




 本文介绍了如何使用Python的openpyxl库进行Excel文件的读取和写入,包括数据类型转换、创建Workbook和Sheet对象、单元格操作,以及批量数据处理。重点讲解了如何从xlsx文件中读取不同类型的数据并进行适当转换。
本文介绍了如何使用Python的openpyxl库进行Excel文件的读取和写入,包括数据类型转换、创建Workbook和Sheet对象、单元格操作,以及批量数据处理。重点讲解了如何从xlsx文件中读取不同类型的数据并进行适当转换。
操作excel的第三方库有:xlrd,xlwt, openpyxl,pandas
excel后缀:xls, xlsx
excel操作3个概念:
工作薄 workbook - 打开一个excel文件
表单 :sheet
单元格 :cell
pip安装第三方库
1、安装第三方库:pip
自动安装在Lib\site-packages
1、安装包:pip install 库名
2、卸载包:pip uninstall 库名
3、升级包:pip install -U 库名
4、如果要安装指定的版本号:pip install 库名==版本号
配置国内源:https://www.runoob.com/w3cnote/pip-cn-mirror.html
4、查看当前pip版本:pip --version
5、列出已安装的包:pip list
6、生成requirements.txt:pip freeze > requirements.txt 把本地的所有第三方库的东西都生成到这个文件中
7、安装requirements.txt:pip install -r requirements.txt 另外一台设备执行这个命令就可以获取到该项目所用的所有第三方库
从excel中读取到数据,
从excel当中读取出来的数据呢,
读取一个表单当中所有的数据
1、如果单元格当中只有数字,就会转成整数类型, 数字太长会转成字符串
2、如果单元格当中只有TRUE、FALSE,就会转成布尔值类型
3、如果单元格当中只有时间格式,比如2021/08/07,就会转成datetime类型。
4、如果单元格当中没有编辑数据,则会转成None。
一、openpyxl
搜索第三方库链接:https://pypi.org/
1、安装
pip install openpyxl
2、了解excel的操作步骤
- 找到目标excel
- 打开
- 读取数据、编辑excel单元格
- 保存
- 关闭
3、openpyxl操作excel
- 创建wb对象(找到excel并打开它)
- 找到Sheet对象(既要找到操作的工作簿)
- 找到要操作的单元格
- 读取数据、修改数据
- 保存、关闭
4、openpyxl支持的excel的格式
- xlsx
- xlsm
- xltx
- xltm
5、openpyxl的基本操作类
- Workbook:相当于一个文件夹-工作簿
- WorkSheet:相当于文件里面每个具体的表
- 比如新建Excel文件里面的’Sheet1’这个,一个Workbook里面有一个或多个WorkSheet.
1、读取已经存在的excel数据文件
导入 from openpyxl import load_workbook
2、创建一个excel数据文件,在里面写好你的测试数据。
3、加载一个指定的excel文件:wb = load_workbook(excel文件的路径)
4、选择一个表单。-- 通过表单名称。sh = wb['表单名称']
5、选择一个单元格。 -- 行号和列号从1开始。sh.cell(行号,列号).value
6、修改单元格的值。 sh.cell(行号,列号).value = 新的值
7、修改完成之后,一定要保存文件:wb.save(文件路径)。
请注意:文件不能够被其它程序占用。比如你在本地打开这个文件,那么保存时会提示没有权限。需要你关闭掉。
6、获取WorkBook对象
方式一:可以创建一个新的
# 导入模块
from openpyxl import Workbook
# 创建一个WorkBook
workbook = Workbook()
方式二、导入已经创建好的
# 导入模块
from openpyxl import load_workbook
# 导入一个WorkBook
wb = load_workbook("testCase.xlsx")
例子:获取excel中,login表中的第二行第二列
# 导入模块
from openpyxl import load_workbook
# 导入一个WorkBook
workBook = load_workbook("testCasesx")
# 获取sheet对象
sheet = workBook["login"]
# 找到要操作的单元格
cell = sheet.cell(row=2, column=2)
print(cell.value)
#关闭
workBook.close()
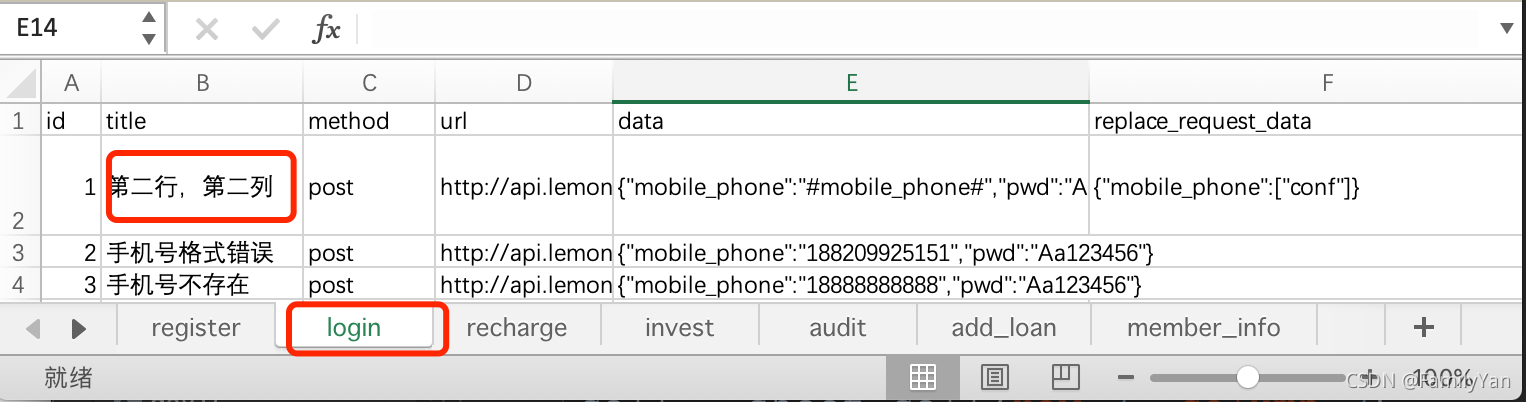
运行结果:

7、load_work方法中参数的含义
def load_workbook(filename, read_only=False, keep_vba=KEEP_VBA,
data_only=False, keep_links=True):
filename: excel文件名称(带路径)
read_only: 可读可写,默认是False,只读
keep_vba:保留vba代码
data_only: 默认False,有计算公式的单元格,直接读出来是公式
True:有公式的单元格读出来是计算后的结果
keep_links:保留各种表之间的链接
8、获取Sheet对象的几种方式
① sheet = workBook[“login”]
②sheets = workBook.sheetnames 返回一个list,包含所有的Sheet名称
③for sheetName in workbook: 遍历sheet对象
④res = workBook.worksheets[1] :根据索引获取要操作的单元格
9、找到要操作的单元格的方式
①cell= sheet["B2]
②cell = sheet.cell(row=2, column=2)
10、行操作
①获取所有行对象,并取每行每个单元格的值
workBook = load_workbook("testCase.xlsx")
sheet = workBook["login"]
row = sheet.rows # 获取所有行对象
for i in list(row):
print(i)
for ii in i:
print(ii.value) # 通过双层for循环,获取每行每个单元格对应的值
workBook.close()
11、获取最大行
# 获取最大行,某一行,输入东西了,又被删除, 但是该行也已经被激活了
workBook = load_workbook("testCase.xlsx")
sheet = workBook["login"]
maxRow = sheet.max_row
print(maxRow)
12、行切片
iter_rows(self,
min_row=None, 起始行的索引,索引从1开始,不写的话,默认是1
max_row=None, 结束行索引,不写的话默认是最大值
min_col=None, 起始列的索引
max_col=None, 结束列索引:不写的话默认是最大值
values_only=False) 返回单元格的值
workBook = load_workbook("testCase.xlsx")
sheet = workBook["login"]
for val in sheet.iter_rows(min_row=1, max_row=5, min_col=1, max_col=5, values_only=True):
print(val)
13、列操作
from openpyxl import Workbook
workBook = load_workbook("testCase.xlsx")
sheet = workBook["login"]
res = sheet.columns # 获取所有的列对象
maxColumn = sheet.max_column # 获取最大的列
print(maxColumn)
print(list(res))
# 列切片
for val in sheet.iter_cols(values_only=True):
print(val)
14、写表操作
单一写入,覆盖写
workBook = load_workbook(filename="testCase.xlsx")
loginSheet = workBook["login"]
# 方式一
loginSheet["A1"] = "test01" # 给A1单元格赋值
# 方式二
loginSheet.cell(row=1, column=2).value = "test02" # 给A1单元格赋值
# 方式三
loginSheet.cell(row=1, column=3, value="test03")
workBook.save(filename="testCase.xlsx")
# 批量写入新的内容
workBook = load_workbook(filename="testCase.xlsx")
loginSheet = workBook["login"]
# 在表格最下面去写,按行写入,每一个元素占用一个单元格
test_list = [1, 2, 3, 4, 5]
loginSheet.append(test_list)
workBook.save(filename="testCase.xlsx")
获取一个excel表的所有测试用例
from openpyxl import load_workbook
workBook = load_workbook(filename="testCase.xlsx")
loginSheet = workBook["login"]
excel_all_data = list(loginSheet.iter_rows(values_only=True))
excel_title = excel_all_data[0] # 获取表头
case_data_list = excel_all_data[1:] # 获取所有的用例数据
test_case_list = [] # 新建空的列表,收集所有的测试用例
for case in case_data_list:
print("表头:", excel_title)
print("测试用例:", case)
test_case = dict(zip(excel_title, case)) # 数据拼接,用表头与测试用例拼接,成dict
test_case_list.append(test_case) # 将每次收集好的用例,添加到新的列表中
print("拼接后的数据:", test_case)
print(test_case_list)
workBook.close()

















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









