







 文章讨论了如何对一张包含1000w数据的订单表进行分库分表,建议采用先垂直拆分后水平拆分的策略,每个表约存10万数据。分库分表后上线的方案包括停机扩容和双写迁移,各有优缺点。此外,介绍了分库分表的基本概念,包括垂直切分和水平切分。
文章讨论了如何对一张包含1000w数据的订单表进行分库分表,建议采用先垂直拆分后水平拆分的策略,每个表约存10万数据。分库分表后上线的方案包括停机扩容和双写迁移,各有优缺点。此外,介绍了分库分表的基本概念,包括垂直切分和水平切分。
分库分表
1:有⼀张订单表,订单号是雪花id,纯18位的数字。表内有1000w数据,现在要进⾏分库分表,拆分成20个库,100个表,应该如何划分?每个表存放多少数据?
总体思路:先按照区间去分库,然后再按照取模分表:
先垂直拆分:把1000w数据平均分成20个⼤区间的数据,每个区间对应⼀个库,再⽔平拆分:把每个区间的数据再进⾏数据取模(如果⼀个分100个表,那么20个库,每个库就是5张表),那就把区间的数据对5进⾏取模,模后数据分别是0,1,2,3,4,每个数字分别对应这5张表进⾏存储,每个表⼤概10万数据量
分库分表后部署上线有哪⼏种⽅案?
停机扩容
把现有的库中表的数据通过提前写好的程序或者导数据⼯具insert倒⼊到新的分库表和数据库中。
优点:数据迁移⽐较稳定和可靠
缺点:需要的时间过⻓,假如数据有⼏个亿的话,这样去导数据,可能需要很久的时间,线上系统估计要停机很久
双写迁移⽅案
将所有应⽤中对旧库增删改的地⽅,同样对新库增加增删改,这就是所谓的双写⽅案。
当部署起来的时候,需要借助于导数据的⼯具,对数据进⾏检查是否时候最新数据,主要的判定⽅法就是根据字段的modify_time来判断是否是最新的,如果是最近的就进⾏再次的update 这样还可能存在新⽼数据不⼀致的情况,采⽤的⽅法就是程序请求数据的时候进⾏check,默认从新库读,分为以下两种情况
1:如果新库没有则从旧库读,读完之后,将旧库数据写⼊到新库。
2:如果新库有,则⽐较新旧库的数据,如果⼀致直接通过,不⼀致需要从⽼库读,然后update到新库。
优点:动态扩容,线上并不需要停机维护
缺点:增加了开发成本,包括数据⽐较的逻辑,校验的逻辑等
分库分表概念
分库分表有垂直切分和水平切分两种。
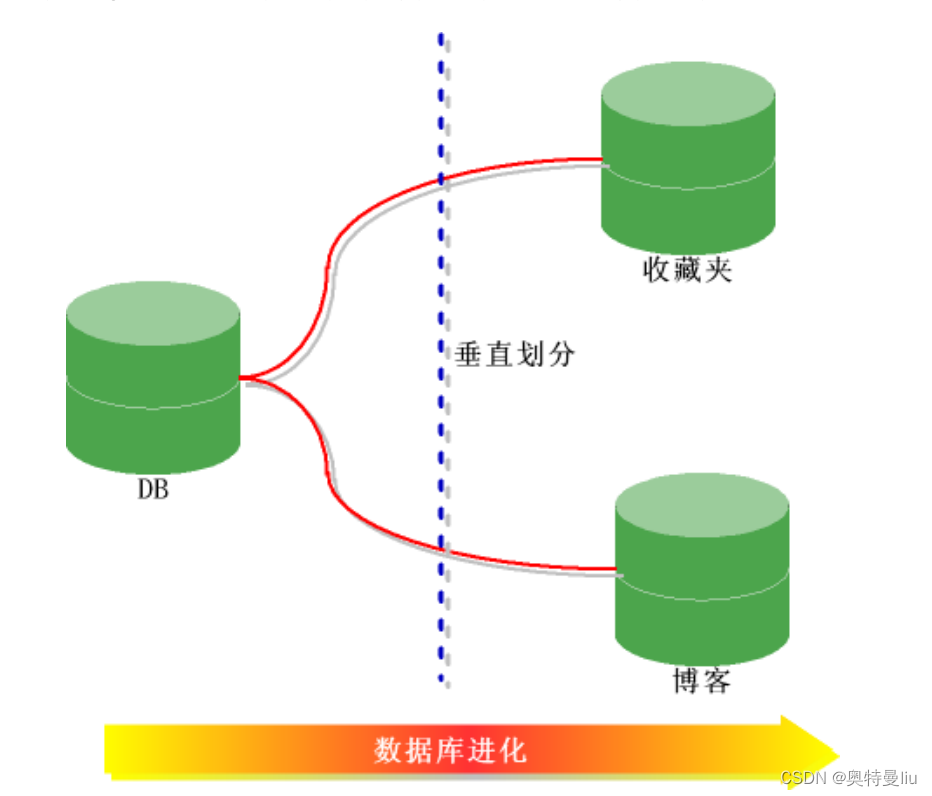
垂直切分(按照功能模块)
将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立定义数据库 workDB、商品数据库 payDB、用户数据库 userDB、日志数据库 logDB 等,分别用于存储项目数据定义表、商品定义表、用户数据表、日志数据表等。
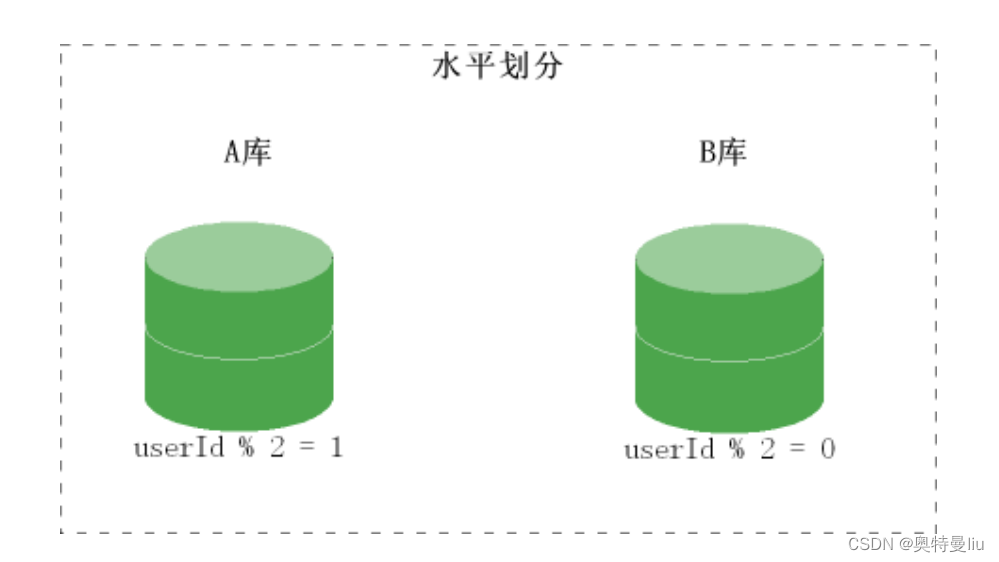
水平切分(按照规则划分存储)
当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,例如 userID 散列,进行划分,然后存储到多个结构相同的表,和不同的库上。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









