







 本文介绍了堆排序的基本概念,包括大顶堆和小顶堆的定义,以及堆排序的建堆和排序过程。通过代码示例展示了如何使用C#实现堆排序,并详细分析了其时间复杂度(O(nlogn))、空间复杂度(O(1))和稳定性(不稳定)。
本文介绍了堆排序的基本概念,包括大顶堆和小顶堆的定义,以及堆排序的建堆和排序过程。通过代码示例展示了如何使用C#实现堆排序,并详细分析了其时间复杂度(O(nlogn))、空间复杂度(O(1))和稳定性(不稳定)。
目录
基本概念
我们前面讲到简单选择排序,它在待排序的n个记录中选择一个最小的记录需要比较n-1次。本来这也可以理解,查找第一个数据需要比较这么多次是正常的,否则如何知道它是最小的记录。可惜的是,这样的操作并没有把每一趟的比较结果保存下来,在后一趟的比较中,有许多比较在前一趟已经做过了,但由于前一趟排序时未保存这些比较结果,所以后一趟排序时又重复执行了这些比较操作,因而记录的比较次数较多。
如果可以做到每次在选择到最小记录的同时,并根据比较结果对其他记录做出相应的调整,那样排序的总体效率就会非常高了。而堆排序(Heap Sort),就是对简单选择排序进行的一种改进,这种改进的效果是非常明显的。堆排序算法是Floyd和Williams在1964年共同发明的,同时,他们发明了“堆”这样的数据结构。
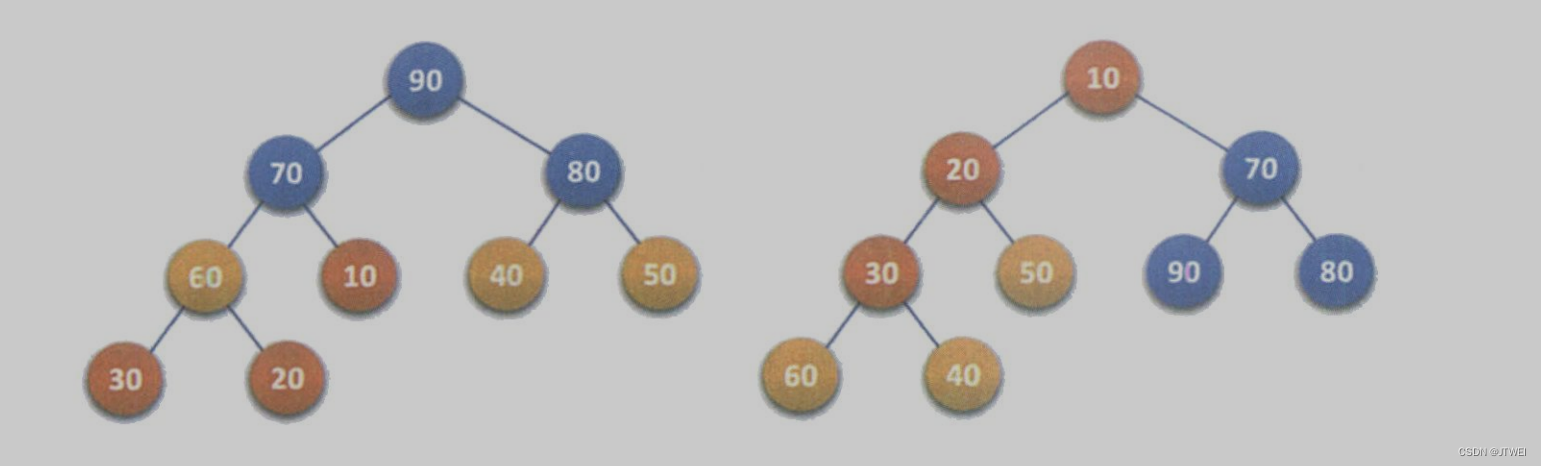
堆排序就是利用堆(假设利用大顶堆)进行排序的方法。它的基本思想是,将待排序的序列构造成一个大顶堆。此时,整个序列的最大值就是堆顶的根结点。将它移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值》,然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元素中的次大值。如此反复执行,便能得到一个有序序列了。
堆是具有下列性质的完全二叉树: 每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆(例如左上图所示);或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆(例如右上图所示)
代码示例
using System;
class HeapSort
{
public static void Sort(int[] arr)
{
int n = arr.Length;
// 构建最大堆
BuildMaxHeap(arr, n);
// 从最后一个节点开始,逐步减少堆的大小,并进行堆化操作
for (int i = n - 1; i > 0; i--)
{
// 将堆顶元素与最后一个元素交换
Swap(arr, 0, i);
// 对减少后的堆进行堆化操作(下沉操作)
Heapify(arr, i, 0);
}
}
// 构建最大堆
private static void BuildMaxHeap(int[] arr, int n)
{
// 从最后一个非叶子节点开始,依次进行堆化操作
for (int i = n / 2 - 1; i >= 0; i--)
Heapify(arr, n, i);
}
// 堆化操作
private static void Heapify(int[] arr, int n, int i)
{
int largest = i; // 当前节点、左子节点和右子节点中值最大的节点
int left = 2 * i + 1; // 左子节点
int right = 2 * i + 2; // 右子节点
// 在左右子节点中找到较大的值
if (left < n && arr[left] > arr[largest])
largest = left;
if (right < n && arr[right] > arr[largest])
largest = right;
// 如果最大值不是当前节点,则交换节点,并继续向下进行堆化操作
if (largest != i)
{
Swap(arr, i, largest);
Heapify(arr, n, largest);
}
}
// 交换数组中的两个元素
private static void Swap(int[] arr, int i, int j)
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
// 测试堆排序
public static void Main(string[] args)
{
int[] arr = { 5, 3, 8, 6, 2, 7, 1, 4 };
Console.WriteLine("Array before sorting:");
PrintArray(arr);
Sort(arr);
Console.WriteLine("Array after sorting:");
PrintArray(arr);
}
// 打印数组
private static void PrintArray(int[] arr)
{
foreach (int num in arr)
{
Console.Write(num + " ");
}
Console.WriteLine();
}
}堆排序分为两个主要步骤:建堆和排序。
-
建堆:
- 首先,将待排序的数组构建成一个最大堆。最大堆是一种完全二叉树,其中每个节点的值都大于或等于其子节点的值。
- 建堆的过程通常从最后一个非叶子节点开始,依次对每个非叶子节点进行堆化操作。堆化操作是通过比较节点与其子节点的值来交换它们的位置,以保证满足最大堆的性质。
- 建堆操作的时间复杂度是O(n),其中n是数组的长度。
-
排序:
- 排序过程总是将最大值(堆顶元素)与堆的最后一个元素交换,并将堆的大小减少1。然后,对新的堆进行堆化操作,使其满足最大堆的特性。
- 重复上述步骤,直到堆的大小为1,即所有元素都已排序完成。
- 排序过程的时间复杂度是O(nlogn)。
堆排序的分析
-
时间复杂度:
- 建堆的时间复杂度是O(n)。
- 排序过程的时间复杂度是O(nlogn)。
- 因此,堆排序的总时间复杂度是O(n + nlogn) = O(nlogn)。
-
空间复杂度:
- 堆排序是原地排序算法,不需要额外的辅助空间。
- 因此,堆排序的空间复杂度是O(1)。
-
稳定性:
- 堆排序是不稳定的排序算法,因为在排序过程中,进行堆化操作会改变相同元素之间的相对顺序。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









