







XML
extensible markup language 可扩展的标记语言
XML有什么用?
- 可以用来保存数据
- 可以用来做配置文件
- 数据传输载体
XML是树状结构
XML 仅仅是纯文本
XML 没什么特别的。它仅仅是纯文本而已。有能力处理纯文本的软件都可以处理 XML。
不过,能够读懂 XML 的应用程序可以有针对性地处理 XML 的标签。标签的功能性意义依赖于应用程序的特性。
定义XML
-
文档声明
<?xml version="1.0" ?>简单声明,version:解析这个xml的时候,使用什么版本的解析器
<?xml version="1.0" encoding="gbk" ?>encoding:解析xml中的文字的时候,使用什么编码来编译
<?xml version="1.0" encoding="gbk" standalone="no"?>standalone:no 该文档会关联其他文档
默认文件保存的时候,使用的是GBK的编码保存。
所以要想让我们的xml能够正常的显示中文,有两种解决办法
- 让encoding也是GBK 或者 gb2312 .
- 如果encoding是 utf-8 , 那么保存文件的时候也必须使用utf-8
- 保存的时候见到的ANSI 对应的其实是我们的本地编码 GBK。
为了通用,建议使用UTF-8编码保存,以及encoding 都是 utf-8
元素定义(标签)
-
其实就是里面的标签, <> 括起来的都叫元素 。 成对出现。 如下:
<stu> </stu> -
文档声明下来的第一个元素叫做根元素 (根标签)
-
标签里面可以嵌套标签
-
空标签
既是开始也是结束。 一般配合属性来用。
<age/>
<stu>
<name>张三</name>
<age/>
</stu>
-
标签可以自定义。
XML 命名规则
XML 元素必须遵循以下命名规则:名称可以含字母、数字以及其他的字符 名称不能以数字或者标点符号开始 名称不能以字符 “xml”(或者 XML、Xml)开始 名称不能包含空格
命名尽量简单,做到见名知义
XML 标签对大小写敏感
XML 元素使用 XML 标签进行定义。
XML 标签对大小写敏感。在 XML 中,标签 与标签 是不同的。
必须使用相同的大小写来编写打开标签和关闭标签:
简单元素 & 复杂元素
- 简单元素
元素里面包含了普通的文字
- 复杂元素
元素里面还可以嵌套其他的元素
属性的定义
定义在元素里面, <元素名称 属性名称=“属性的值”></元素名称>
<stus>
<stu id="10086">
<name>张三</name>
<age>18</age>
</stu>
<stu id="10087">
<name>李四</name>
<age>28</age>
</stu>
</stus>
xml注释:
与html的注释一样。
<!-- -->
如:
<?xml version="1.0" encoding="UTF-8"?>
<!--
//这里有两个学生
//一个学生,名字叫张三, 年龄18岁, 学号:10086
//另外一个学生叫李四 。。。
-->
xml的注释,不允许放置在文档的第一行。 必须在文档声明的下面。
CDATA区
服务器给客户端传数据时会出现
实体引用
在 XML 中,一些字符拥有特殊的意义。
如果你把字符 “<” 放在 XML 元素中,会发生错误,这是因为解析器会把它当作新元素的开始。
这样会产生 XML 错误:
<message>if salary < 1000 then</message>
为了避免这个错误,请用实体引用来代替 “<” 字符:
<message>if salary < 1000 then</message>
在 XML 中,有 5 个预定义的实体引用:
| < | < | 小于 |
|---|---|---|
| > | > | 大于 |
| & | & | 和号 |
| ' | ’ | 单引号 |
| " | " | 引号 |
注释在 XML 中,只有字符 “<” 和 “&” 确实是非法的。大于号是合法的,但是用实体引用来代替它是一个好习惯。
所有 XML 文档中的文本均会被解析器解析。
只有 CDATA 区段(CDATA section)中的文本会被解析器忽略。
某些文本,比如 JavaScript 代码,包含大量 “<” 或 “&” 字符。为了避免错误,可以将脚本代码定义为 CDATA。
CDATA 部分中的所有内容都会被解析器忽略。
CDATA 部分由 “<![CDATA[*" 开始,由 "*]]>” 结束:
<script>
<![CDATA[
function matchwo(a,b)
{
if (a < b && a < 0) then
{
return 1;
}
else
{
return 0;
}
}
]]>
</script>
在上面的例子中,解析器会忽略 CDATA 部分中的所有内容。
关于 CDATA 部分的注释:
CDATA 部分不能包含字符串 “]]>”。也不允许嵌套的 CDATA 部分。
标记 CDATA 部分结尾的 “]]>” 不能包含空格或折行。
XML解析
获取XML里面的字符或属性
XML的解析方式
有很多种,常用的有两种.
- DOM
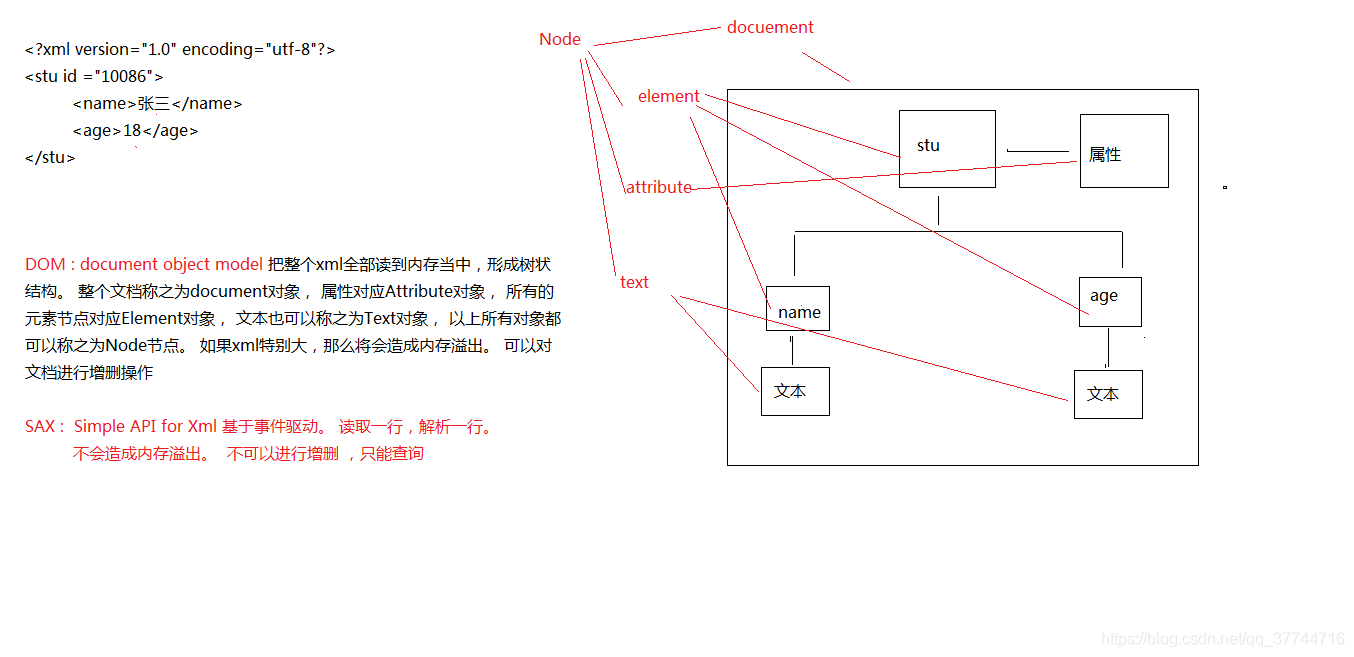
-
SAX(Simple API for Xml)
基于事件驱动,读取一行,解析一行,不会造成内存溢出,不可以进行增删,只能查询.
针对这两种解析方式的API
一些组织或者公司, 针对以上两种解析方式, 给出的解决方案有哪些?
jaxp sun公司,比较繁琐
jdom
dom4j 使用比较广泛
Dom4j 基本用法
- 创建SaxReader对象
- 指定解析的xml
- 获取根元素。
- 根据根元素获取子元素或者下面的子孙元素
XPath的使用
dom4j里面支持Xpath的写法。 xpath其实是xml的路径语言,支持我们在解析xml的时候,能够快速的定位到具体的某一个元素。
-
添加jar包依赖
jaxen-1.1-beta-6.jar
-
在查找指定节点的时候,根据XPath语法规则来查找
-
后续的代码与以前的解析代码一样。
XML 约束
DTD
语法自成一派, 早期就出现的。 可读性比较差。
Schema
其实就是一个xml , 使用xml的语法规则, xml解析器解析起来比较方便 , 是为了替代DTD 。
但是Schema 约束文本内容比DTD的内容还要多。 所以目前也没有真正意义上的替代DTD
名称空间的作用
一个xml如果想指定它的约束规则, 假设使用的是DTD ,那么这个xml只能指定一个DTD , 不能指定多个DTD 。 但是如果一个xml的约束是定义在schema里面,并且是多个schema,那么是可以的。简单的说: 一个xml 可以引用多个schema约束。 但是只能引用一个DTD约束。
名称空间的作用就是在 写元素的时候,可以指定该元素使用的是哪一套约束规则。 默认情况下 ,如果只有一套规则,那么都可以这么写.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









