元字符
-
\\ 转义号
使用正则表达式去检索某些特殊字符的时候,需要用到转义符,java中两个\\代表其它语言中的一个\,需要用到转义的字符有 .*+()$/?[]^{}
-
元字符-字符匹配符
| 符号 | 描述 | 示例 | 解释 | 匹配输入 |
|---|
| [ ] | 可接收的字符列表 | [efgh] | e,f,g,h中的任意一个字符 | |
| ^ | 不可接收的字符列表 | [^abc] | 除abc之外的任意一个字符,包括数字和特殊符号 | |
| - | 连字符 | [A-Z] | 任意单个大写字母 | |
| . | 匹配除\n以外的任意字符,如果匹配.本身,则使用\\. | a…b | 以a开头b结尾中间包括两个任意字符的长度为4的字符串,一个.占一个字符 | aaab,aefb |
| \\d | 匹配单个数字,相当于[0-9] | \\d{3}(\\d)? | 包含3个或4个数字的字符串 | 123,1234 |
| \\D | 匹配单个非数字,相当于[^0-9] | \\D(\\d)* | 以单个非数字字符开头,后接任意个数字字符串 | a,a123,a789 |
| \\w | 匹配单个数字,大小写字母,下划线,相当于[0-9a-zA-Z_] | \\d{3}\\w{4} | 以3个数字开头,长度为7的数字字母字符串 | 234abcf |
| \\W | 匹配单个非数字,大小写字母,下划线,相当于[^0-9a-zA-Z_] | \\W+\\d{2} | 以至少一个非数字字母字符开头,两个数字字符结尾的字符串 | #29,#?@10 |
| \\s | 匹配任何空白字符(空格,制表符等) | \\s+ | 匹配至少一个空白字符 | |
java正则表达式默认是区分大小写的,如何实现不区分大小写呢?
- (?i)abc 表示abc不区分大小写
- a((?i)b)c 表示只有b不区分大小写
- 元字符-选择匹配符
在匹配某个字符串的时候是选择性的,既可以匹配这个又可以匹配那个这时候需要用到选择匹配符号
| 符号 | 描述 | 示例 | 解释 |
|---|
| | | 匹配|之前或之后的表达式 | ab|cd | ab或者cd |
- 元字符-限定符
| 符号 | 描述 | 示例 | 解释 | 匹配输入 |
|---|
| * | 指定字符重复0次或n次 | (abc)* | 仅包含任意个abc的字符串 | abc,abcabc |
| + | 指定字符重复1次或n次 | m+(abc)* | 以至少1个m开头,后接任意个abc | m,mabc,mmmabcabc |
| ? | 指定字符重复0次或1次 | m+abc? | 以至少1个m开头,后接ab或abc | mab,mmabc |
| {n} | 可接收字符连续出现n次 | [abcd]{3} | 由abcd中的字母组成任意长度为3的字符串 | abc, adc |
| {n,} | 指定字符连续出现n次 | [abcd]{3,} | 由abcd中的字母组成任意长度不小于3的字符串 | abc, aaaadc |
| {n,m} | 指定至少n个,但不多于m次匹配 | [abcd]{3,5} | 由abcd中的字母组成任意长度不小于3,不大于5的字符串 | abc, aaaad,abcd |
java 匹配默认为贪婪匹配,尽可能匹配多的,如:
String content = "1111aaaaaab"
String regStr = "a{3,4}"
Parttern parttern = Parttern.compile(regStr)
Matcher matcher = partterm.matcher(content)
while(matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
当?紧随其它任何限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式为非贪婪匹配,非贪婪匹配匹配搜索到的尽可能短的字符串,而默认的贪婪匹配则匹配尽可能长的字符串,如,在字符串ooooo中,"o+?"只匹配单个o,而"o+"匹配所有的o。
- 元字符-定位符
定位符,规定要匹配的字符串出现的位置,比如在字符串开始还是结束的位置
| 符号 | 描述 | 示例 | 解释 | 匹配输入 |
|---|
| ^ | 指定起始字符 | ^[0-9]+[a-z]* | 以至少一个数字开头,后接任意个小写字母的字符串 | 123,6aa |
| $ | 指定结束字符 | ^[0-9]\-[a-z]+$ | 以一个数字开头,后接连字符-,并以至少一个小写字母结尾的字符串 | 1-a |
| \\b | 匹配目标字符串的边界 | han\\b | 这里说的边界指的是子串间有空格或目标字符串 | hanyuion sphan nnhan |
| \\B | 匹配目标字符串的非边界 | han\\B | 和\\b相反 | hanyuion sphan nnhan |
- 正则表达式-捕获分组
| 常用分组构造形式 | 说明 |
|---|
| (pattern) | 非命名捕获,捕获匹配到的子字符串,编号为零的第一个捕获是由整个正则表达式匹配的文本,其它捕获结果则根据左括号顺序从1开始自动编号 |
| (?<name>pattern) | 命名捕获,将匹配到的子字符串捕获到一个组名称或编号名称中,用于name的字符串不能包含任何标点符号 ,并且不能以数字开头,可以使用单引号代替中括号,例如:(?‘name’) |
- 正则表达式-非捕获分组
| 常用分组构造形式 | 说明 |
|---|
| (?:pattern) | 匹配parttern但捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配,这对于用or或字符(|)组合模式的情况很有用,例如:industr(?:y|ies)是比industry|industries更经济的表达形式 |
| (?=pattern) | 非捕获匹配,如:Windows(?=95|98|NT|2000)匹配Windows2000中的Windows但不匹配Windows3.1中的Windows |
| (?!pattern) | 非捕获匹配,匹配不处于parttern的字符串的起始点的搜索字符串,如:Windows(?!95|98|NT|2000) 匹配Windows3.1中的Windows但不匹配Windows2000中的Windows |
- 正则表达式-反向引用

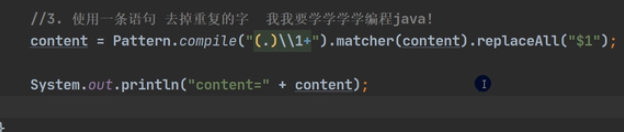
内部引用用\\
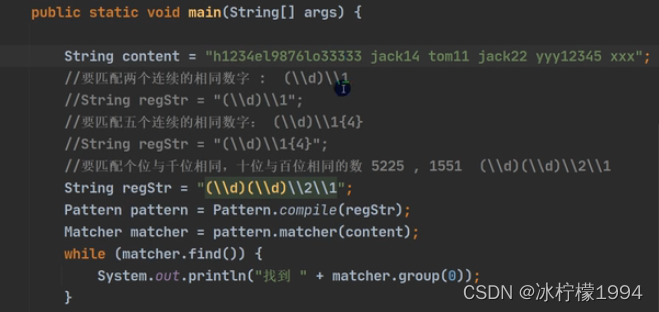
外部引用用$








 本文详细介绍了正则表达式中的元字符,包括转义符、字符匹配符、选择匹配符、限定符以及定位符的用法。通过实例解析了如何使用这些元字符进行字符串匹配,还提到了Java中的正则表达式不区分大小写的实现方式以及贪婪与非贪婪匹配的概念。此外,还讲解了捕获分组和非捕获分组的区别以及反向引用的应用。
本文详细介绍了正则表达式中的元字符,包括转义符、字符匹配符、选择匹配符、限定符以及定位符的用法。通过实例解析了如何使用这些元字符进行字符串匹配,还提到了Java中的正则表达式不区分大小写的实现方式以及贪婪与非贪婪匹配的概念。此外,还讲解了捕获分组和非捕获分组的区别以及反向引用的应用。

















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









