







Rank-embedded Hashing for Large-scale Image Retrieval
Haiyan Fu
School of Information and
Communication Engineering, Dalian
University of Technology
Dalian, China
Ying Li
∗
School of Computer Science and
Science and
Technology, Nanjing Normal
University
Nanjing,
Hengheng Zhang
Department of Computer Science,
University of Texas at San Antonio
San Antonio, Texas,
Jinfeng Liu
School of Information and
Communication Engineering, Dalian
University of Technology
Dalian, China
Tao Yao
Department of Information and
Electrical Engineering, LuDong
University
Yantai, China
摘要
随着Internet上图像的增长,开发了许多哈希方法来处理大规模图像检索任务。
散列方法将数据从高维映射到紧凑代码,因此它们可以有效地处理复杂的图像特征。
但是,哈希的量化过程导致不可避免的信息丢失。 结果,用生成的二进制代码来测量图像之间的相似度是一个挑战。 最新作品通常专注于同时学习深度特征和哈希函数,以保持图像之间的相似性,而相似性指标是固定的。在本文中,我们提
出了一种秩嵌入哈希(ReHash)算法,该算法将排名列表与监督哈希的反馈一起自动优化。
具体来说,
ReHash在端到端模型中共同训练度量学习和哈希码。以这种方式,通过排序处理来增强图像之间的相似性。
同时,排名结果也是对哈希函数学习的额外监督。大量实验表明,我 们的ReHash优于用于大型图像检索的最新哈希方法。
CCS概念
•信息系统→图像搜索。
关键词
图像检索; 深度监督哈希 图片排名; 大规模检索
1.引言
近年来,基于内容的图像检索备受关注[1、33、47、50]。 由于大数据在多媒体[2,34]中的挑战,散列成为检索[9,10,26,40,44]和索引[36,43]的热门话题。 散列技术是对近似最近邻居(ANN)搜索的一种流行解决方案,该搜索将高维数据转换为二进制代码序列。 由于哈希码通常由短位组成,因此它是一种有效的表示方式,尤其是在大规模图像检索任务中。
存在两种广泛研究的散列类别,即数据非独立方法和数据独立方法。局部敏感哈希(LSH)是一种代表性的独立于数据的哈希,它无需任何附加信息即可部署随机哈希函数。与数据无关的哈希不受训练,因此生成的哈希码与数据集无关。与这种广义的哈希表示相比,与数据相关的哈希通常通过与特定数据密切相关的基于训练的哈希函数来实现更高的准确性。结果,依赖数据的散列在实际应用中更为有用。
依赖数据的哈希也称为学习哈希(L2H),其目的是学习适当的哈希函数,以使生成的哈希码之间的相似度与真正的最近邻居搜索结果一致。尽管L2H是基于讯联的,但并不总是由标签来监督。 在最近的研究中,基于学习的哈希码是以两种不同的方式生成的。没有训练标签,通过线性或非线性投影开发无监督的哈希函数。无监督散列速度很快,并利用图像内容进行学习,但是,不包含信息标签以进行训练。 相反,监督哈希可以从语义标签中学习,从而显着改善图像检索结果。
先前的研究已经注意到了紧凑代码生成的重要性,实际上这是图像检索的第一步。为了通过散列进行检索,通常对用于ANN搜索的散列码执行类似度量的策略,例如散列表查找和散列码排名。随着深度学习的发展,深度监督哈希技术已经见证了大规模图像检索的快速增长。但是,在大多数现有作品中,排名步骤仍与散列分开。尽管有几篇著作将度量学习作为监督散列中的松弛项引入,但哈希代码仍然是通过一步取统一损失函数的导数来导出的,这会导致量化误差。有效地,我们开发了一种排名嵌入哈希(ReHash)方法,其中通过端到端联合学习获得优化的检索结果。
我们的方法的框架如图1所示。与现有的基于散列的图像检索方法相比,本文的主要贡献主要体现在三方面。
-
我们提出了一种针对深度监督哈希的端到端联合学习模型,该模型将紧凑的代码投影与深度度量学习相结合。 通过将图像排序过程嵌入到深层监督的非对称哈希步骤中,ReHash以较短的代码位和较低的时间成本实现了卓越的性能。
-
据我们所知,ReHash是第一个以两步方式将深度度量学习与离散哈希结合在一起的方法,其中采用拉普拉斯矩阵来连接图像排名和深度监督哈希。更具体地说,采用基于排名的损失,因为它可以使图像检索任务受益,并且可以针对目标问题将其概括为其他度量。
-
在三个基准测试上的实验表明ReHash在大规模图像检索中的有效性和效率,表明它可以在实际应用中使用。
2.相关工作
关于数字图像的爆炸性增长,越来越难以忽视大规模图像检索的挑战。作为可扩展ANN搜索的最广泛使用的解决方案之一,由于其高时间效率和低存储成本,哈希[18]受到了相当大的关注。无需学习就可以进行早期哈希处理的方法是,通过随机哈希函数简单地从头开始量化特征。 由于局域敏感度属性及其对距离度量的扩展,更快的投影,较小的存储,多个分配索引等的约束,数据独立的哈希方法为简化图像匹配付出了巨大的努力。
尽管它们的效率很高,但是这些基于LSH的方法的检索精度很差。因此,已经开发了各种基于训练的算法并将其引入到数据相关的哈希中。
由于训练数据可用,因此学习哈希的目的主要是保留哈希投影中的相似关系。 根据原始空间中给出的相似性形式,与数据相关的哈希可以分为两类,包括非监督哈希和监督哈希,其中原始相似性分别通过计算距离或语义标签来衡量。对于无监督散列,在大多数工作中,例如光谱散列[48],迭代量化(ITQ)[13]和各向同性散列[20],欧几里德距离是相似性度量的常见选择。 此外,在哈希空间中,欧几里德距离与高效率的汉明距离一致。除了成对距离之外,在图模型上还进一步探索了相似性,例如离散图哈希[31],可伸缩图哈希[16]和频谱哈希图扩展[25,54]。
由于训练数据的限制,在数据传输过程中,无监督的哈希将导致不匹配。与那种情况相比,监督散列易于获得更高的检索准确性,因为它可以求助于标签以获取更广义的语义信息。
为了保持标签的相似性,设计了许多手工制作的哈希函数以最小化相似性之间的差异[19、28、32、39、51]。 另外,非对称散列方法被开发用于更多的变体[35,41]。
同时,深度学习的巨大成功导致了深度监督哈希[11,23,52],它可以在同一深度神经网络中学习紧凑的哈希码以及图像特征。深度模型训练中广泛使用的损失函数包括成对差异最小化[27],三重态损失[23,52]和标量量化[8]。 由于深度学习是基于大数据的,因此通过在大规模数据集上训练深度模型,深度哈希方法可以大大胜过非深度哈希方法。但是,训练深度模型通常很耗时,尤其是在大型数据集上。
为了提高训练效率,在这种情况下,不对称学习的思想也被解释为深度不对称学习[8,17]。
然后,一个新的问题是在时间成本和检索准确性之间进行权衡。
在本文中,我们以不对称方式研究了深度度量学习和深度监督哈希,
旨在提高大规模图像检索的准确性,同时又不增加时间成本。
3.嵌入排序哈希
3.1问题定义
在一个图像检索系统中,假设我们有一个数据库(图库)由𝑁图像样本I𝐺={𝐼𝑖}𝑖𝑁=1组成,给定一组𝑀查询图像I𝑄={𝐼𝑖}𝑖𝑀=1,我们的目标是通过每个图像的二进制哈希码B𝐺∪𝑄={𝑏𝑖}𝑖𝑀=1+𝑁∈{1,1}𝜂×(𝑀+𝑁)在图库中搜索语义最相似的图像。我们的方法是在深度监督哈希的框架下提出的,它利用深度神经网络从数据库中学习一个非线性哈希函数F:I→B。监督信息通常由图像的语义标签提供,并表示为成对结构S={𝑆𝑖𝑗}∈{-1,+1}。𝑆𝑖𝑗=1表示图像𝐼𝑖和图像𝐼𝑗相似,而𝑆𝑖𝑗=-1表示图像𝐼𝑖和图像𝐼𝑗不相似。
3.2模型
值得注意的是,从整个数据库的成对关系中进行有监督的哈希学习总是不切实际的,原因有两个。首先,现实世界中的数据库可能非常庞大,只有一部分可用于训练。
第二,即使在实验环境中,训练过程也很难进行从冗余对中受益,甚至恶化,同时遍历大规模数据集中的所有对也非常耗时。因此,
许多监督哈希方法[3、5、53]在数据库的采样子集中学习哈希函数
。
在本文中,我们采用了最近提出的非对称深度监督哈希算法[17,38]来解决这个问题。具体来说,模型由两部分组成。第一个组件是一个深度神经网络,它可以以可区分的方式学习二进制哈希的代表特征。该深度学习步骤是在数据库的子集Ω中进行的,其余数据库/Ω的哈希码在第二个组件中进行了离散优化,目的是保留Ω和/Ω之间的相似性信息。这两个部分在各自的数据库段上不对称地工作,同时通过所提出的排序嵌入目标函数进行连接,并且可以交替进行优化。
通过这种端到端的培训框架,我们能够以有效和高效的方式学习深度哈希函数。图1说明了我们方法的流程。

3.3深度架构
深度架构,即我们的排名嵌入式哈希模型的第一部分,是从AlexNet [22]修改而来的卷积神经网络(CNN),该网络最初包含五个卷积层和三个完全连接的层。最后一层被具有𝜂个单位的哈希层替换,该哈希层将要素表示映射到R𝜂空间。双曲正切(tanh)激活层附加在末尾,以进一步强制输出保持在{-1,1}内。
因此,期望网络在训练过程中产生近似的𝜂-
bit二进制代码,同时保持可区分性。另外,最近提出了越来越多的CNN结构[15],它们具有可靠的提取语义特征的能力,可以肯定地提高哈希任务的性能。
但是,我们采用AlexNet作为骨干,以便与具有相同或接近深度架构的许多以前的方法进行合理的比较,例如 CNN-F [6],以证明我们提出的嵌入排序哈希方法的有效性。
3.4嵌入排序的哈希学习
对于检索系统,有效的度量学习方案可以捕获数据中的语义特征并获得更好的检索结果,即保留相似性信息的排名列表。 最近除了广泛使用的成对度量标准外,例如 对比损失[14],则研究了数据之间更复杂的结构关系[12、42、49]。 同时,一些散列工作也将这种结构化的度量目标集成到各种二进制代码学习方法中[30,46]。
受基于排名的度量标准[45]的最新研究的启发,我们希望将排名信息嵌入到哈希学习目标中。具体而言,本文做出了两点贡献。 首先,提出了一种排序嵌入式目标,该目标被很好地定义并容纳在非对称监督哈希框架中。其次,不同于先前的一些基于松弛优化哈希学习的结构化损失的文献[46],我们提出了一种用于离散哈希优化的通用度量嵌入公式。 它不仅可以很好地用于我们对CNN和二进制哈希码的联合学习,而且还有望解决其他度量损失。
嵌入排序的损失
如3.2节所述,数据库Ω的一个子集用于CNN训练,而其余/Ω则进行离散优化。现在,我们将以Ω为单位的每个图像x𝑖设置为锚点,并根据
/Ω中
所有图像到锚点的特征距离进行排序。在每个排序列表中,将结果归因于锚点的两个集合,基于相似性监督S,表示为正集P𝑖= {x𝑗| c𝑗=c𝑖,𝑖≠𝑗,x𝑗∈/Ω},负集N𝑖= {x𝑗| c𝑗≠c𝑖,x𝑗∈/Ω}。这里c𝑖是数据label的标签,并且采用了欧几里得距离。
为了从排名列表中提炼出学习目标,目的是将正向数据向前拉出,将负向样本推开,样本挖掘对于实现快速收敛和良好性能始终是必不可少的[37,42]。我们通过省略琐碎的数据进一步改善排名结果,并得到P𝑖= {x𝑗| c𝑗=c𝑖,𝑖≠𝑗,x𝑗∈Ω,𝑑𝑖𝑠𝑡𝑖𝑗>(𝛼-𝑚)}和N𝑖= {x𝑗| c𝑗≠c𝑖,x𝑗∈/Ω,𝑑𝑖𝑠𝑡𝑖𝑗<𝛼 }。请注意,x𝑖是CNN生成的训练数据的输出特征,而x𝑗实际上是数据库的二进制哈希码,稍后将以b𝑗表示。优化锚点集和数据库之间的距离关系会促使我们为如下所示的嵌入排序损失构建图拉普拉斯公式:
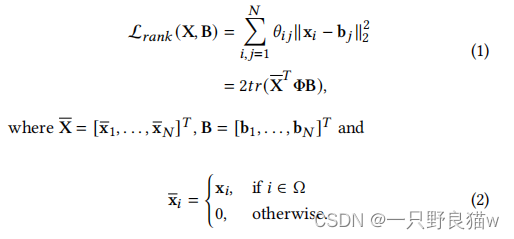
在此,𝜃𝑖𝑗是权重矩阵Θ的元素,其指示距离图中的i和j之间的关系。Φ= D-Θ是图的拉普拉斯矩阵。D =𝑑𝑖𝑎𝑔(𝑑11,...,𝑑𝑁)是度矩阵,其中𝑑𝑖𝑖=Σ𝑗=1->N,𝑗≠𝑖 𝜃𝑖𝑗,tr(·)是迹运算。因此,排序指标嵌入𝜃𝑖𝑗中,定义如下:
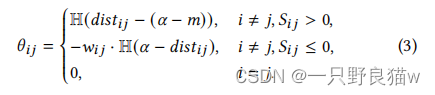
H(·)是单位阶跃函数,对于正参数,其值为1;对于负参数,其值为0。由于数据库中存在大量负关系,因此添加了w𝑖𝑗。因此,我们提出根据损失值对每个锚点的负样本进行加权。数学上,
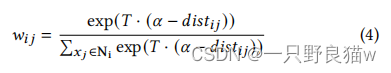
其中参数𝑇控制加权影响的程度。
通过用L2范数用内积和量化损失来表示汉明距离,我们有
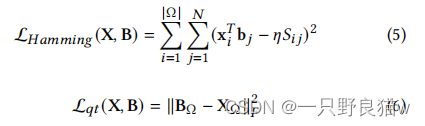
最后,通过最小化提出的嵌入排序损失等式(1)以及汉明距离损失方程 (5),量化损失等式(6)来制定我们完整的哈希学习目标。目标函数表示如下,
其中𝜔和𝛾是加权超参数。
固定B学习X。我们的算法包括两个替代的优化步骤。此步骤是学习X,它是CNN组件的输出。在计算等式(7)的梯度后,应用反向传播算法来自训练数据小批次的X。简而言之,当固定B时,它与常规神经网络学习的过程相同。
固定X学习B。此步骤是离散优化,这是NP难题。 我们表达等式(7)以矩阵形式:
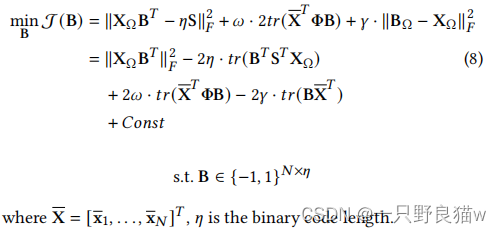

我们采用离散循环坐标下降法(DCC)逐位学习B。 具体而言,令b'是B的,而B'是B的子矩阵,不包括b'。 同样,令q表示Q的Q列,而Q'表示Q的子矩阵(不包括q)。
再次让xΩ为XΩ的列,X'Ω为X的子矩阵(不包括xΩ)。 因此,我们可以每次更新B的一列,而固定其他列。 现在我们有
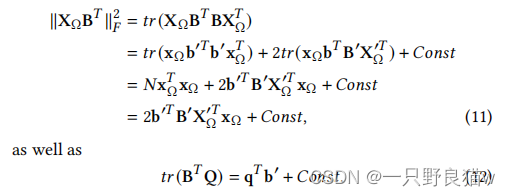
通过替换等式(9)与等式 (11)和等式(12)中的术语,问题进行了如下改革,
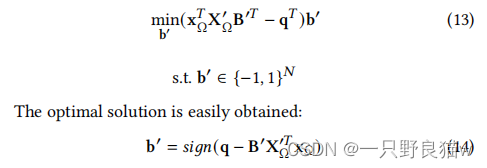
因此,每个比特b'可以迭代更新,直到收敛为止,我们在实验中将整个π-比特更新的次数设置为2。 完整的学习算法在算法1中进行了总结。
3.5样本外扩展
样本外数据包括训练数据以外的任何未见数据。 在有监督的哈希问题中,有必要为任何看不见的查询数据生成二进制哈希码,这是评估算法的关键步骤。与以前使用深度哈希框架进行的大多数工作类似,我们通过将测试数据通过一次正向传播馈送到训练有素的网络并应用符号函数来预测二进制哈希码:
4实验
在这一节中,我们将评估我们的Rerank嵌入式哈希(ReHash),并将其与其他哈希进行图像检索。
4.1数据集和评估指标
使用三个公共数据集评估ReHash方法,包括CIFAR-10 [21],NUS-WIDE [7]和MS-COCO [29]。
CIFAR-10:CIFAR-10数据集包含60,000张图像。 它是一个单标签数据集,其中每个图像都属于十个类别之一。
在实验中,我们随机选择1,000张图像(每类100张图像)作为测试数据,其余59,000张图像组成数据库。 如果任何两个图像共享相同的标签,则它们被视为相似对。
NUS-WIDE:NUS-WIDE数据集包含超过260,000张图像。 它是一个多标签数据集。 许多图像具有来自Flickr的多个标签。 整个数据集共有5,018个唯一标签,并且可以使用81个概念进行评估。 在实验中,从21个最频繁的标签中收集了195,834张图像,以形成数据集[17,24]。 其中,我们随机选择2100张图像(每类100张图像)作为测试集。 如果任何两个图像具有至少一个相同的标签,则将它们视为相似的对。
MS-COCO:MS-COCO数据集包含123,287张图像。 它也是一个多标签数据集,共有91个标签。 在实验中,来自原始训练集的82,783张图像形成了数据库,并且从验证集中随机选择了5,000张图像(每个类别250张图像)作为测试数据[17]。 如果MS-COCO中的任何两个图像共享至少一个标签,则它们是相似的。
评估指标:在我们的实验中,我们使用两种评估指标评估检索质量:平均平均精度(mAP)(对于NUS-WIDE和MS-COCO使用mAP @ 5K)和在5,000个最近检索到的邻居中的精度(Top-5K精度) )。
4.2基准和实现
由于我们主要关注深度学习方法,因此我们将我们的方法与7种最新的深度哈希方法进行了比较,包括DHN [53],DPSH [27],DQN [4],HashNet [5]。 ],DCH [3],DTQ [30],ADSH [17]。 我们还将我们的方法与六种最新的非深度哈希方法进行了比较:ITQ [13],Lin [35],LFH [51],FastH [28],SDH [39],COSDISH [19]。
在所有三个数据集上使用[17]进行相同的设置后,我们直接引用了论文的ADSH [17]和六种非深度哈希方法的结果。 对于非深度哈希方法,根据[17]从ImageNet数据集上经过预训练的CNN-F模型中提取4,096个深度特征。 对于其他深度哈希方法,我们使用作者提供的源代码进行了实验。 为了公平地比较,我们采用AlexNet作为骨干。 所有输入图像的大小均调整为224×224,并且在ImageNet数据集上对AlexNet模型进行了预训练。
根据原始论文中的描述,我们使用验证集分别设置批处理大小并调整学习率。 由于这些深层哈希方法都需要固定的训练集,因此按照[17,27]的相同设置,我们从每个数据集中的数据库中划分出一个子集进行训练。 具体来说,对于CIFAR-10数据集,从数据库中随机选择5,000张图像(每类500张图像)。 对于MS-COCO数据集,从数据库中选择10,000个图像(每个类别500个图像),该图像属于20个最类别; 对于NUS-WIDE数据集,从数据库中分离出10,500张图像(每个类别500张图像)进行训练.
对于我们提出的ReHash方法,我们遵循[17]中的非对称哈希学习设置。 特别是在算法1中,我们设置训练迭代参数𝐿𝑜𝑢𝑡= 50,𝐿𝑖𝑛= 3,并且采样的训练子集𝑁Ω= 2000的大小,它等于|Ω|。批大小设置为64,并且使用验证集在[10'6,10'3]之间调整学习率。在目标函数中 (7),我们设置𝛾 = 200,并用权重𝜔以及排名指标Eq中的两个参数𝛼和𝑚评估我们提出的排名嵌入指标的影响。(3)在消融研究中4.4。
4.3结果
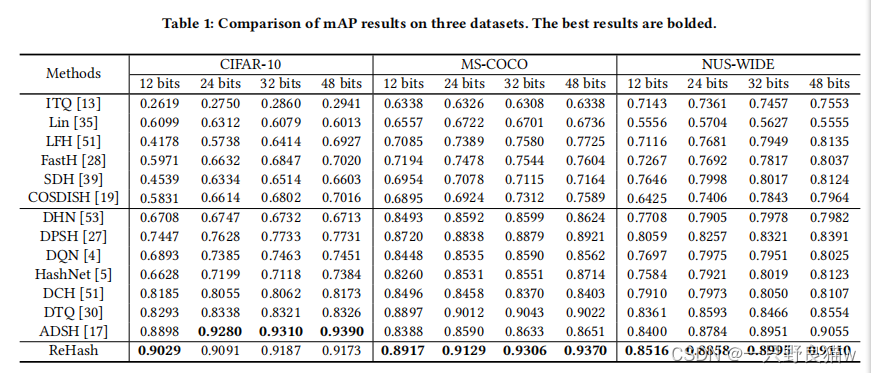
表1显示了当代码长度分别为12、24、32和48位时,在三个数据集上不同方法的mAP结果。 我们可以看到,深度哈希方法优于所有非深度方法,这凸显了通过深度网络进行特征学习的好处,即可以获得更具区分性的表示。
CIFAR-10是单个标签数据集。 ReHash和ADSH优于其他基准。 与最新技术相比,这两种方法在不同的代码长度下实现了mAP的20%以上的增长。 特别是,对于每个代码长度,我们的ReHash方法的mAP都超过90%。 对于较短的代码长度,我们的ReHash优于ADSH。 但是对于较长的代码长度,ReHash略低于ADSH。
MS-COCO和NUS-WIDE是两个多个标签数据集。 我们的ReHash优于所有比较的基线方法。 在MS COCO数据集上,现有方法的mAP结果均在88%以下,而ReHash的mAP结果均超过90%,且二进制代码的长度分别为24、32和48位。 与ADSH相比,ReHash的mAP增加了7%,与DSH,DHN,DPSH和HashNet相比,增加了将近15%。 在NUS-WIDE数据集上,我们的ReHash也达到了最佳性能。 从标签。 如图1所示,我们可以看到ReHash在多标签数据集上表现良好。 实验结果表明,排序列表与监督哈希的反馈一起被自动优化。
我们还评估了包括DHN,DPSH,DQN,HashNet,DCH,DTQ和ReHash在内的不同深度哈希方法的性能。 我们在图2中报告了三个数据集上具有不同代码长度的Top-5K精度结果。可以看出,我们的ReHash优于其他数据。
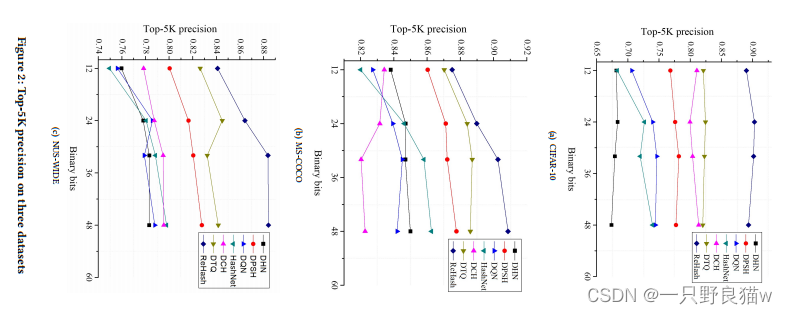
4.4消融研究
损失函数中有许多参数。 在这里,我们分析了ReHash的负边缘𝛼,边距
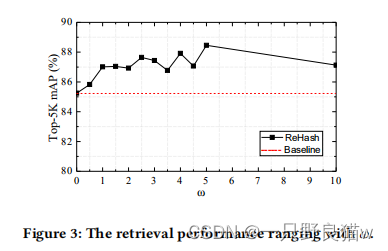
𝑚和权重超参数𝜔对MS-COCO数据集的影响。图3显示了具有不同权重𝜔(基线:𝜔 = 0)的12位哈希码的mAP。
参数𝜔控制秩损失函数影响的程度。我们可以看到,性能随着𝜔
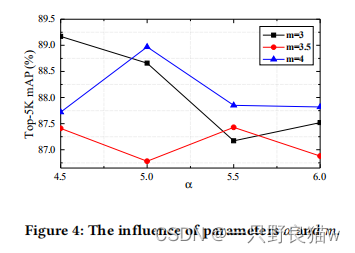
的增加而增加,并且最大结果为𝜔 = 5,之后结果随the的增加而降低。图4显示了具有不同𝛼和bits的12位哈希码的mAP。相对而言,当
𝛼很
小时,性能对
𝑚很
敏感。否则,𝑚对结果影响很小。
总体而言,当𝛼> 5.5时,性能稳定。因此,我们的方法对于不同的参数是鲁棒的。
5结论
本文提出了一种用于图像检索的称为秩嵌入哈希(Re Hash)的方法。 ReHash将排名指标集成到深度监督哈希中,从而可以通过拟议的Rank-embedded Loss端到端地学习深度模型。 通过使用离散哈希作为深度学习的不对称监督,ReHash通过两步方式优化了紧凑代码投影。
我们在三个基准数据集上的实验结果表明,所提出的等级嵌入算法通过学习更多判别性哈希码来提高深度哈希的性能。ReHash优于现有的最新算法,包括无监督和有监督的哈希。值得一提的是,通过升级主干结构和等级损失,可以很容易地扩展所提出的方法,这将在以后考虑。

















 4287
4287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









