







如果在maven项目里写sql的话需要引入cdc的依赖
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
</dependency>
建mysqlcdc的flinktable
CREATE TABLE cdc_mysql_source (
id bigint
,name VARCHAR
,age int
,sex VARCHAR
,address VARCHAR
,PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'xxx',
'port' = 'xxx',
'username' = 'xxx',
'password' = 'xxx',
'database-name' = 'xxx',
'table-name' = 'xxx'
);
这个地方前提是mysql要开启bin-log日志,且username不是root的话,需要给该用户全库全表的权限,如下赋权
GRANT ALL ON *.* TO 'xxx'@'%';
创建kafka的flinktable表
create table `kafka_sink`(
id bigint,
name STRING,
age int,
sex STRING,
address STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = 'xxx',
'properties.group.id' = 'xxx',
'topic' = 'xxx',
'format' = 'debezium-json'
)
如果要写入的话直接insert即可
insert into kafka_sink select * from cdc_mysql_source ;
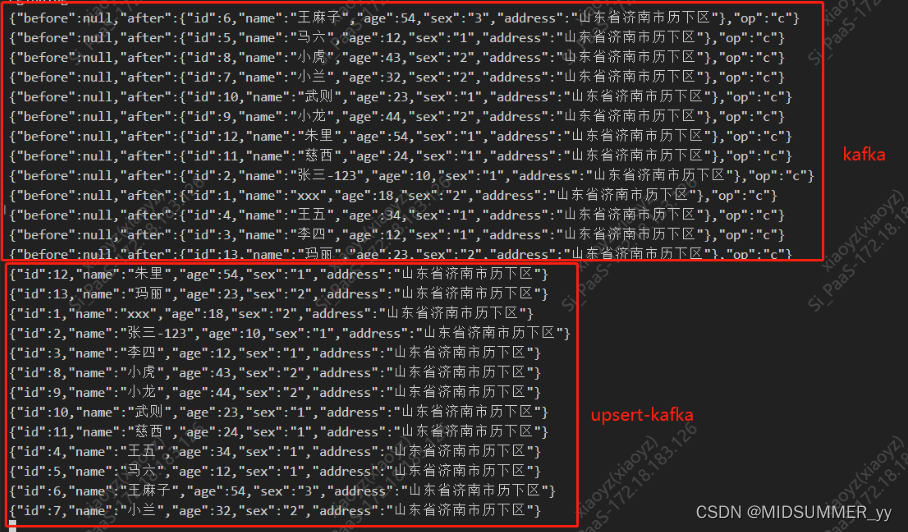
这里connector的类型可以是upsert-kafka
建表时其他信息都是一样的,不同的是存放在topic里的数据格式会有不同
在这里插入图片描述
如果写入doris的话在maven项目里也需要先导入依赖
<dependency>
<groupId>org.apache.doris</groupId>
<artifactId>flink-doris-connector-1.13_2.12</artifactId>
<version>1.0.3</version>
</dependency>
建doris的flinktable
CREATE TABLE doris_sink (
id bigint,
name STRING,
age int,
sex STRING,
address STRING
)
WITH (
'connector' = 'doris',
'fenodes' = 'xxx',
'table.identifier' = 'xxx.xxx',
'username' = 'root',
'password' = 'xxx'
);
fenodes要填的是FE的http端口,且这里的用户密码是登录http的root账号及密码
同理将mysql的数据直接跟doris实时同步只需要执行insert
insert into doris_sink select id,name,age,sex,address from cdc_mysql_source;
将数据写入iceberg,以hadoop_catalog为例
首先需要建catalog
CREATE CATALOG hadoop_catalog
WITH (
'type' = 'iceberg',
'warehouse' = 'hdfs://xxx:xxx/xxx',
'catalog-type' = 'hadoop'
)
查看所有库
show databases;
查看所有catalog
show catalogs;
创建iceberg的flinktable表
CREATE TABLE if not exists hadoop_catalog.icebergTest.icebergtest
(
id bigint,
name STRING,
age int,
sex STRING,
address STRING,
PRIMARY KEY (id) NOT ENFORCED
)
WITH (
'format-version'='2',
'write.upsert.enabled'='true',
'write.metadata.delete-after-commit.enabled' = 'true',
'write.distribution-mode' = 'hash'
)
format-version为2时可以使iceberg支持更新操作
执行kafka到iceberg的写入
insert into hadoop_catalog.icebergTest.icebergtest /* OPTIONS('equality-field-columns'='id') */ select id, name, age, sex,address from default_catalog.default_database.kafka_sink;




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











