




HAN(hierarchical attention network)是2016年提出的用于文档(document)分类的模型,该模型是一个多层注意力网络。由于文档是由句子(sentence)组成,句子是由词(word)组成,HAN先将句子分词后应用一层注意力机制得到句子的向量(sentence vector),然后再应用一层注意力机制得到文档的向量(document vector),最后使用全连接层进行分类。
论文链接:Hierarchical Attention Networks for Document Classification
1 文章的主要贡献
提出了一个用于文档分类的多层注意力网络HAN(hierarchical attention network)。并通过将文档中的句子以及句子中的词的注意力分布进行可视化,证明了HAN可以很好的关注文档中对于分类重要的句子以及句子中重要的词。
2 网络结构
HAN的网络结构为:

可以看到HAN主要包含了三个部分,第一部分为word encoder和word attention,由组成句子的词通过编码以及注意力机制得到句向量;第二部分为sentence encoder和sentence attention,由组成文档的句子的向量通过编码以及注意力机制得到了文档向量;第三部分是一个用来分类的全连接层,全连接层中神经元的个数为分类的类别数。
下面将具体分析每一部分的公式:
论文先对文档进行分句,然后对句子使用Stanford的CoreNLP进行分词。
word encoder和word attention
Embedding层
对于一个分句的词,输入到Embedding层转化为词向量,Embedding层参数使用的是word2vec在训练集和验证集上进行非监督训练后得到的We矩阵进行初始化。Embedding的维度为200。
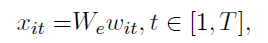
Word Encoder
然后使用双向GRU(bidirectional GRU)来提取输入词的特征,具体公式为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









