




 本文介绍了编码、解码及乱码相关知识。编码是规定字符存储方式,解码是将字节流转换为字符,乱码源于编解码格式不一致。还讲述了编码表发展,如ASCII、ISO8859 - 1、GB系列、Unicode等,比较了几种编码格式。此外,分析了IO操作、URL、HTTP Header等常见的乱码情况及解决办法。
本文介绍了编码、解码及乱码相关知识。编码是规定字符存储方式,解码是将字节流转换为字符,乱码源于编解码格式不一致。还讲述了编码表发展,如ASCII、ISO8859 - 1、GB系列、Unicode等,比较了几种编码格式。此外,分析了IO操作、URL、HTTP Header等常见的乱码情况及解决办法。
一、编码、解码及乱码
字符:人们使用的记号,抽象意义上的一个符号。
字节:计算机中存储数据的单元,一个8位的二进制数,是一个很具体的存储空间。
编码:规定每个“字符”分别用一个字节还是多个字节存储,用哪些字节来存储,这个规定就叫做“编码”。
我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,限定位数的二进制可以有多种不同的状态,每一个状态可以对应特定的信息。例如一个字节有8位,一共可以用来表示2^8(256)种不同的状态,00000000到11111111,每一个状态对应一个符号,就是256个符号。对于1个bit,它只有0和1两种状态,通过制定标准来规定这两种状态对应的含义,看到0和1我们能够很轻松明白它的含义。随着位数的增加,能够表示的信息越来越丰富,但是我们不可能将所有的符号及其对应的二进制都记住,此时就需要一个“字典”来帮忙。这个字典的作用就是记录各个符号和二进制之间的对应关系,当我们遇到一串二进制时就去查字典找出对应的含义,当需要将一个符号转换成二进制时就去查字典将符号翻译成二进制。现实生活中,我们有着对应于不同语言种类的字典,如汉语、英语、日语、德语等等,遇到不同的语言我们需要去查各自对应的字典来翻译它的涵义,如果用错了字典就不会得到正确的信息。
1.编码
编码的过程就是按照规定将字符用字节流存储,如果没有编码就无法传输字符。
2. 解码
解码的过程就是按照特定的编码表将字节流流转换成字符。
3. 乱码
出现乱码的原因就是文本字符编码过程与字节流解码过程使用了不同的编码格式,这个往往归咎于解码格式选择错误,也就是说在解码的过程中出现了问题。如 果我的字符是用utf-8编码,你用GBK解码那肯定出问题。因为文字按照utf-8的编码规则编成的0、1,按照GBK的规则解码回来的文字并不是原来 的文字,这时候就会出现乱码了。这种问题会出现在文件读写、网络编码传输、数据库存取上。只要牵涉到字符都有可能出现乱码,因为只要有字符就会有解码过 程。
4. 编码表的发展历史
- ASCII码
计算机发明后,为了在计算机中表示字符,人们制定了一种编码,叫ASCII码。ASCII码由一个字节中的7位(bit)表示,范围是0x00 - 0x7F 共128个字符。
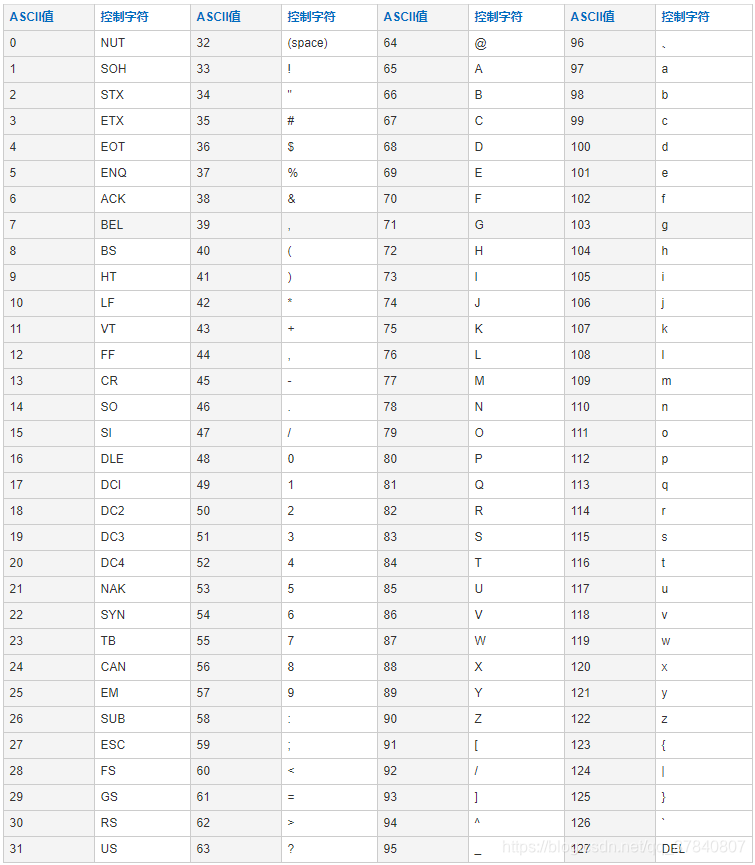
-
ISO8859-1 通常叫做Latin-1
ASCII中的128 个字符显然是不够用的,于是 ISO 组织在 ASCII 码基础上又制定了一些列标准用来扩展 ASCII 编码,它们是 ISO-8859-1~ISO-8859-15,其中 ISO-8859-1 涵盖了大多数西欧语言字符,所有应用的最广泛。ISO-8859-1 仍然是单字节编码,它总共能表示 256 个字符。 -
GB-2312
中国人利用连续2个扩展ASCII码的扩展区域(0xA0以后,)来表示一个汉字,该方法的标准叫GB-2312。后来,日文、韩文、阿拉伯文、台湾繁体(BIG-5)…都使用类似的方法扩展了本地字符集的定义,现在统一称为 MBCS 字符集(多字节字符集)。这个方法是有缺陷的,因为各个国家地区定义的字符集有交集,因此使用GB-2312的软件,就不能在BIG-5的环境下运行(显示乱码),反之亦然。
英文字母和iso8859-1一致(兼容iso8859-1编码) -
GBK,扩展的GB-2312,包含复杂中文和繁体,windows中文操作系统的编码
使用gb-2312一段时间后,我们很快就就发现有许多人的人名没有办法在这里打出来,中国汉字真乃博大精深。于是我们不得不继续把GB2312 没有用到的码位找出来老实不客气地用上。后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。扩展之后的编码方案被称为 GBK 标准,GBK包括了GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
GBK编码,是对GB2312编码的扩展,因此完全兼容GB2312-80标准,也就是说可以用GBK来解码使用GB2312编码的字节流。 -
统一全球,出现unicode标准字符集 统一规定2字节=1字符
全世界各个国家都有自己的编码标准,导致国家与国家之间的编码转换很有问题。为了把全世界人民所有的文字符号都统一进行编码,于是一个叫 ISO (国际标谁化组织)的国际组织制定了”Universal Multiple-ctet Coded Character Set”,简称 UCS, 俗称 “unicode“。这是最统一的编码,可以用来表示所有语言的字符,而且是定长双字节(也有四字节的)编码,包括英文字母在内。所以可以说它是不兼容iso8859-1编码的,也不兼容任何编码。不过,相对于iso8859-1编码来说,uniocode编码只是在前面增加了一个0字节,比如字母a为"00 61"。
需要说明的是,定长编码便于计算机处理(注意GB2312/GBK不是定长编码),而unicode又可以用来表示所有字符,所以在很多软件内部是使用unicode编码来处理的,比如java。 -
UTF-16
UTF-16 具体定义了 Unicode 字符在计算机中存取方法。UTF-16 用两个字节来表示 Unicode 转化格式,这个是定长的表示方法,不论什么字符都可以用两个字节表示,两个字节是 16 个 bit,所以叫 UTF-16。UTF-16 表示字符非常方便,每两个字节表示一个字符,这个在字符串操作时就大大简化了操作,这也是 Java 以 UTF-16 作为内存的字符存储格式的一个很重要的原因。 -
UTF-8
UTF-16 统一采用两个字节表示一个字符,虽然在表示上非常简单方便,但是也有其缺点,有很大一部分字符用一个字节就可以表示的现在要两个字节表示,存储空间放大了一倍,在现在的网络带宽还非常有限的今天,这样会增大网络传输的流量,而且也没必要。而 UTF-8 采用了一种变长技术,每个编码区域有不同的字码长度。不同类型的字符可以是由 1~6 个字节组成。
UTF-8 有以下编码规则:- 如果一个字节,最高位(第 8 位)为 0,表示这是一个 ASCII 字符(00 - 7F)。可见,所有 ASCII 编码已经是 UTF-8 了。
- 如果一个字节,以 11 开头,连续的 1 的个数暗示这个字符的字节数,例如:110xxxxx 代表它是双字节 UTF-8 字符的首字节。
- 如果一个字节,以 10 开始,表示它不是首字节,需要向前查找才能得到当前字符的首字节
几种编码格式的比较
对中文字符后面四种编码格式都能处理,GB2312 与 GBK 编码规则类似,但是 GBK 范围更大,它能处理所有汉字字符,所以 GB2312 与 GBK 比较应该选择 GBK。UTF-16 与 UTF-8 都是处理 Unicode 编码,它们的编码规则不太相同,相对来说 UTF-16 编码效率最高,字符到字节相互转换更简单,进行字符串操作也更好。它适合在本地磁盘和内存之间使用,可以进行字符和字节之间快速切换,如 Java 的内存编码就是采用 UTF-16 编码。但是它不适合在网络之间传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难恢复,想比较而言 UTF-8 更适合网络传输,对 ASCII 字符采用单字节存储,另外单个字符损坏也不会影响后面其它字符,在编码效率上介于 GBK 和 UTF-16 之间,所以 UTF-8 在编码效率上和编码安全性上做了平衡,是理想的中文编码方式。
二、常见的乱码情况
同一个环境下的编、解码是不会出现乱码的,出现乱码的根本原因是不同的环境使用了不同的码表。解决乱码的问题有两种方法,一个是统一码表,比如统一使用UTF-8码表;另一个是在新的环境下将字节流转换为对应环境码表的字节流。
1. IO操作
2.URL 的编解码
用户提交一个 URL,这个 URL 中可能存在中文,因此需要编码。默认编码 ISO-8859-1 解析,所以如果有中文 URL 时最好把 URIEncoding 设置成 UTF-8 编码。
3. HTTP Header 的编解码
当客户端发起一个 HTTP 请求除了上面的 URL 外还可能会在 Header 中传递其它参数如 Cookie、redirectPath 等,这些用户设置的值很可能也会存在编码问题,Tomcat 对它们又是怎么解码的呢?
对 Header 中的项进行解码也是在调用 request.getHeader 是进行的,如果请求的 Header 项没有解码则调用 MessageBytes 的 toString 方法,这个方法将从 byte 到 char 的转化使用的默认编码也是 ISO-8859-1,而我们也不能设置 Header 的其它解码格式,所以如果你设置 Header 中有非 ASCII 字符解码肯定会有乱码。
我们在添加 Header 时也是同样的道理,不要在 Header 中传递非 ASCII 字符,如果一定要传递的话,我们可以先将这些字符用 org.apache.catalina.util.URLEncoder 编码然后再添加到 Header 中,这样在浏览器到服务器的传递过程中就不会丢失信息了,如果我们要访问这些项时再按照相应的字符集解码就好了。
4. POST 表单的编解码
在前面提到了 POST 表单提交的参数的解码是在第一次调用 request.getParameter 发生的,POST 表单参数传递方式与 QueryString 不同,它是通过 HTTP 的 BODY 传递到服务端的。当我们在页面上点击 submit 按钮时浏览器首先将根据 ContentType 的 Charset 编码格式对表单填的参数进行编码然后提交到服务器端,在服务器端同样也是用 ContentType 中字符集进行解码。所以通过 POST 表单提交的参数一般不会出现问题,而且这个字符集编码是我们自己设置的,可以通过 request.setCharacterEncoding(charset) 来设置。
另外针对 multipart/form-data 类型的参数,也就是上传的文件编码同样也是使用 ContentType 定义的字符集编码,值得注意的地方是上传文件是用字节流的方式传输到服务器的本地临时目录,这个过程并没有涉及到字符编码,而真正编码是在将文件内容添加到 parameters 中,如果用这个编码不能编码时将会用默认编码 ISO-8859-1 来编码。
5. HTTP BODY 的编解码
当用户请求的资源已经成功获取后,这些内容将通过 Response 返回给客户端浏览器,这个过程先要经过编码再到浏览器进行解码。这个过程的编解码字符集可以通过 response.setCharacterEncoding 来设置,它将会覆盖 request.getCharacterEncoding 的值,并且通过 Header 的 Content-Type 返回客户端,浏览器接受到返回的 socket 流时将通过 Content-Type 的 charset 来解码,如果返回的 HTTP Header 中 Content-Type 没有设置 charset,那么浏览器将根据 Html 的 中的 charset 来解码。如果也没有定义的话,那么浏览器将使用默认的编码来解码。

















 1481
1481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









