







一、从一个经典的程序理解可见性
public class Visibility {
public static boolean flag = true;
public static void main(String[] args) throws InterruptedException {
new Thread(()->{
while (flag){
}
System.out.println("thread end!");
}).start();
Thread.sleep(1000);
flag = false;
}
}
这个小程序中主程序和新开启的一个线程共享一个flag变量,我现在在主程序中修改共享变量flag,新开启的线程会立刻感知到主线程已经修改了共享变量吗?你可以试一试这个例子中是不会的。那要怎么做才能使新线程立即感知到呢?很简单,在共享变量签加上volatile修饰就可以了。就像下面:
public class Visibility {
public static volatile boolean flag = true;
public static void main(String[] args) throws InterruptedException {
new Thread(()->{
while (flag){
}
System.out.println("thread end!");
}).start();
Thread.sleep(1000);
flag = false;
}
}
第一个程序由于不能感知到主线程修改共享变量而一直在等待,而为什么不能感知到就要了解CPU的结构和运行原理。从结构上看当代CPU大部分都是多颗核心的,两个线程可以在不同的核心上执行。CPU有三级缓存,它的工作原理为:当CPU从主内存中读取变量时,先读到L3 缓存中,再加载到L2缓存中,然后读取到L1缓存中,最终才读取到寄存器中做计算。CPU中各级缓存的存取速度Register>L1>L2>L3>主内存。从图中可以看出每个核心有自己的L1、L2缓存,共享L3缓存。有了以上基础,就可以解释为什么在主线程中修改共享变量对子线程不可见了。程序一开始运行时,flag在主内存中,主线程会将flag读到自己的缓存中,假设为CPU1,而子线程读取flag变量时也是从主内存读取的,假设读取到CPU2,不存在两个核心相互通信而同步变量。所以我在CPU1中修改flag对CPU2不可见就很正常了。

那在共享变量加上volatile为什么就可以了?是这样的:
volatile修饰的变量在写操作时,其汇编代码会多出一行Lock前缀的代码,在IA-32架构软件开发者手册里可以查到Lock前缀指令在多核处理器下会引发两件事情 1) 将当前处理器缓存行的数据写回到主内存中。2) 这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据失效。所以在第二个例子中由于加上volatile的修饰,子线程在读取flag时发现flag已经失效了,于是再从主内存读取,这时flag已经是CPU1更新过后的值了,CPU2可以读到最新的flag,可以正常退出。
所以,在多线程程序中,要想实现共享变量的立即可见,需要加上volatile修饰。
二、有序性
这篇短文只从volatile聊聊有序性,还是从一个经典的小程序讲起:
public class VolatileTest {
public static int x=0,y=0;
public static int a=0,b=0;
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 100000000; i++) {
CountDownLatch countDownLatch = new CountDownLatch(2);
a = 0;b = 0;
x = 0; y = 0;
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
a = 1;
x = b;
countDownLatch.countDown();
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
b = 1;
y = a;
countDownLatch.countDown();
}
});
t1.start();
t2.start();
System.out.println(i);
countDownLatch.await();
if (x==0&&y==0){
System.out.println("第"+i+"次循环 "+"x = 0"+", "+"y = 0");
break;
}
}
}
}
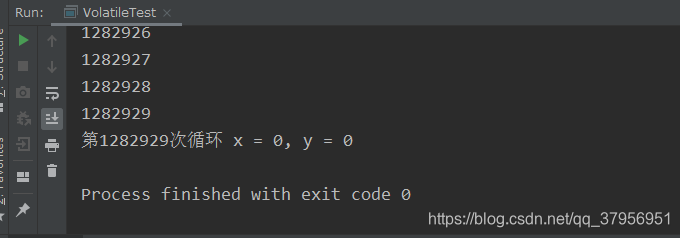

在同一个线程里代码按顺序执行,总共有以上6种情况,怎么会出现x=0,y=0呢?
只可能是CPU将x=b放在a=1之前执行了,这就是编译器为了执行效率所做的指重排优化。而volatile能够禁止指令重排序。这种重排序不会使程序的执行结果出错吗?答案是在单线程中指令重排的原则是不改变单线程执行的语义,即使重排序了,也不会使结果发生变化。所以在单线程中这种指令级重排序不会影响程序执行结果,在多线程中就会出现如上述的意料之外的结果(当然从上面的程序可以看出来,发生指令重排序的概率也是很小的)。volatile可以通过加内存屏障的方式来禁止指令重排序。

关于有序性,不得不说到DCL(double check lock)单例:
class DCL_Singleton{
public static volatile DCL_Singleton instance = null;
private DCL_Singleton(){}
public DCL_Singleton getInstance(){
// 防止由于指令重排,而使用未初始化的对象。也可以节约加锁的开销
if (instance == null){
synchronized (DCL_Singleton.class){
if (instance == null){
instance = new DCL_Singleton();
}
}
}
return instance;
}
}
三、原子性
原子性:一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
举个例子来说,A给B转账500元,这个过程可以分解为 1) A的账户减500, 2) B的账户加500. 如果A的账户减了500,B的账户却没有加500,那就有问题了,所以这两步操作要么都执行,要么都不执行。下面的代码是两个线程同时对一个变量做加法,各加10000次,看看结果是什么?
public class AtomicTest {
public static int count = 0;
public static CountDownLatch countDownLatch = new CountDownLatch(2);
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
count++;
}
countDownLatch.countDown();
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
count++;
}
countDownLatch.countDown();
}
});
t1.start();
t2.start();
countDownLatch.await();
System.out.println("count = " + count);
}
}
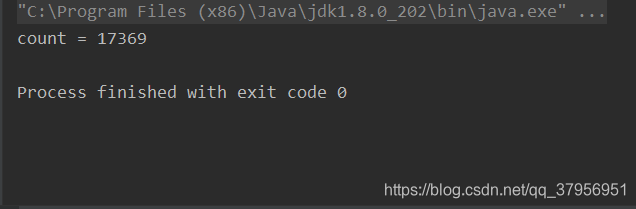
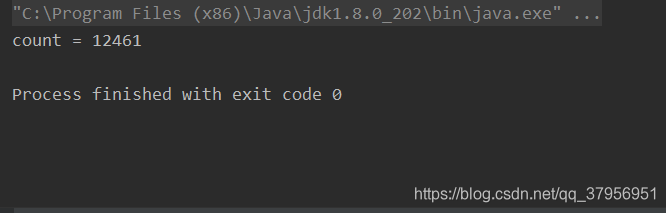
每次执行结果都不一样,而且肯定小于等于20000.这是因为加法操作就不是原子操作。A线程先将count读到自己的工作内存,进行加1,B线程也将count读到自己的工作内存,进行加1,这时,两个线程里面的count都为1,A线程将count回写到主内存,count = 1,B也将count回写到主内存,count = 1。我做了两次加法count应该为2,但B线程会覆盖A线程的值。所以结果总是偏小的。
总结
这篇短文主要介绍多线程会出现的问题,对其出现的奇怪现象做了初步解释,后续会对volatile的原理做深入的分析。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









