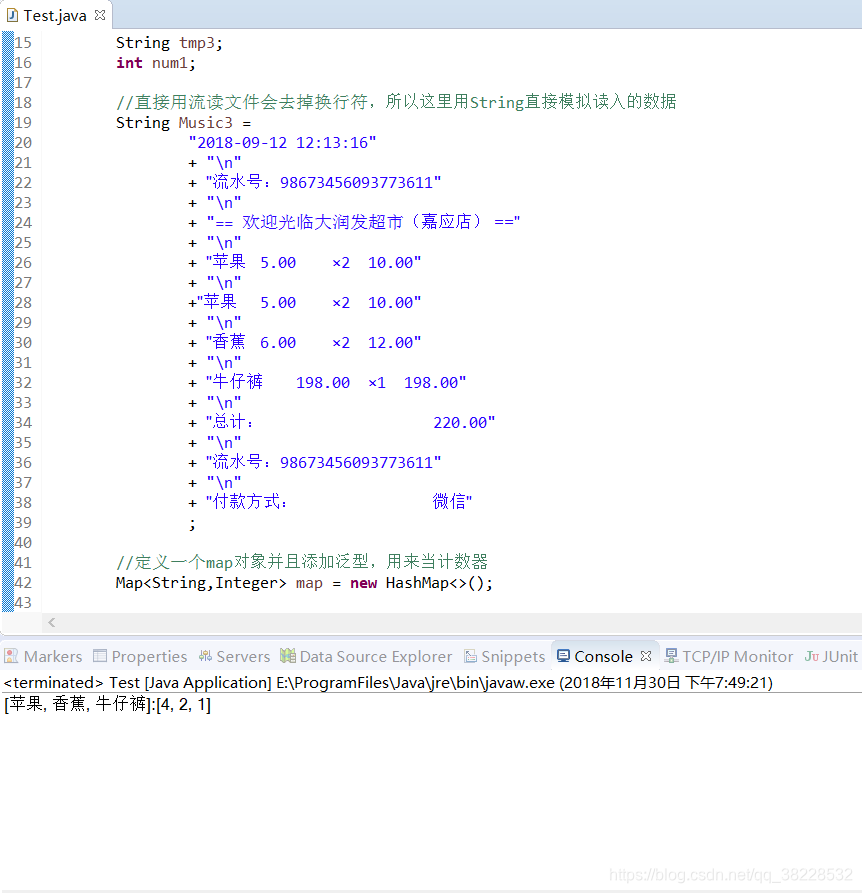
结果截图

















 4211
4211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









