






自用笔记,学习交流;
1、CUDA核函数嵌套核函数的用法多吗?
答:这种用法非常少,主要是因为启动一个kernel本身就有一定延迟,会造成执行的不连续性。
2、代码里的 grid/block 对应硬件上的 SM 的关系是什么
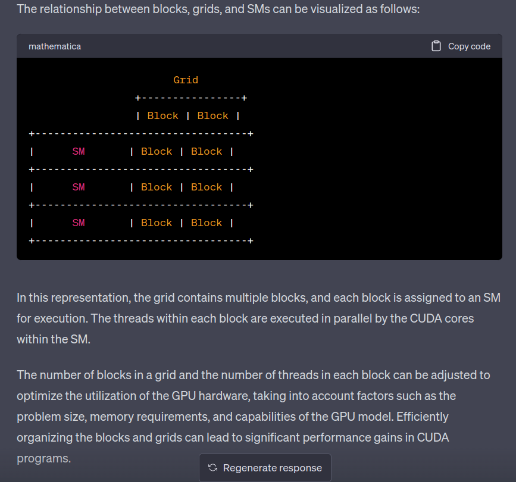
答:首先需要理解grid/block是软件层的概念,而SM是硬件层的概念。所以我们在GPU中是找不到grid/block的,所以只能抽象去理解这个关系。一般来讲一个kernel对应一个grid,分给多个SM去处理。之后每一个SM去处理一个grid中的多个block。这里需要注意的是,block不可以跨越SM去分配,也就是一个block里面的多线程统一由同一个SM中分配资源。因为block中的thread是共享资源的(比如shared memory)。
3、jetson系列,一般都是共享内存,是不是不需要使用cudaMemcpy这个函数了? 要使用其他的memcpy方式吗?
答:关于共享内存在英伟达官方做了一个简短的介绍,链接如下,帮助理解 https://developer.nvidia.com/zh-cn/blog/using-shared-memory-cuda-cc/
对于共享内存的shared-memory-cuda-cc/使用,Jetson系列确实可以直接访问共享内存而无需使用cudaMemcpy函数。首先,理解一下cudaMemcpy函数的功能: (库函数官方介绍)
http://horacio9573.no-ip.org/cuda/group__CUDART__MEMORY_g48efa06b81cc031b2aa6fdc2e9930741.html
从这个函数的介绍,翻译理解一下是将 count 个字节从 src 指向的内存区域复制到 dst 指向的内存区域。是将一个内存空间中的数据复制到另个内存空间中。关于这个函数及相关函数的用法,主要是用于主机内存与GPU内存之间的数据传输,或者是其他内存间的拷贝工作。而共享内存用于 同一个线程块内的线程之间共享数据,所以不涉及到内存数据的转移的话,不用copy函数。故 得出上述结论。。
回答:这里提问者估计混淆了一个概念,你这里想表达的是统一内存(unified memory)而不是共享内存(shared memory)。shared memory无论是不是jetson,只要是GPU一般都会有的概念。而unified memory是Jetson中的概念,表示的是CPU和GPU共享同一片“虚拟”内存(注意这里实际意义上还不是共享同一片物理内存)。所以也就没有了CPU到GPU的数据拷贝过程。使用unified memory的编程方式跟平时有一些差异,你可以看看这篇文章,写的比较详细。以及官方文档 https://developer.ridgerun.com/wiki/index.php?title=NVIDIA_CUDA_Memory_Management#Unified_Memory_Programming_.28UM.29 https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#unified-memory-programming
4、host内存应该不能直接传到share memory吧?肯定要过一次显存,我理解的没问题吧?如果遇到只需要读一次的情况,比如说resize操作,是不是就不需要用到共享内存了呢
答:shared memory中的数据是从显存(global memory)中取出来的,所以需要先过一次显存。默认下kernel中如果没有特殊指定,会跳过shared memory直接从global memory中取数据。所以你说的只读一次的情况是可以不用共享内存的。
5、对这个图有点疑问,按照左边的启动方式,如果d2h1需要等kernel3之后才运行,那为什么kernel1不需要等h2d3之后?
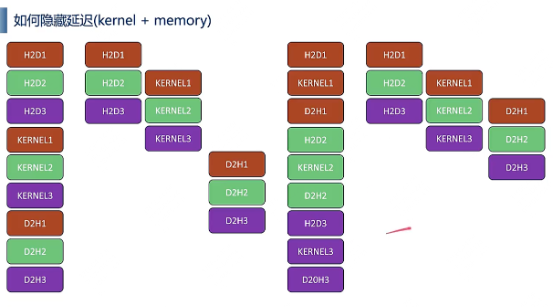
答:这是一个坑也是很让人困惑的地方。之前咨询过NVIDIA那边问为什么会出现这种现象。那边的解释说如果kernel call是连续的,那么即便是多stream,后续的memory copy会等待到最后一个kernel call结束以后再开始调用。估计是资源占用问题导致memory queue队列的signal没有办法issue了。这是一个特殊情况,一般连续kernel call这种方式不被推荐使用。
6、麻烦问一下大家,2.4章节,定义宏的时候,加call与不加call有什么区别呢?
答:第一个用在调用cuda_runtime提供的API函数,所以,都会返回一个cudaError_t类型的变量,需要将变量传入到第一个函数,效验调用API是否正常执行。第二个,使用在自己写的核函数时,自己写的,一般没有返回cudaError_t类型变量,不用传参,如果想知道错误,调用getlastcudaError(),获取系统给你报的错,所以,第二个在函数里面点用了getlastcudaError不用传参。
7、求助一下大家,不知道这块的访存量怎么理解,是不是缺少了cin输入read的feature项呢

答:这个访存量你这么理解,仿存包含read和write的部分。如果说conv的计算主要就是C=A*B的话,A和B的部分是read, C的部分是write。所以说上面的公式分解开的话:
-
的部分是kernel与input的计算部分,属于read
-
的部分是output的部分,属于write
8、这两个函数分别在什么情况下使用,区别是什么

答:区别在于错误时候继续传播下去。你看一下这个英语解释就理解了。cudaGetLastError如果检测到最近的call有错误,那么就会报错,但之后会恢复回cudaSuccess。也就是如果出现了错误,及时找到错误。但是cudaPeekAtLastError的话,并不会回复cudaStatus, 一个call如果出错了,其他后续的call都会一直报错,即便其他的call并没有出错。
9、Texture memory 是off chip 还是 on chip?
答:Texture memory是on-chip的memory,可以快速访问的
10、8704个cuda core是怎么算的?int32 Fp32 fp64加起来每个SM 160个cuda core?


答:Ampere架构下有很多个GPU型号,比如说GA100、GA102、GA103等等。他们都是属于Ampere架构下的GPU,只不过配置会有点不同。主要是因为虽然都是Ampere架构但是会针对不同场景。比如服务器端的高配Ampere架构GPU和desktop端的Ampere架构的GPU的CUDA core、Tensor core、SM数量会不一样。
PPT里这个图是Ampere架构下的GA100型号的GPU,使用这个型号GPU的大家比较熟悉的就是A100了。里面的SM的数量会更多一点(108个),并且有针对FP64的CUDA core。但没有很多跟图像处理相关的东西,比如RT core。很明显这种架构就是用来做大量计算的。这也是为什么A100很适合学习,但不适合跑omniverse这种。
后面这个图是GA102型号的GPU,使用这个型号GPU的大家熟悉的就是3080了,主要是用在desktop端。我们可以看到GA102里缩小了FP64计算的部分,但增大了RT(Ray tracing)的部分。很明显是为了desktop端更多元的使用(游戏、图像处理这些)

11、下面图中的这句话不太理解

答:因为是异步执行的,所以两个cudaEventRecord之间的时间间隔间可能会发生其他stream的时间,导致会有一些误差。
12、它去计算8或16位,是硬件电路简单或复杂的方式来实现的,无论乘法器如何设计,结果以一个时钟周期为准,如果cuda core时钟周期内能做一次FMA,就等于2次 FLOPS。老师是这么讲的,这些信息里有啥修正的吗?

答:我重新看了一下这里的PPT。这个地方写的是没有错误的。这里说的1024个FP16计算就是FMA计算,在计算Throughput的时候有一个*2项表示了一个FMA等于两次计算。至于上面画的(256 * 4)指的是一个tensor core在1ck可以做256个FMA,但一个SM中有4个tensor core,所以是4乘以256,这个在下面的公式体现出来了。相反,我发现前面有一个地方打错字了,我修改了一下之后重新上传了。
13、图像数据在GPU显存中的排列顺序是chw还是hwc?
答:你可以选择chw,也可以选择hwc。看你怎么排序都可以。
TensorRT模型部署优化
1、模型部署后,用什么手段分析推理性能?
答:可以利用Nsight工具分析模型推理性能。通过该工具可以捕获模型各个kernel运行的时间。针对运行情况,我们再做优化。
2、神经网络中吞吐和延迟的关系?
答:吞吐是用来描述一个硬件设备单位时间内可以完成的计算量;延迟是用来描述一个模型推理所需的时间。延迟又分为计算产生的延迟和数据传输(包括数据同步)造成的延迟。我们可以用nsys和Nsight Compute工具定量分析不同阶段的延时情况。
3、tensorrt量化方法?
答:trt默认和推荐的量化算法是entropy,但具体需要看情况,有时候选择minmax或者percentile会达到更好的效果。这个需要结合op的特点一起考虑。
4、模型导出fp32的trt engine没有明显精度损失,导出fp16损失很明显,可能的原因有哪些?
比较突出的几个可能性就是:对一些敏感层进行了量化导致掉精度比较严重,或者权重的分布没有集中导致量化的dynamic range的选择让很多有数值的权重都归0了。另外,minmax, entropy, percentile这些计算scale的选择没有根据op进行针对性的选择也会出现掉点。
5、onnx模型推理结果正确,但tensorRT量化后的推理结果不正确,大概原因有哪些?
出现这种问题的时候,需要先确认两种模型推理的前处理(例如,对输入的各种预处理需要和pytoch模型的训练预处理完全一致)和后处理是否一致。确认是量化引起的问题时,可能原因有:
-
a. calibrator的算法选择不对;
-
b. calibration过程使用的数据不够;
-
c. 对网络敏感层进行了量化;
-
d. 对某些算子选择了不适合OP特性的scale计算。
6、采用tensorRT PTQ量化时,若用不同batchsize校正出来模型精度不一致,这个现象是否正常?
答:这个现象是正常的,因为calibration(校正)是以tensor为单位计算的。对于每次计算,如果histogram的最大值需要更新,那么PTQ会把histogram的range进行翻倍。参考链接:https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#enable_int8_c

不考虑内存不足的问题,推荐使用更大的batch_size,这样每个batch中包含样本更加丰富,校准后的精度会更好。但具体设置多大,需要通过实验确定(从大的batch size开始测试。一点一点往下减)。需要注意的是batch_size越大,校准时间越长。
7、关于对齐内存访问的疑问:如果使用L1cache,访问的颗粒度为128B,对齐的首地址应该为128B偶数倍,不应该是0B,256B,512B.......吗?
答:实际上这里的偶数倍(even multiple)指的是地址是偶数倍的,并非128B的偶数倍。比较官方的解释可以参考如下链接:https://www.nvidia.com/content/PDF/sc_2010/CUDA_Tutorial/SC10_Fundamental_Optimizations.pdf
8、同一个模型,3090 GPU转换成功,但RTX4000转换失败,该如何解决?(具体错误信息见下图)
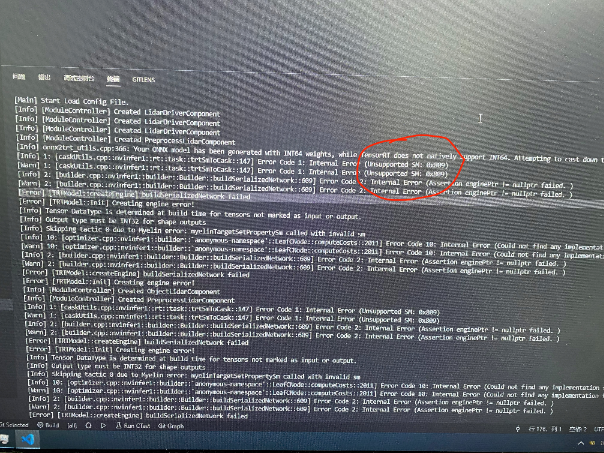
答:此处提示SM相关错误,所以可以检查makefile或CMakeLists.txt中对nvcc编译器option的设定是否存在问题。
9、如何使用nsight或CUDA runtime api分析模型推理性能?
答:通过nsight可以看到核函数的名字(可通过名字推测它是用cuda core或tensor core, fp16还是int8)还有可以查看memory的流动。
10、如何尽量减少GPU和CPU之间的数据交互或内存分配与回收?
答:由于在推理过程中,CPU与GPU之间的数据拷贝耗时较长或出现频繁分配和回收内存的现象,这大大降低了模型推理性能。我们可以采用在推理模型前分配好所需要的最大内存(做到内存复用)以降低内存分配或回收的次数。针对CPU与GPU之间数据相互拷贝问题,我们需要优化代码流程,尽量减少拷贝的次数或寻找更好的方法去掩盖这个动作需要的时间。
11、如果QAT可以使模型尽可能减少量化带来的误差,那么可以不做敏感层分析,直接将整个网络量化为INT8吗?
答:不建议这么做,从经验来看,敏感层量化到INT8精度会下降很多,所以还是有必要进行敏感层分析。
12、模型量化到INT8后,推理时间反而比FP16慢,这正常吗?
答:正常的,这可能是tensorrt中内核auto tuning机制作怪(会把所有的优化策略都运行一遍,结果发现量化后涉及一堆其他的操作,反而效率不高,索性使用cuda core,而非tensorrt core)。当网络参数和模型架构设计不合理时,trt会添加额外的处理,导致INT8推理时间比FP16长。我们可以通过trt-engine explorer工具可视化engine模型看到。
13、请教一下,engine推理的时候,batchsize=1和batchsize=4,推理时间相差也接近4倍合理吗?有什么办法让多batch的推理时间接近单batch吗?比如加大显存?
答:这个可能出现的原因有很多,有可能单个batchsize的推理就已经把GPU资源全部吃满了,所以batchsize=4的时候看似加大了并行度,实际上也可能是在串行。建议把模型推理放在nsight system上分析一下,看看硬件资源占用率。
14、在device固定的情况下呢?有什么参数设置或者增加streams的方式吗?试过把workspace设到最大,只有轻微的提升
答:workspace的大小跟性能提升关联不大,workspace是使用在创建推理引擎时TensorRT选择tactics来进行优化的,workspace越大可以选择的tactics越丰富。但除非特别的小,一般关联不是那么大。试试fp16, int8这种量化参数来试试量化,cuda-graph来试试kernel launch的隐藏,builderOptimizationLevel的等级设置高一点等等。光靠参数优化还是有点局限。可以看看模型架构是否有冗长。
15、问题描述如下:在取出A矩阵的i,k的值的时候为什么是(float)_A[i*_wa+k],而不是(float)_A[i+k]
//C = A*B
void MatrixMulCPU(float* _C,const float *_A,const float *_B,int _wa,int _ha,int _wb)
{
float sum = 0;
for (int i = 0; i < _ha; ++i)
{
for (int j = 0; j < _wb; ++j)
{
sum = 0;
for (int k = 0; k < _wa; ++k)
{
//i*_wa得到当前对应的是A矩阵中的哪一行,+k对应当前行的哪一列.矩阵A的stride是wa
//j对应当前矩阵B的哪一列,+k*wb依次表示第0行的j列,第1行的j列...第wa-1行的j列.矩阵B的stride是wb
sum += (float)_A[i*_wa+k]*(float)_B[k*_wb+ j];
}
_C[i*_wb+j] = (float)sum;
}
}
答:循环 for (int i = 0; i < _ha; ++i) 遍历矩阵A和矩阵C的行
循环 for (int j = 0; j < _wb; ++j) 遍历矩阵B和矩阵C的列
最内层循环 for (int k = 0; k < _wa; ++k) 遍历矩阵A的列和矩阵B的行。它计算矩阵A中对应的行和矩阵B中对应的列的点积,并将结果累加到 sum 中。计算得到的 sum 值被存储在矩阵C的相应位置
使用(float)_A[i * _wa + k]来访问矩阵A的元素,而不是(float)_A[i + k]。这是因为矩阵A是一个二维矩阵,其元素存储在一维数组中。如果我们使用_A[i + k]来访问矩阵A的元素,则假设矩阵A的每行有_wa个元素。这将导致错误的结果,因为这样的索引方式不会正确地访问矩阵的每个元素。回答:(韩君)小徐回答的很正确。二维的矩阵在memory中存储方式是一维的,所以遍历的时候需要添加stride(这个例子中的wa)来进行跳着寻址
16、问题描述如下:
想请问Conv2D MAC(memory access cost)的计算是不是如下(不考虑bias):
对于读取input_tensor=(Kernel_H*Kernel_W*Cin*Hout*WoutCout)
对于图取Filter:Kernel_h*Kernel_w*Cin*Hout*Wout*Cout
对于写output:
CoutHout*Wout
总共的MAC就是上面加起来
我在网上看到有人把MAC直接等于计算memory storage来 我感觉好像怪怪的 特次还请教 谢谢老师
答:MAC这个缩写其实可以有很多,一般不同background的人用MAC会表示不同的意思。这里的Conv2D MAC应该是指Multiply-Accumulate Operation。跟FLOPs比较相近的概念。不是指memory相关,而是指做了多少次混合乘加法。
17、cuCtxCreate(&cu_context, flags, cu_device); // 这个函数耗时长,单次大约3s,大家有没有遇到过?
答:这里有个细节纠正一下,cuCtxCreate函数是CUDA driver api,而不是(运行时)CUDA runtime api。有一个技巧时cu开头的一般是CUDA driver api,比如cuCtxCreate。cuda开头的一般是CUDA runtime api,比如cudaMemcpy
cuda第一次使用有关CUDA的API时,会做很多一些额外的处理有些我们看不见。一开始使用一些kernel的时候也会相对有些慢,这也是为什么benchmark的时候需要做一些warmup。
18、老师,想请问一下,在进行多流处理的时候,为什么分流后他们不重叠呀

答:这个视频里面有讲,如果某一个流里面已经把硬件资源给全部使用满了,那么即便是使用多流的话,各个流也需要等待其中一个流计算结束把硬件资源释放了以后才可以使用。你这个例子中你把matmul的计算量调小一点试试,这些就stream就重叠了。
19、我们在双线性插值计算图中B的坐标的时候,采用的是src_y1, src_x1为目标点x,y还原到原图后对应的点的最近的左上整数坐标点
-
int src_y1 = floor((y + 0.5) * scaled_h - 0.5);
-
int src_x1 = floor((x + 0.5) * scaled_w - 0.5);
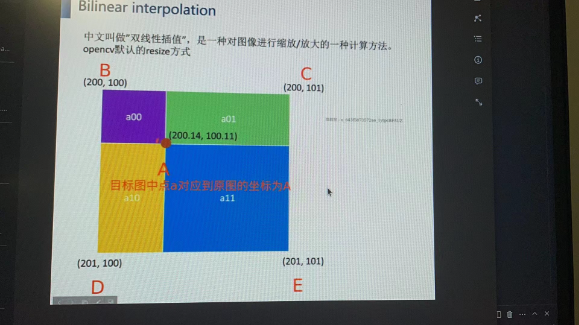
这里有两个问题:
1)为什么不是 int src_y1 = floor((y) * scaled_h - 0.5);
2)如果y+0.5是为了转换为浮点数,那么所加的0.5是不是太多了,如果A的坐标是200.6,100.8,那么加上0.5会不会就超出(200,100)与(201,101)对角所构成的正方形了么?
答:这里有一个误区。要理解这个问题需要先理解0.5的作用是什么。加减0.5并不是为了转换为浮点数,而是为了找到resize前后的坐标的中心点。假设如果上面的公式中把所有的0.5给去掉,那么公式就会变成
-
int src_y1 = floor(y * scaled_h );
-
int src_x1 = floor(x * scaled_w );
这么做看似很正确但是如果你细心观察一下的话,其实这个会不准确。举一个简单的例子:把一个9x9大小的图片(src)缩小到3x3的图片(tar),那么tar中的(1, 1)这个坐标的取值应该参考src中的哪一个位置? 抛开公式去考虑,(1, 1)是3x3的中心坐标,所以理应应该去找src中的(4, 4)对吧。但是,如果我们不用0.5去对齐中心点的话,我们得到的值会是:
-
int src_y1 = floor(y * scaled_h ) = 3;
-
int src_x1 = floor(x * scaled_w ) = 3;
很显然我们计算得到的src的坐标(3, 3)在(4, 4)左上方,这个会造成resize的结果有误差。如果按照你的方案只减0.5的话,得到的src的坐标会是(2, 2),误差更大。造成这个误差的原因就是因为我们没有考虑中心点。如果说坐标是以1为刻度增加的话,那么+0.5就正好是这个当前坐标与有下方坐标的中心点。我们在做resize的时候,是需要对齐这个中心点。x + 0.5表示tar的中心点,乘以scale得到src中的中心点,之后再-0.5找到src中对应的坐标,这样结果就是正确的了,刚才的例子:
-
int src_y1 = floor((y + 0.5) * scaled_h - 0.5) = 4;
-
int src_x1 = floor((x + 0.5) * scaled_w - 0.5) = 4;
20、老师讲stream那节课说一般是overlap核函数和内存之间的拷贝,但是两张图展示的效果肯定是上面这个好,但是和老师说的就有点违背了上面那个全部是核函数之间的重叠,下面那个虽然核函数执行把memcpy给overlap了但效果并不好(老师可不可以讲解一下这两个图的区别)
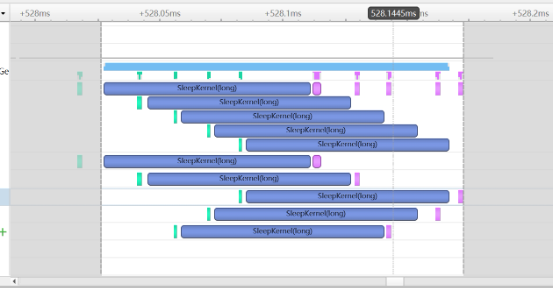
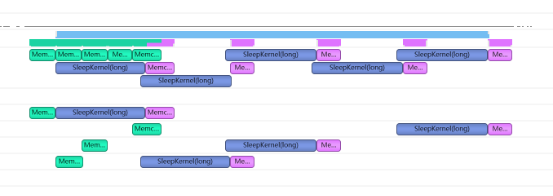
答:如果一个kernel的执行没有能够把所有硬件资源全部占满的话,那么可以考虑将多余的资源分配给其他kernel用,这样的话可以用多stream来分别处理不同的不用的kernel实现kernel执行的overlap,也就是上面的第一张图。但是如果一个kernel的计算已经把所有资源占满了,那么即便另外一个kernel是在其他stream上跑,那也需要等待资源腾出来才可以执行,也就是第二张图。但是你想,如果一个kernel没有能够把硬件资源占满,那是不是可以说明这个kernel需要提高一下计算密度呢?所以不是说kernel能重叠就是效果好的。这两个图的kernel的参数是不一样的,所以导致overlap的方式也不一样。
21、下面这两个图的资料,这个地方ppt是不是不太准确


答:PPT中说是没有错的。下面的文章中也说了PCIe总线是共享所以同一时间内对memory只能做一个read,或者一个write。是串行的。但双工PCIe是对传统PCIe的扩展,可以实现同一时刻同时进行发送和接受数据。你要如果仔细看的话,ppt中的下面的右边的两个图就是H2D和D2H重叠了。但是需要注意的是,需要是“不同方向”,也就是说某一个stream的H2D不能够和另外一个stream的H2D重叠。
22、下面这个循环应该只执行一次,老师做测试用么,这2个变量这个核函数也没有用到吧。

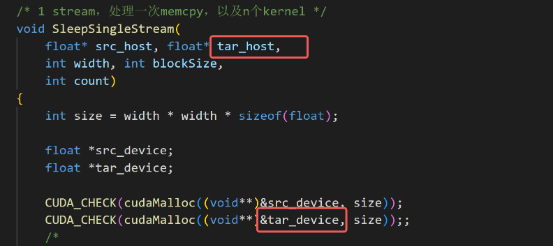
答:对,这个提供给大家做测试用的。想让大家看看多次cudaMemcpy在nsight上是呈现什么样子的。具体传输的东西,以及计算的内容没有必要考虑。这里你把tar_device相关的删了也无所谓。
21、问题描述如下:
问题1、三个红箭头调用都是异步的:
-
异步调用后cpu不会阻塞而是立刻返回往下执行? 因此cpu调用函数 不等于 函数在gpu上真正launch?
-
什么是k函数启动(launch)?是指代码中kernel函数被cpu调用时刻 ,还是 k函数在gpu上真正开始运行时?
-
老师能描述下代码中异步调用kernel函数后发生的过程吗?比如资源沾满要排队时,这算是被cpu调用了吗,cpu会继续往下执行代码还是阻塞在那一句代码处?又或者算是被启动了吗? 我想知道cpu执行到异步调用kernel函数,和这个kernel函数启动,以及这函数真正在运行,三者是什么关系?
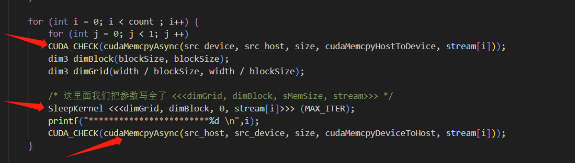
答:
-
异步执行是指cpu和gpu间异步,所以也就是说CPU在执行完一个异步操作以后,就会不阻塞的开始执行下一条语句。gpu上是否启动这个kernel(也就是所谓的launch kernel),按照什么顺序launch kernel,是在每一个Stream里面定的
-
是后者。kernel launch是CUDA中的概念。cpu只负责调用这个函数与否。具体什么时候launch这个kernel要看GPU
-
先从结论说起,这块代码cpu会一直不阻塞的执行下去,一直执行到后面的(这个截图没有)cudaDeviceSynchronize()位置cpu端都不会停止等待gpu。这段期间cpu不断的给每一个stream里issue要执行的指令,issue完就执行下一步,不管gpu执行完还是没有。那么阻塞在哪里呢?是在gpu端。gpu端里的每一个stream里的要执行的东西是有顺序的,比如说这个里面就和H2D->kernel launch->D2H这三个部分。一个stream还好说。但多个stream的话,如果某一个stream的kernel计算把所有资源都占满了,那么其他stream即便到了它执行kernel的时候也需要等待资源腾出来了才能launch它的kernel。也就是说gpu中stream间内的 kernel和memory操作的执行顺序需要看资源的占用情况。但需要注意的是,gpu上是如何执行的cpu是看不见的。
22、TensorRT如何设置混合精度推理 在int8模式下如何单独设置某一层的精度。
答:TensorRT C++ API的ILayer里面有相关的设定,你可以在官方文档查看一下。另外trtexec也有option可以逐层指定精度
部署分类器
1、请问一下,如果有多个input host ,多个output host,在infer这里,那bindings那那些该怎么写呢?可以提供个模板吗

答:模版自己改就好了。多个input,多个ouput的话,给弄成指针数组就好了,你可以参考一下我在第七章的yolov8-seg部署里准备的代码。
2、deformconv在opeset19支持了,所以我不用custom 符号,而是用这个opset19支持的算子。结果export onnx失败,是为什么呢?
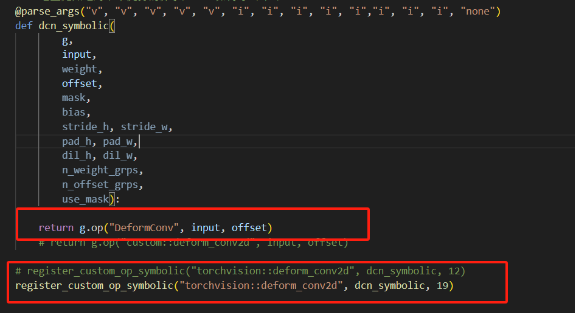
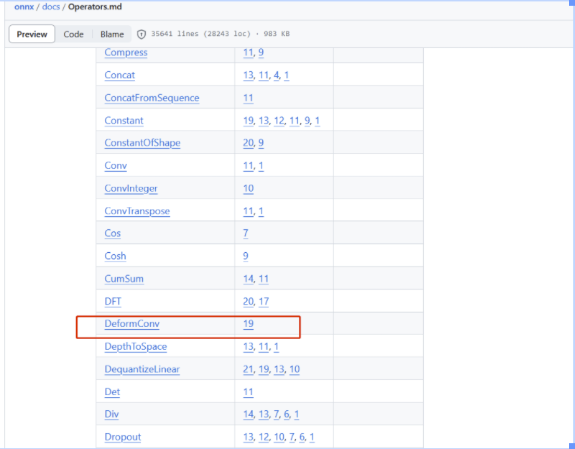
答:你把你显示的错误贴在这里,之后你看看你torch.onnx.export里的opset是不是19。之后你再看看你安装的环境里torch中的onnx是否支持opset19。
3、layernorm在opset17才开始支持,那为什么将opset12的onnx加载后,可以替换为LayerNorm onnx算子,opset12是没有这个算子的吧?我猜opset版本只在export那一步时使用?会到12.py去搜对应算子。而通过surgeon.register的会全局搜算子?
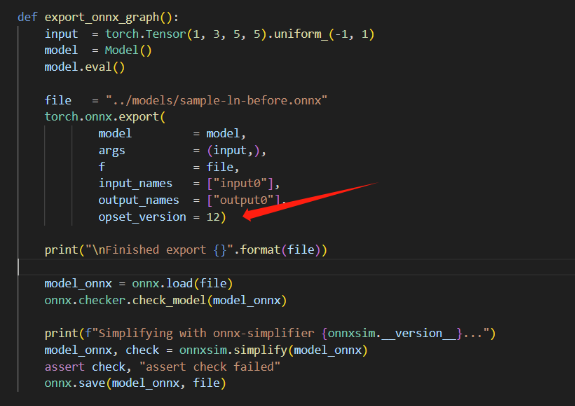

答:你试试你把这里导出的op的名字改成任意一个名字都是可以导出成功的。(e.g. op="LayerNormalization11")。这里的注册算子就是如同字面意思,给onnx中注册它本来没有的算子。torch.onnx.export中的是走的onnx中已经注册的算子。上面的layerNorm的注册算子的函数没有走这个export路线。

















 2468
2468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









