







HashMap底层解析1.8新特性
HashMap的底层是数组+链表形式(1.7版本)
HashMap的底层数组+链表+红黑树(1.8版本)
以上一点是最主要的不同点
那么1.7和1.8的一些共同属性是:
数组的默认长度:16;
负载因子:0.75
扩容倍数:2倍
阈值(也就是什么时候需要扩容):16*0.75=12
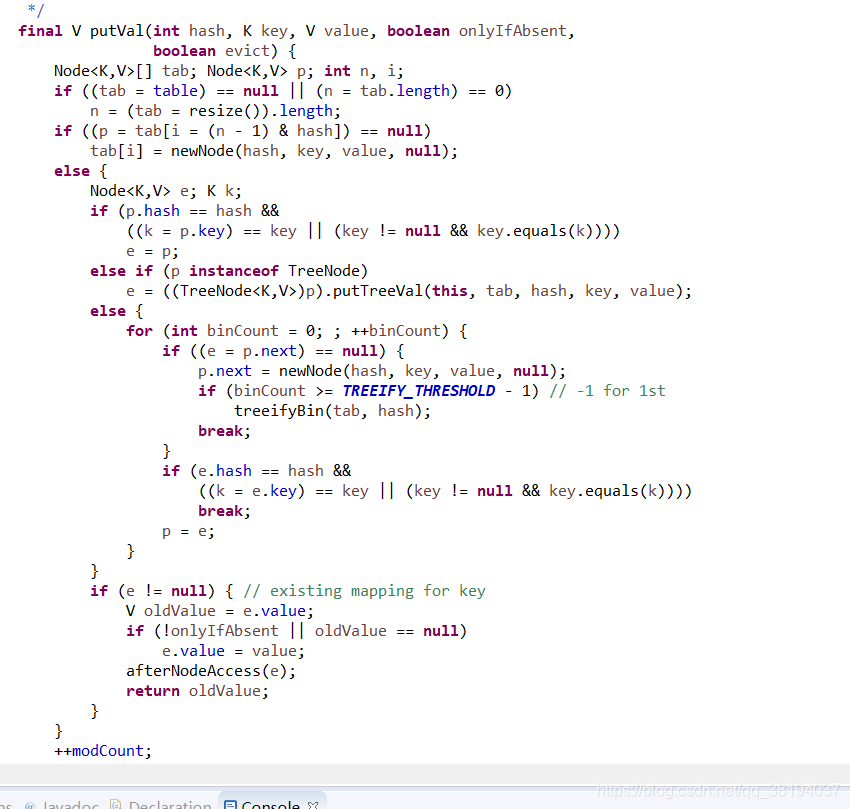
由于底层的源码以及方法太多,博主值选择put()方法进行详解HashMap<String,String> myhashMap = new HashMap<String,String>(); myhashMap.put("水果","柚子"); //另外提一下,put()方法是有返回值的,当key值相同时,返回值为之前的value值 //key值不同时,返回null;即插入的值是否会覆盖原元素 System.out.println(myhashMap.put("水果","橘子")); //这里覆盖了原元素,将打印出 "柚子"这边查看put()方法的源码,发现调用了hash()方法计算出插入元素key值的hash值,然后通过hashCode()获取的值对数组长度-1 进行&运算,然后通过一系列的位运算来获得这个Key值在数组中的存储位置。
当然这边给出的是JDK1.8的源码,1.7的源码的算法不太一样。
1.为什么要进行如此复杂的位运算?
这边先说一下,当两个Hash值相同时,也就是在数组上的存储位置相同时(对象不一致),也就是所谓的hash碰撞,那么HashMap会将新的元素以链表的形式连接在那个数组的位置;所以,为了减少链表的长度,就需要复杂的算法来减少hash碰撞,这样就可以减少链表的长度。
既然说到了链表,那么来聊一下1.7版本的链表插入形式
在JDK1.7版本的时候,当产生了hash碰撞,后来的元素,也就是新元素是插入到链表的头部,因为插入链表的头部对于插入操作来说效率是最高的,那么问题就来了,插入了头部,又是单链表,要怎么查询新的元素呢?
其实在1.7中,插入链表头部之后还会进行一步操作,就是将此时的链表头部赋值给在数组中元素,那么就变成了链表的头是数组元素,数组中之前的元素就是链表的下一个元素,就可以进行查询了;
此时就可以说一下1.8的插入形式:
1.8的HashMap多了一个红黑树,这里有一个属性
这个属性是为了确定什么时候将链表变为红黑树的,类似与阈值;
当一个链表长度达到8时,将转换为红黑树,这是发生hash碰撞时的第一个不同点;
第二个不同点就是:1.7插入我们说过是插入链表头部,但是1.8是插入到尾部。
看一下源码:
1.8之后也顺便将Entry改名为Node,从代码中可以看出,在插入一个节点(Node)时,他的next值设为了null,也就是说它是最后一个节点。 tab[i] = newNode(hash, key, value, null);
插入说完了 来说一下扩容:
1.7和1.8都会扩容,扩容都是以2倍扩容
那么来说一下扩容的前提:
1.7的扩容条件有两个,1.数组元素到达阈值,且新来的元素插入的位置有元素占着,很少有人会知道第二个条件,举个例子:
比如数组长度16,现在下标为1234还空着,那么,此时新来的元素要是hash值算出的位置是在1234中,那么就不会进行扩容,只有hash冲突了才会扩容。且扩容完之后,所有的元素的hash值都要重新计算,所以在扩容过程中可能产生死锁。
1.8则摒弃了第二个条件,只要数组使用了12个位置就进行扩容,之前元素的位置不会发生改变



总结
JDK7:
HashMap底层是数组加链表的形式
数组的默认长度为16,加载因子为0.75,也就是16*0.75=12(阈值)
当计算出元素的位置在数组中冲突时,那么会以链表的形式存储新的元素,新的元素插在链表的头部,然后将链表下移,也就是将数组中的值赋值给新来的元素,
当数组中12个位置被占据时(也就是达到了阈值),同时新插入的元素的插入位置不为空,就会进行扩容 2倍扩容,
扩容完之后重新计算所有元素的hash值,(会产生死锁)
JDK8:
HashMap底层是数组加链表加红黑树
数组的默认长度为16,加载因子为0.75,也就是16*0.75=12(阈值)
当计算出元素在数组中的位置相同时,则生成链表,并将新的元素插入到尾部,假如链表上元素超过了8个,那么链表将被改为红黑树,同时也提高了增删查效率
当数组元素个数达到了阈值,那么此时不需要判断新的元素的位置是否为空,数组都会扩容,2倍扩容
扩容完之后,之前的元素位置不会发生改变,也就不会产生死锁
Node为链表的节点,有next和prev两个指针,分别指向后一个和前一个
插入链表的顺序不同
链表会转变为红黑树
hash算法简化
resize(扩容)的逻辑修改(jdk7会出现死锁,jdk8不会)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









