









 本文深入讲解Spark中的核心概念——弹性分布式数据集(RDD),包括其创建方式、数据形式及基本操作,如转换与行动操作,并探讨如何通过RDD进行数据处理。
本文深入讲解Spark中的核心概念——弹性分布式数据集(RDD),包括其创建方式、数据形式及基本操作,如转换与行动操作,并探讨如何通过RDD进行数据处理。
前言
继上篇博客介绍了Spark的安装,这里简单介绍RDD的概念,以及基本操作。
1. RDD含义
RDD中文名称为弹性分布式数据集,可以说Spark对数据的所有操作都是基于RDD的。
这里有个概念:驱动应用程序,是Spark运行的必要条件,在下面的操作演示中使用pyspark,即pyspark作为驱动应用程序。
RDD中的数据形式:根据书籍解释为以元素为单位,如文本内容的一行为一个元素、列表的一个值为一个元素。
RDD创建和操作:
- 创建
创建RDD可以有两种方式:
1)读取外部数据(如本地文件、HDFS文件等)
2)使用驱动应用程序内已有的数据(如列表、集合)
数据可以是任何类型、也可以是用户自定义对象。 - 操作
操作RDD也有两种方式:
1)转换
即从已有的RDD生成新的RDD。转换操作并没有对实际的数据进行计算(Spark中称为惰性),如filter。
2)行动
即实际的计算出RDD中的结果。如first。
2. 创建RDD
由于pyspark中默认已经初始化了SparkContext,其实例对象为sc,这里简单介绍在Python语法中如何自己初始化SparkContext。
- pyspark以初始化SparkContext

- 自己初始化-两种方式
1)较为复杂

2)简化操作

两个文件运行结果:
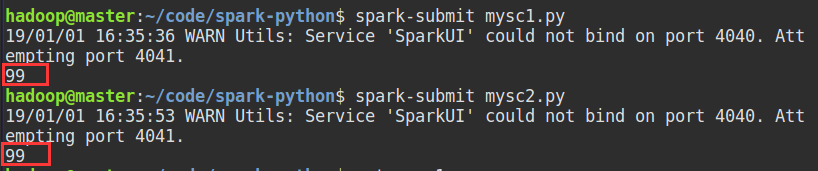
前面说了一大片都是讲初始化SparkContext(),如果是使用pyspark操作,那么使用默认的sc即可。如果将程序代码写到了.py文件中,那么就需要自定义创建。
从上面的实例中也可以看出,读取外部数据创建RDD就使用sc.textFile(filepath),下面介绍创建RDD的两种方式:
-
读取外部数据 - - sc.textFile()
-
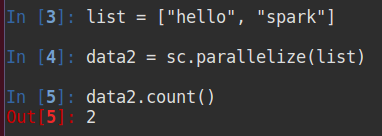
内部数据 - - sc.parallelize()
由于RDD的行动操作每次都需要重新执行,那么可以将一些需要重复使用的RDD持久化到内存中,两种方式:
1)RDD.cache()

2)RDD.persist()

3. 转换和行动操作
创建了RDD后,需要对其进行操作,以获得我们想要的数据。
- 转换
如上述data1中,该RDD定义了README.md文件中的所有内容,现在我们对其进行筛选,筛选出只包含"Spark"的行:

- 行动
这里使用RDD.take()函数,获取三个元素数据(书上说不一定是有序的):

时刻谨记,只有行动才会执行真正的计算,转换只保存了操作RDD的方式。
4. 向Spark传递函数
如上例中的:containSparkRDD = data1.filter(lambda line: “Spark” in line),参数中lambda即为一个函数,也可以改写为:
In [15]: def contains(line):
....: return "Spark" in line
....:
In [16]: wordRDD = data1.filter(contains)
In [17]: wordRDD.count()
Out[17]: 19

















 29
29

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









