







 本文详细介绍了VINS-Mono视觉惯性里程计(VIO)的后端优化过程,特别是基于滑动窗口的非线性优化。主要内容包括视觉重投影误差、IMU预积分误差以及边缘化(Marginalization)的先验残差。文章讨论了逆深度参数化在视觉误差中的作用,IMU预积分模型的构建,以及边缘化操作如何形成先验,保持系统优化的稀疏性。通过舒尔补分解,展示了如何快速求解矩阵并应用于多元高斯分布,以及如何在滑动窗口中有效地管理和更新信息矩阵。
本文详细介绍了VINS-Mono视觉惯性里程计(VIO)的后端优化过程,特别是基于滑动窗口的非线性优化。主要内容包括视觉重投影误差、IMU预积分误差以及边缘化(Marginalization)的先验残差。文章讨论了逆深度参数化在视觉误差中的作用,IMU预积分模型的构建,以及边缘化操作如何形成先验,保持系统优化的稀疏性。通过舒尔补分解,展示了如何快速求解矩阵并应用于多元高斯分布,以及如何在滑动窗口中有效地管理和更新信息矩阵。
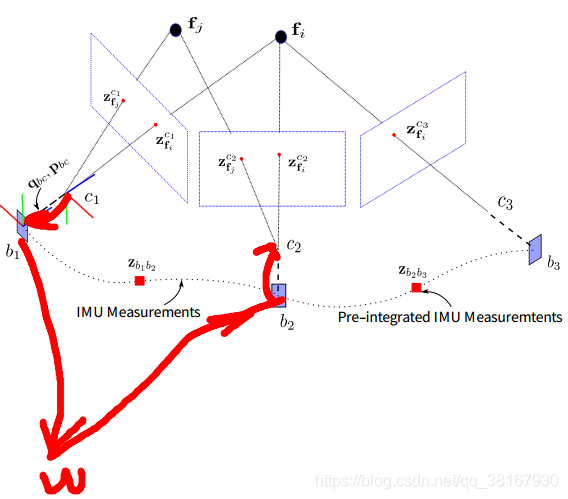
初始化后,采用基于滑动窗口的紧耦合单目VIO进行状态估计。首先来看VINS-Mono后端的整体思路:
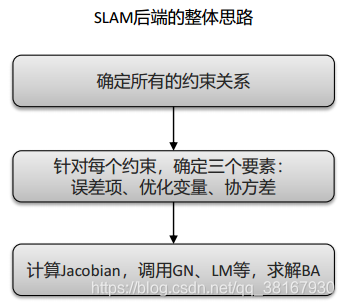
大道至简,思路比较简单,但是实现相当复杂。回顾BA三要素:误差项、优化变量、协方差。

简单说,VINS-Mono的误差来源于三部分,分别是来源于视觉的重投影误差,来源于IMU预积分的IMU误差(PVBQ的运动误差)以及来源于滑动窗口维护的边缘化操作带来的先验误差。
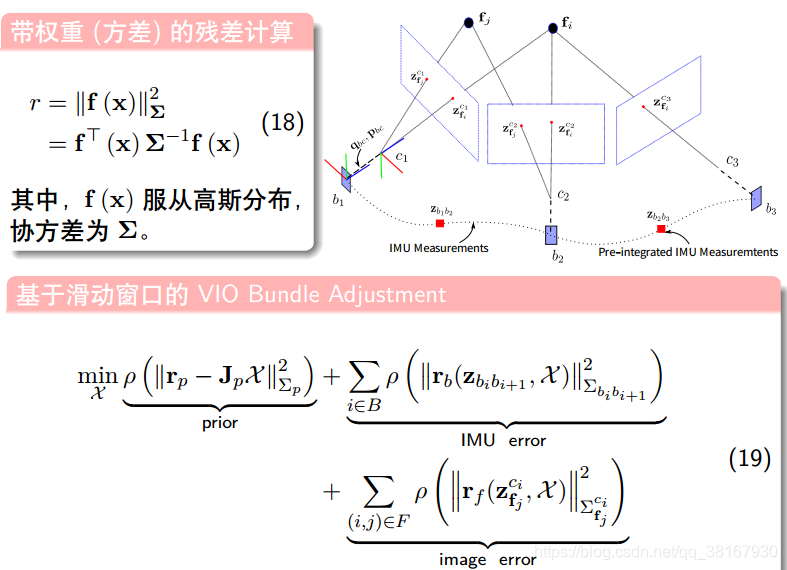
BA优化模型分为三部分:
1、Marg边缘化残差部分(滑动窗口中去掉位姿和特征点约束);
2、IMU残差部分(滑动窗口中相邻的IMU产生);
3、视觉代价误差函数部分(滑动窗口中特征点在相机下视觉重投影误差)。
其中,知识点涉及最多的是边缘化部分,理论比较多,放到最后讲,先记录一下视觉约束和IMU约束,如下:

0、系统需要优化的状态量
在正式介绍视觉约束之前,首先需要考虑的是,为了节约计算量,VINS采用滑动窗口形式的Bundle Adjustment,进行局部BA优化。举个例子来说,在i时刻,滑动窗口内的待优化的系统状态量定义如下:

其中:
包含i时刻IMU机体在惯性坐标系中的位置,速度,姿态以及IMU机体坐标系中的加速度和角速度的偏置量估计(IMU状态:PVQ、加速度bias、陀螺仪bias)、m+1个路标点、IMU到Camera的外参数;
- n,m分别是机体状态量,路标在滑动窗口里的起始时刻;
- N滑动窗口中关键帧数量;
- M是被滑动窗口内所有数量帧观测到的路标数量。
第一个式子是滑动窗口内所有状态量,n是帧数,m是滑动窗口内特征点总数。特征点逆深度为了满足高斯系统。
第二个式子是在第k帧图像捕获到的IMU状态,包括位置、速度、旋转(PVQ)、加速度计偏置、陀螺仪偏置。
第三个式子是相机外参。
xk只与IMU项和Marg有关;特征点深度只与camera和Marg有关。
1、视觉重投影误差(视觉残差)
一个特征点在归一化相机坐标系下的估计值与观测值的差。
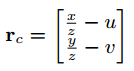
其中,待估计的状态量为特征点的三维空间坐标,观测值
为特征在相机归一化平面的坐标。
1.1 逆深度参数化
特征点在归一化相机坐标系与相机坐标系下的关系为:
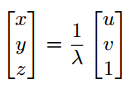
其中,=1/z称为逆深度。
问题:为什么使用逆深度?
逆深度(Inverse depth)是近年来SLAM研究中出现的一种广泛使用的参数化技巧。在演示程序中,我们假设深度值满足高斯分布:d~N()。然而这样做合不合理呢?深度的正太分布存在一些问题:
1. 我们实际想表达的是:这个场景深度大概是5~10米,可能有一些更远的点,但近似肯定不会小于相机焦距(或近似深度不会小于0)。这个分布并不是像高斯分布那样,形成一个对称的形状。它的尾部可能稍长,而负数区域为0。
2. 在一些室外应用中,可能存在距离非常远,乃至无穷远处的点。我们的初始值中难以涵盖这些点,并且用高斯分布描述它们会有一些数值计算上的困难。
逆深度应运而生,人们在仿真中发现,假设深度的倒数(也就是逆深度)为高斯分布是比较有效的。在实际应用中,逆深度也具有更好的数值稳定性,从而逐渐称为一种通用的参数化技巧,存在于现有SLAM方案中的标准做法中。
1.2 VIO中基于逆深度的重投影误差
特征点逆深度在第i帧中初始化得到,在第j帧中又被观测到,预测其在第j帧中相机归一化坐标系下的坐标为:
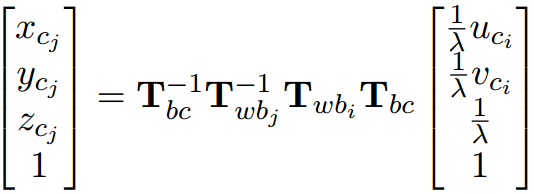
视觉重投影误差为:
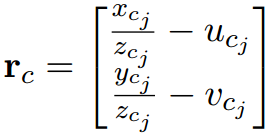
1.3 视觉重投影残差的Jacobian
视觉残差如下:
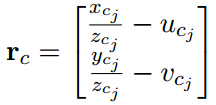
对于第i帧中的特征点,它投影到第j帧相机坐标系下的值为:
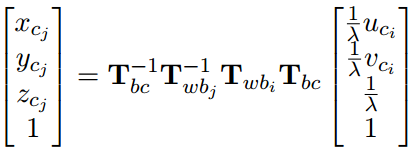
拆成三维坐标形式为:
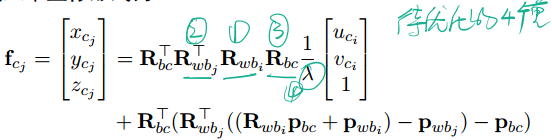
再推导各类Jacobian之前,为了简化公式,先定义如下变量:
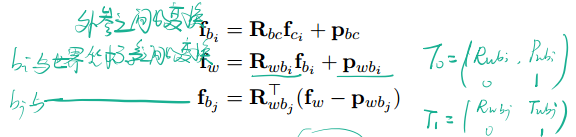
Jacobian为视觉误差对两个时刻的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











