







1. C++中map与unordered_map
1.1 map
map是C++中的关联式容器,按照特定的顺序用过一个pair<key,value>组合而成map容器的特点如下:
- map中的元素总是按照键值key进行比较排序的
- map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
- map通常被实现为平衡二叉搜索树(红黑树)。
接口函数
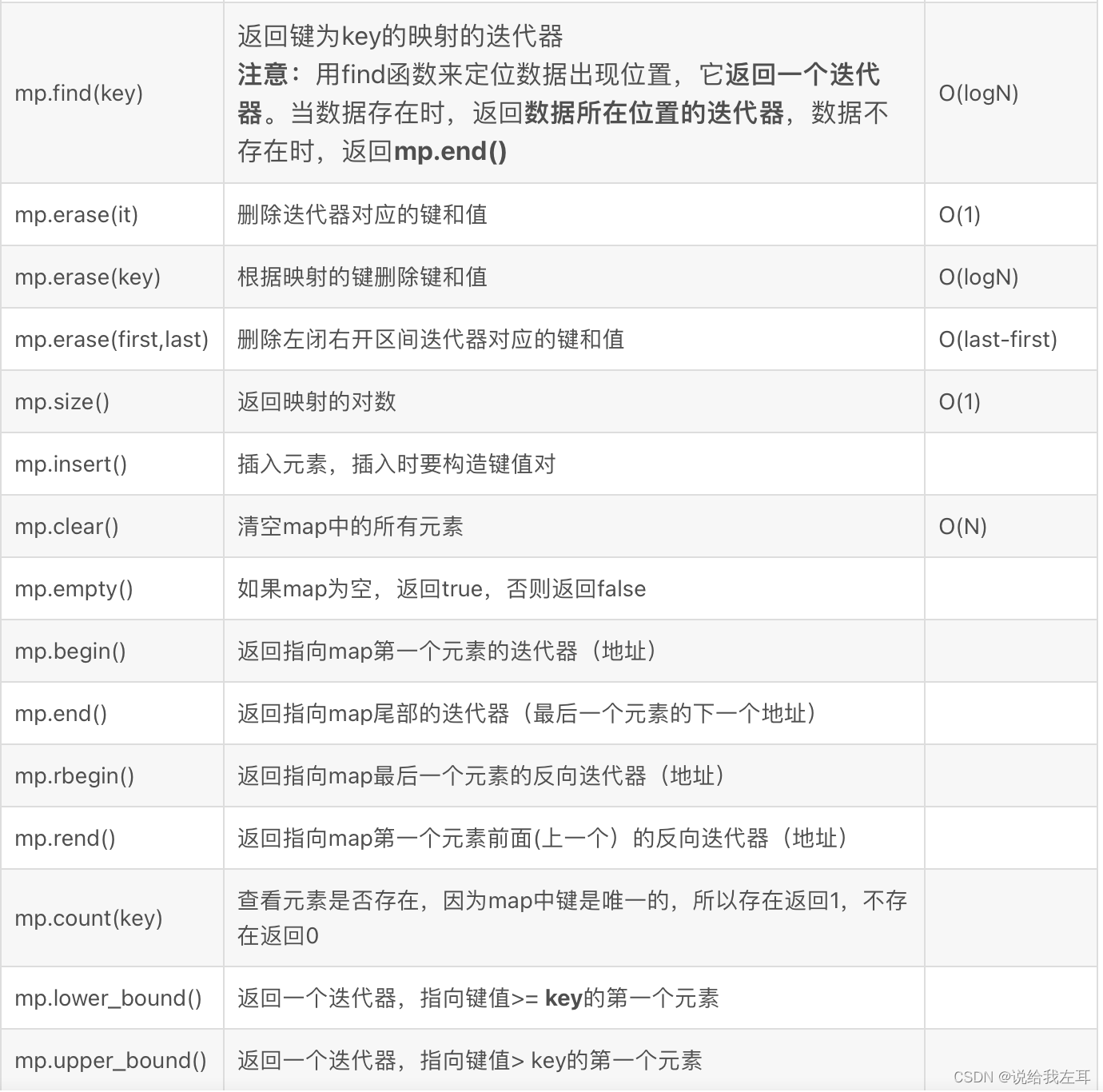
1.2 unorderd_map
unordered_map是一个关联容器,内部采用的是hash表结构,拥有快速检索的功能。特性如下:
- 关联性:通过key去检索value,而不是通过绝对地址(和顺序容器不同)
- 无序性:使用hash表存储,内部无序
- Map : 每个值对应一个键值
- 键唯一性:不存在两个元素的键一样
- 动态内存管理:使用内存管理模型来动态管理所需要的内存空间
详情请看:https://blog.youkuaiyun.com/xiaoyu_wu/article/details/121490312
2. Hot100中hashmap题目
题单
无重复字符的最长子串
两数之和
二叉树中序遍历
最小覆盖子串
和为k的数组
每日温度
只出现一次的数字
前k个高频元素
最大矩形
找到字符串中所有字母异位词
字母异位词分组
2.1 每日温度

解法一:暴力双循环(超时)
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
int n = temperatures.size();
vector<int> res(n);
res[n-1] = 0;
for(int i=0; i<n; ++i){
for(int j=i+1; j<n; ++j){
if(temperatures[i] < temperatures[j]){
int ans = j - i;
res[i] = ans;
break;
}else if((temperatures[i] >= temperatures[j]) && j == n){
res[i] = 0;
}
}
}
return res;
}
};
解法二:hash_map
可以看出暴力解法存在着不少重复运算,每一次都需要把i+1后面的数组重新遍历一遍。我🚪考虑到一种最极端的情况下:
[1,1,1,1,1,1,1,1,1,2] 这个数组的ans应该为[9,8,7,6,5,4,3,2,1,0]。那么我们不妨利用hashmap来存储天气与对应的下标值,注意温度为key,下标为value。
此时在有重复天气的时候不用每次遍历,只需要向哈希表中取值并且更新hashmap就可以了。
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
int len = temperatures.size();
vector<int> ans(len); // 存储结果的数组
unordered_map<int, int> tbl; // 使用哈希表记录温度值和对应的索引
for (int i = 0; i < len; i++) {
auto t = tbl.find(temperatures[i]); // 查找当前温度在哈希表中的记录
// 如果找到了记录
if (t != tbl.end()) {
// 如果记录中的索引大于当前索引,说明已经找到下一个温度更高的日子
if (t->second > i) {
ans[i] = t->second - i;
continue;
}
// 如果记录中的索引为 -1,说明已经遍历过数组但未找到更高温度的日子
if (t->second == -1) {
continue;
}
}
// 遍历当前温度之后的数组
for (int j = i + 1; j < len; j++) {
// 如果找到了下一个温度更高的日子
if (temperatures[j] > temperatures[i]) {
ans[i] = j - i; // 记录两天之间的间隔
tbl[temperatures[i]] = j; // 更新哈希表中的记录
break;
}
}
// 如果 ans[i] 仍然为 0,说明在之后的日子中未找到更高温度
if (ans[i] == 0) {
tbl[temperatures[i]] = -1; // 记录为 -1,表示已经遍历过但未找到
}
}
return ans;
}
};
解法三:单调栈
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
int n = temperatures.size();
vector<int> res(n);
// 栈内存放的是天气的下标数量
stack<int> stk;
for(int i=0; i<n; ++i){
while(!stk.empty() && temperatures[i] > temperatures[stk.top()]){
//当第一个天气大与栈顶元素出现时候,当前栈顶元素对应的res值为
//出现大于它天气元素的下标数 - 他自身的下标数
res[stk.top()] = i - stk.top();
stk.pop();
}
// 入栈
stk.push(i);
}
return res;
}
};
2.2 只出现一次的数字
方法一:哈希辅助表
思路:若第一次出现,插入哈希集,第二次出现,冲哈希集内删除,最后剩下的就是那个只出现一次的数字。
class Solution {
public:
int singleNumber(vector<int>& nums) {
unordered_set<int> ust;
int ans;
for(auto x : nums){
if(ust.count(x)){
ust.erase(x);
}else{
ust.insert(x);
}
}
for(auto m : ust){
ans = m;
}
return ans;
}
};
解法二:异或运算
异或运算特点:相同两个数异或之后为0。任何数字与0异或之后等于本身。异或运算满足交换律结合律。
那么此题中的数字可以抽象为:[a,a,b,b,c,c,…,x],也就是说数组中这些数字一起异或结果为x,也就是多余数字本身。
class Solution {
public:
int singleNumber(vector<int>& nums) {
int x = 0;
for (int num : nums) // 1. 遍历 nums 执行异或运算
x ^= num;
return x; // 2. 返回出现一次的数字 x
}
};
2.3 前K个高频元素

解法一:哈希表+优先队列
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
//1.map记录元素出现的次数
unordered_map<int,int>map;//两个int分别是元素和出现的次数
for(auto& c:nums){
map[c]++;
}
//2.利用优先队列,将出现次数排序
//自定义优先队列的比较方式,小顶堆
struct myComparison{
bool operator()(pair<int,int>&p1,pair<int,int>&p2){
return p1.second>p2.second;//小顶堆是大于号
}
};
//创建优先队列
priority_queue<pair<int,int>,vector<pair<int,int>>,myComparison> q;
//遍历map中的元素
//1.管他是啥,先入队列,队列会自己排序将他放在合适的位置
//2.若队列元素个数超过k,则将栈顶元素出栈(栈顶元素一定是最小的那个)
for(auto& a:map){
q.push(a);
if(q.size()>k){
q.pop();
}
}
//将结果导出
vector<int>res;
while(!q.empty()){
res.emplace_back(q.top().first);
q.pop();
}
return res;
}
};


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









