







 本文介绍了如何使用Python进行VOC数据的清洗工作,包括读取数据、利用jieba分词并去除停用词,最后将清洗后的数据保存到新的Excel文件中。
本文介绍了如何使用Python进行VOC数据的清洗工作,包括读取数据、利用jieba分词并去除停用词,最后将清洗后的数据保存到新的Excel文件中。
前言
本文主要介绍通过python实现数据清洗、脚本开发、办公自动化。读取voc数据,存储新清洗后的voc数据数据。
一、业务逻辑
- 读取voc数据采集的数据
- 批处理,使用jieba进行分词,去除停用词,清洗后的评论存储到新的列中
- 保存清洗后的数据到新的Excel文件中
二、具体产出
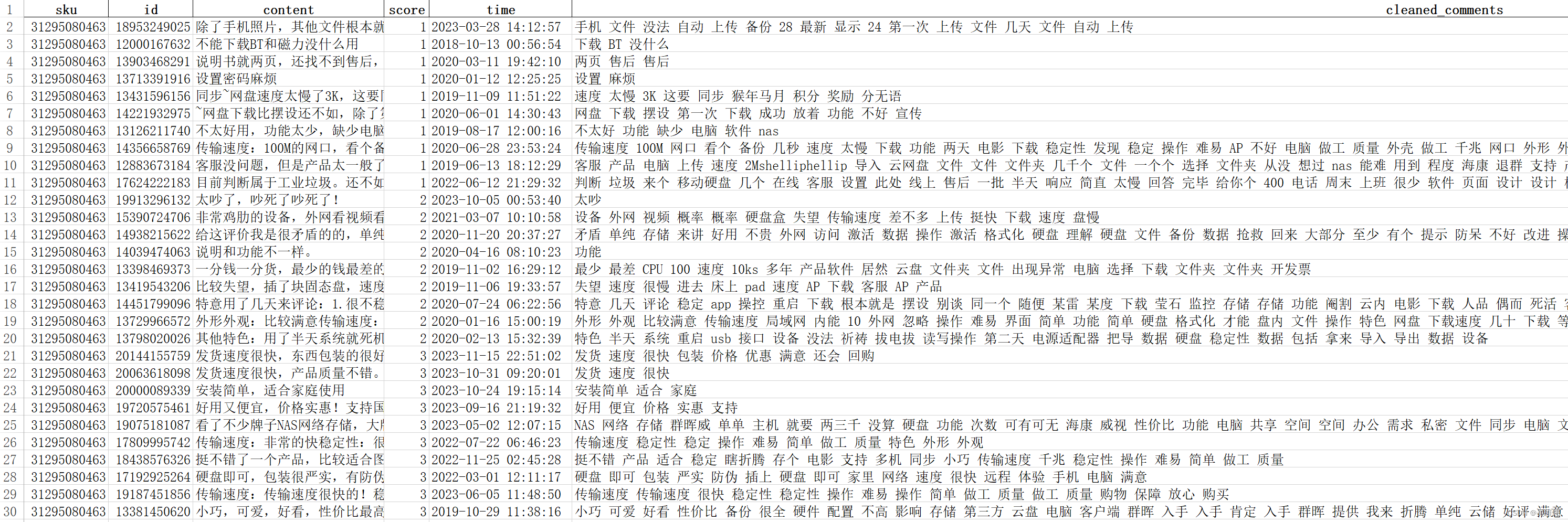
三、执行脚本
python clean.py
四、脚本
# voc数据清洗
import pandas as pd
import jieba
import jieba.posseg as pseg
from collections import Counter
import re
fileName = "100070291457" # sku
# 加载停用词
with open('stopwordsfull', 'r', encoding='utf-8',errors='replace') as f:

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









