







目录
urllib.parse.urlparse urlunparse
urllib.parse.parse_qs urllib.parse.parse_qsl
urllib.parse.urlsplit urllib.parse.urlunsplit
HTTP协议 - 白月黑羽
HTTP协议简介
如果客户端是浏览器,如何在chrome浏览器中查看 请求和响应的HTTP消息?按f12-》network


清除当前信息

响应的消息体在Response里看

点preview,可以看响应的消息体展开的格式

HTTP请求消息
请求头 request headers
提供信息给服务端
User-Agent:
客户端的类型。客户端不一定是浏览器。客户端和服务端(HTTP协议)不仅是浏览器和服务器之间,任何两个软件之间都可以使用HTTP协议。
Accept-Language
客户端希望服务端使用中文
请求体 /消息体

状态行 status line
以前的url 可能是a/b/c,后面可能变成了a/b/d,当再用以前的url访问时,就会返回3XX,代表重定向,相应的响应消息头里会告诉新的url是哪一个
抓包工具 fiddler
只有url中包含customer才显示

requests库 和 session
构建请求消息体
将要发送的网址加到fiddler

如果消息体中放的不是字符串 也不是字节串,那么就知道这个消息体的格式是urlencoded.的格式。
如果data后面直接跟的字典 也知道是urlencoded格式。
json 格式消息体
dumps把python中的对象序列化为json格式的字符串
dumps会把 中文会变成对应的unicode。
data=json.dumps(payload)吧python对象序列化为json格式的字符串,没有对字符串进行编码,那么就会采用缺省的.latin-1 编码.由于已经把中文变成unicode了,所以不会报错
import requests,json
payload = {
"Overall":"良好",
"Progress":"30%",
"Problems":[
{
"No" : 1,
"desc": "问题1...."
},
{
"No" : 2,
"desc": "问题2...."
},
]
}
r = requests.post("http://httpbin.org/post", data=json.dumps(payload))中文会变成对应的unicode

如果不想中文变成unicode编码,可以 写成
data=json.dumps(payload, ensure_ascii=False) 这个就是直接包含中文字符的字符串。
但是这样的话,字符串带有中文,编码方式就得是utff8了,不然ascill码不够用,不能用缺省的latin-1 编码(有中文使用这个会报错)
data=json.dumps(payload, ensure_ascii=False).encode("utf-8")。
dumps把python中的对象序列化为json格式的字符串
loads把json格式的字符串反序列化为python中的对象

这样写有点麻烦
也可以将 数据对象 直接 传递给post方法的 json参数,如下
r = requests.post("http://httpbin.org/post", json=payload)虽然中文对应的也是unicode但是接收端会处理

检查响应消息体
发出去的是字节串,接收的原始消息也是字节串
text获取文本内容,也就是字符串。从字节串到字符串意味着其中有一个解码的过程。
那么,requests是 以什么编码格式 把HTTP响应消息体中的 字节串 解码 为 字符串的呢?
requests 会根据响应消息头(比如 Content-Type)对编码格式做推测。
但是有时候,服务端并不一定会在消息头中指定编码格式,这时, requests的推测可能有误(打印 response.encoding 可以看到推测的解码方式),需要我们指定编码格式。
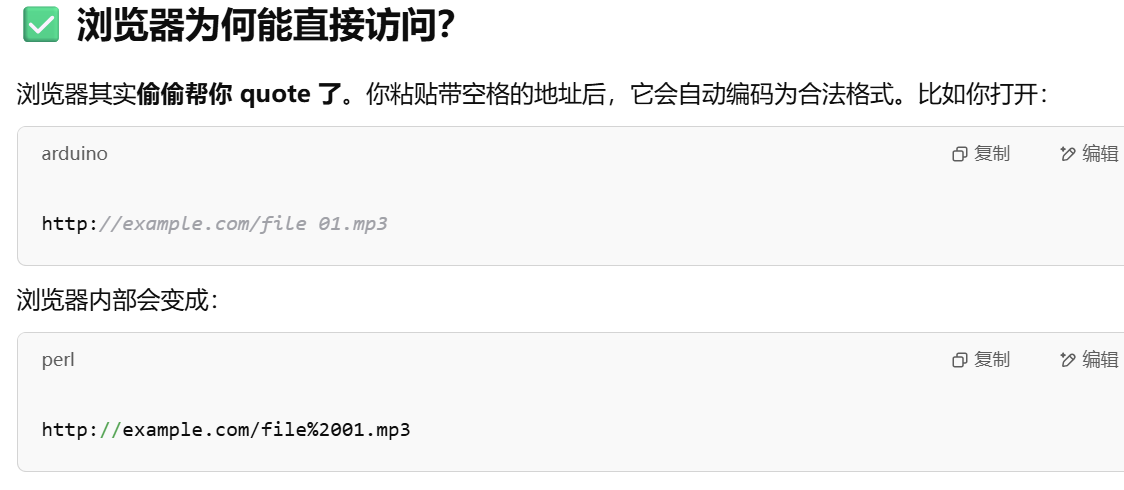
url编码
什么是url?(好文)
url编码:
URL 中不允许直接包含空格、中文和某些特殊符号(比如 #, ?, & 等)——这是 URL 标准规定的。
 常见字符的 URL 编码
常见字符的 URL 编码
| 字符 | 编码 | 说明 |
|---|---|---|
| 空格 | %20 | 或者有时是 + |
" | %22 | 双引号 |
# | %23 | URL 锚点标识 |
% | %25 | 百分号自身 |
& | %26 | 参数分隔符 |
/ | %2F | 路径分隔符(一般不编码) |
中 | %E4%B8%AD | 中文 UTF-8 编码后 |
Web开发须知:URL编码与解码 - 刘哥聊技术 - 博客园
Python 中编码/解码方法
可以使用标准库 urllib.parse中的quote quote_plus urlencode 对url进行编码
urlencode 对字典或由两元素元组组成的列表进行码编码,将其转换为符合url规范的查询字符串。
quote() 只能对字符串编码,而 urlencode() 可以直接对查询字符串字典进行编码。
python中quote函数是什么意思,怎么用 – PingCode
python 中 quote 与 urlencode 的用法与区别_quoteurl-优快云博客
python爬虫学习3:urllib.parse中urlencode(),quote()_urllib.parse.quote-优快云博客
urllib.parse 用于解析 URL — Python 3.11.12 文档
urllib.parse.urlparse urlunparse
import urllib.parse
# 解析url,返回包含url信息的6元元组
url = "https://docs.python.org/3/library/urllib.parse.html#module-urllib.parse"
res = urllib.parse.urlparse(url)
print(res)
print(res.scheme)
print(res.netloc)
print(res.path)
print(res.params)
print(res.query)
print(res.fragment)
"""
ParseResult(scheme='https', netloc='docs.python.org', path='/3/library/urllib.parse.html', params='', query='', fragment='module-urllib.parse')
https
docs.python.org
/3/library/urllib.parse.html
module-urllib.parse
"""
# 从任意包含6元素的可迭代数据结构中构造url字符串并返回
url = urllib.parse.urlunparse(["http", "www.baidu.com", "index", "", "", ""])
print(url) # http://www.baidu.com/index
url = urllib.parse.urlunparse(res)
print(url)
# https://docs.python.org/3/library/urllib.parse.html#module-urllib.parseurllib.parse.parse_qs urllib.parse.parse_qsl
import urllib.parse
# url编码,第一个参数为dict,常用来处理url参数
params = {"key1": "编程", "key2": "写作"}
q = urllib.parse.urlencode(params)
print(q)
# key1=%E7%BC%96%E7%A8%8B&key2=%E5%86%99%E4%BD%9C
# url解码,返回字典,与urlencode()相反
params = urllib.parse.parse_qs(q)
print(params)
# {'key1': ['编程'], 'key2': ['写作']}
# 与parse_qs()唯一的不同是返回列表
params = urllib.parse.parse_qsl(q)
print(params)
# [('key1', '编程'), ('key2', '写作')]urllib.parse.urlsplit urllib.parse.urlunsplit
## urlsplit() 和urlparse()用法一样,只不过返回结果中没有params这个属性.params合并到paths中
使用urllib的parse模块。(4个重要方法)_urllib.parse 用法-优快云博客
import urllib.parse
# 分割url,返回包含url的元组,可用来替代urlparse()
url = "https://docs.python.org/3/library/urllib.parse.html#module-urllib.parse"
res = urllib.parse.urlsplit(url)
print(res)
# SplitResult(scheme='https', netloc='docs.python.org', path='/3/library/urllib.parse.html', query='', fragment='module-urllib.parse')
# 从任意包含5元素的可迭代数据结构中构造url字符串并返回,可用来替代urlunparse()
url = urllib.parse.urlunsplit(["http", "x.org", "index.html", "", ""])
print(url)
# http://x.org/index.htmlurllib.parse.urljoin
Python拼接URL:urllib.parse urljoin使用 - 林风网络
python3 urllib.parse.urljoin()用法_from urlparse import urljoin-优快云博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









