









 本文介绍了一种名为CiiV的框架,旨在提升深度学习模型对对抗样本的鲁棒性。不同于对抗训练,CiiV采用主动防御策略,仅使用正常样本进行训练,通过RetinotopicSampling操作引入工具变量,减少混杂因子的影响。实验表明,这种方法能有效防御不同攻击方法产生的对抗样本,且在保持模型预测准确性的同时增强其稳定性。
本文介绍了一种名为CiiV的框架,旨在提升深度学习模型对对抗样本的鲁棒性。不同于对抗训练,CiiV采用主动防御策略,仅使用正常样本进行训练,通过RetinotopicSampling操作引入工具变量,减少混杂因子的影响。实验表明,这种方法能有效防御不同攻击方法产生的对抗样本,且在保持模型预测准确性的同时增强其稳定性。
简介
文章解决的问题: 提升模型对于对抗样本的鲁棒性
对抗训练劣势: 大部分有效的防御方法仍然是对抗训练。而对抗训练是否有效,又取决于是否有尽可能多的,来自不同攻击方法产生的对抗样本。由于是被动防御,因此无法免疫未知攻击
该方案优势: 是主动防御的训练方案,不需要模型进行无休止的对抗训练,而且训练时只使用了正常样本,没有使用对抗样本
文章的贡献: 分析了现有对抗性攻击和防御方法起作用的原因,并首次从因果推理的角度提出了一种提升视觉模型鲁棒性的训练方法,可有效地防御来自不同攻击方法产生的对抗样本
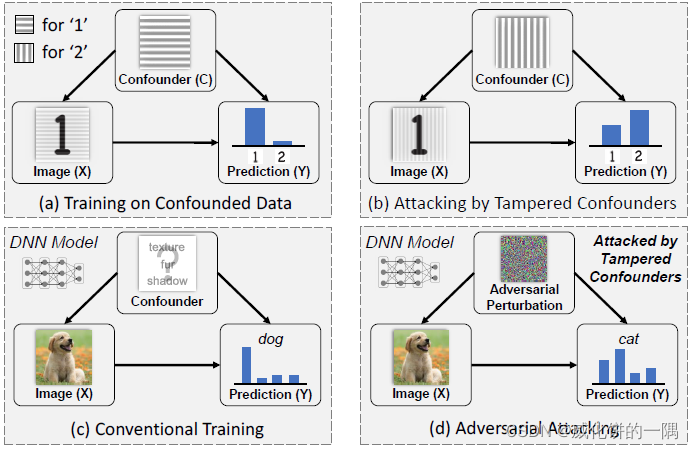
motivation
AI会利用人看不见的模式进行分类,这些模式组成混杂因子(confounder),例如上图中作为背景的条纹,数字1的背景大部分是横的条纹,数字2的背景大不符恩是竖着的条纹。因为DNN基于输入和输出的统计联系进行学习,DNN不可避免地学习到了这种虚假的关联。如果训练数据和测试数据分布一样,这种混杂对于分类是有利的;但是如果这种模式被攻击者篡改,比如把数字1的背景换成竖着的,实现对抗攻击,这种混杂就是有害的。对抗训练常用于防御对抗样本,但它无法免疫未知的攻击。在现实中,移除未观测到的、未知的混杂因子是困难的。
原始数据
X
X
X和预测
Y
Y
Y的总效应和因果效应分别为
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X)和
P
(
Y
∣
d
o
(
X
=
x
)
)
P(Y|do(X=x))
P(Y∣do(X=x)),后门路径
X
←
C
→
Y
X \leftarrow C \rightarrow Y
X←C→Y的存在导致二者的差异,差异为混杂效应。生成对抗样本的过程中,用
δ
\delta
δ表示对抗性扰动,
f
i
(
⋅
)
f_i(\cdot)
fi(⋅)和
f
j
(
⋅
)
f_j(\cdot)
fj(⋅)分别表示DNN在类别
i
i
i和类别
j
j
j的输出值。对抗样本攻击中,有目标攻击
y
ˉ
\bar{y}
yˉ是一个预先指定的值,而无目标攻击是要分类错误
y
ˉ
≠
y
\bar{y} \neq y
yˉ=y即可。
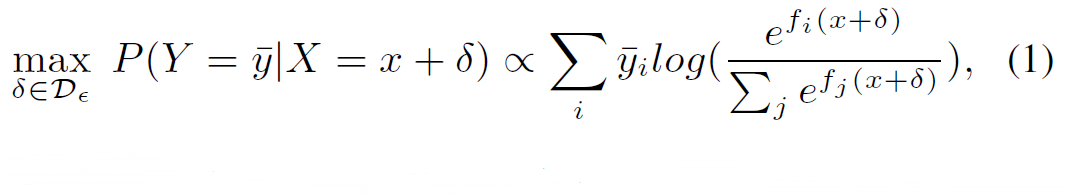
合法的
D
ϵ
D_\epsilon
Dϵ或保留语义特征(负责对抗样本也欺骗了人眼),也就是说
δ
\delta
δ捕获改变因果特征,
P
(
Y
∣
d
o
(
X
=
x
)
)
P(Y|do(X=x))
P(Y∣do(X=x))不会改变,因而对抗样本攻击实际上是在通过最大化混杂效应来优化
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X),实现
Y
=
y
ˉ
Y=\bar{y}
Y=yˉ。
对现有攻防的分析
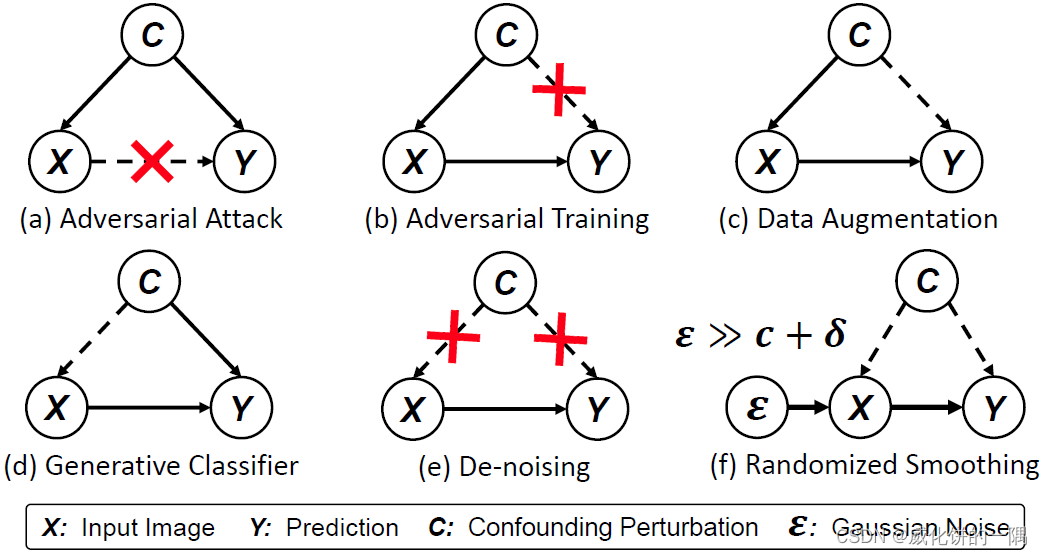
- 对抗样本攻击: 通过最大化混杂效应 X ← C → Y X \leftarrow C \rightarrow Y X←C→Y来覆盖 X → Y X \rightarrow Y X→Y,让预测出错
- 对抗训练: 使用对抗样本训练模型,最大化在有攻击 X = x + δ X=x+\delta X=x+δ下的模型预测准确率。因为攻击时使用的与训练时使用的对抗样本相似,对抗训练防止混杂 δ \delta δ改变预测结果,阻断了 C ↛ Y C \nrightarrow Y C↛Y
- 数据增强: 例如,用不同样本的线性组合来训练模型,增强鲁棒性,让微小的扰动 δ \delta δ只会产生较小的混杂效应,削弱 C → Y C \rightarrow Y C→Y的连接
- 生成模型: 使用生成式的模型,例如用VAE式的模型,在预测时寻找哪一个类别 y i y_i yi最有可能产生能代表输入 x x x的样本,生成的过程削弱了混杂因子在原图中的影响 C ↛ X C \nrightarrow X C↛X
- 去噪: 去除噪声对原图 ( C ↛ X ) (C \nrightarrow X) (C↛X)或者预测结果 ( C ↛ Y ) (C \nrightarrow Y) (C↛Y)的影响
- 随机平滑: 加入足够大的高斯噪声,覆盖自然的和攻击的混杂影响 c + δ c+\delta c+δ
CiiV框架
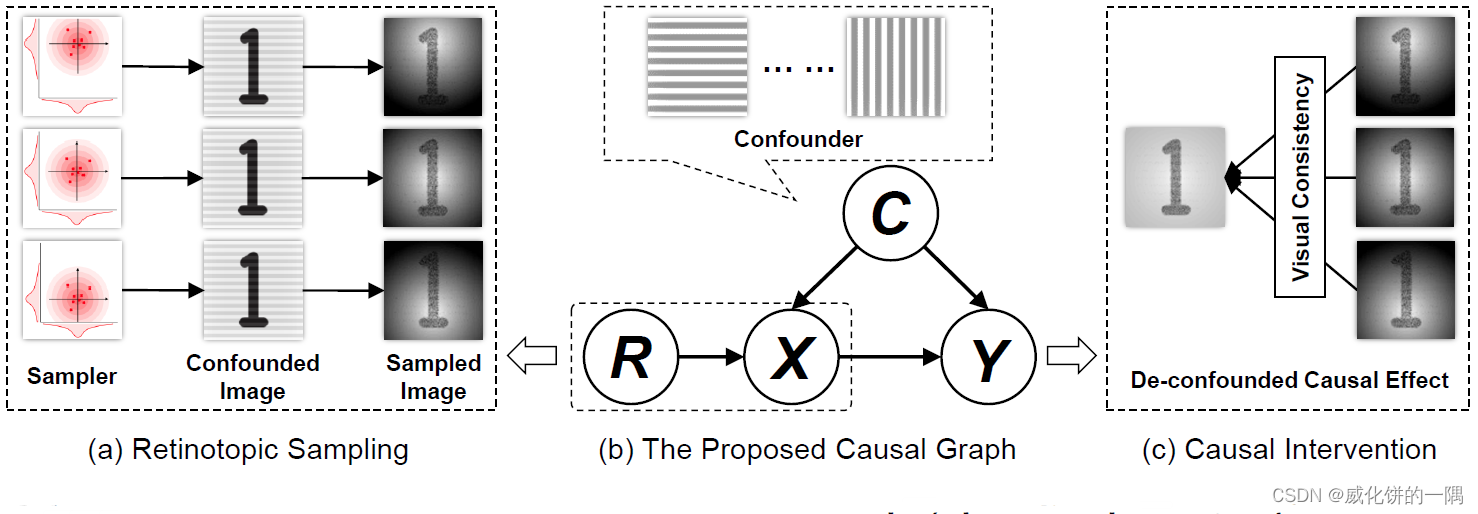
文中提出了CiiV框架,训练出鲁棒的模型,相比于正常的模型,训练过程中只多了Retinotopic Sampling操作。该操作将引入工具变量,进行干预的操作进行了实现。要实现,包含
g
r
x
(
⋅
)
g_{rx}(\cdot)
grx(⋅),
g
r
y
(
⋅
)
g_{ry}(\cdot)
gry(⋅)和
g
r
x
−
1
(
⋅
)
g_{rx}^{-1}(\cdot)
grx−1(⋅)三个部分。

具体而言,
g
r
x
(
⋅
)
g_{rx}(\cdot)
grx(⋅)为Retinotopic Sampling采样操作,采样的分布为
r
r
r,输入为样本
x
x
x,输出为
x
r
=
g
r
x
(
x
,
r
)
x_r=g_{rx}(x,r)
xr=grx(x,r),
⨀
\bigodot
⨀表示元素相乘,采样操作在给定的分布
r
r
r下执行
N
N
N次取平均:
g
r
x
(
x
,
r
)
=
r
⨀
1
N
∑
i
R
e
L
U
(
[
x
+
ϵ
i
∣
x
+
ϵ
i
∣
d
t
;
x
−
ϵ
i
∣
x
−
ϵ
i
∣
d
t
]
)
g_{rx}(x,r)=r \bigodot \frac{1}{N}\sum_{i}ReLU([\frac{x+\epsilon_i}{|x+\epsilon_i|_{dt}};\frac{x-\epsilon_i}{|x-\epsilon_i|_{dt}}])
grx(x,r)=r⨀N1i∑ReLU([∣x+ϵi∣dtx+ϵi;∣x−ϵi∣dtx−ϵi])
采样操作实现的效果是,对
r
r
r分布的中间关注更多,对周围的关注变少。而
g
r
y
(
⋅
)
g_{ry}(\cdot)
gry(⋅)可以为任意的一个神经网络表示,只需要加上上面的采样操作层即可。
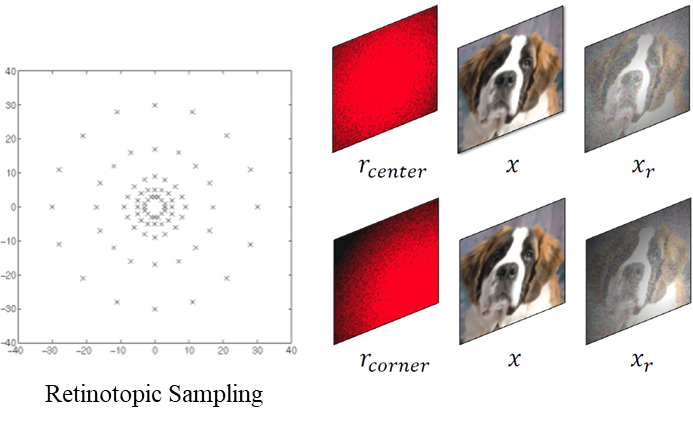
文中认为,
g
r
x
(
⋅
)
g_{rx}(\cdot)
grx(⋅)是采样操作,其逆操作
g
r
x
−
1
(
⋅
)
g_{rx}^{-1}(\cdot)
grx−1(⋅)是集成操作,也就是求
T
r
T_r
Tr个
r
r
r分布采样后的平均,其中
T
r
T_r
Tr表示采样操作中使用的𝑟分布的个数,训练阶段
T
r
=
10
T_r=10
Tr=10,预测阶段
T
r
=
1
T_r=1
Tr=1
P
(
Y
∣
d
o
(
X
=
x
)
)
=
g
r
x
−
1
(
g
r
y
(
x
,
r
)
)
≈
1
T
r
∑
r
g
r
y
(
x
,
r
)
P(Y|do(X=x))=g_{rx}^{-1}(g_{ry}(x,r)) \approx \frac{1}{T_r} \sum_r g_{ry}(x,r)
P(Y∣do(X=x))=grx−1(gry(x,r))≈Tr1r∑gry(x,r)
最后,使用神经网络加上采样层来拟合上式
X
→
Y
X \rightarrow Y
X→Y,使用交叉熵损失即可。特别的,由于训练过程不稳定,文中提出在交叉熵损失基础上,使用AVC loss
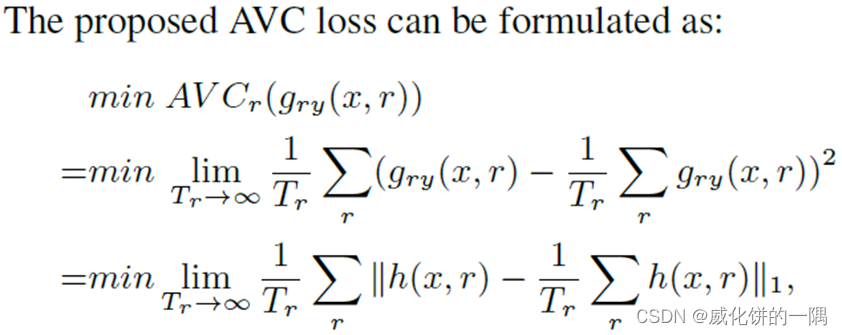
实验结果
定性结果更能说明效果,模型预测的任务是要预测类别,混杂因子是背景颜色。
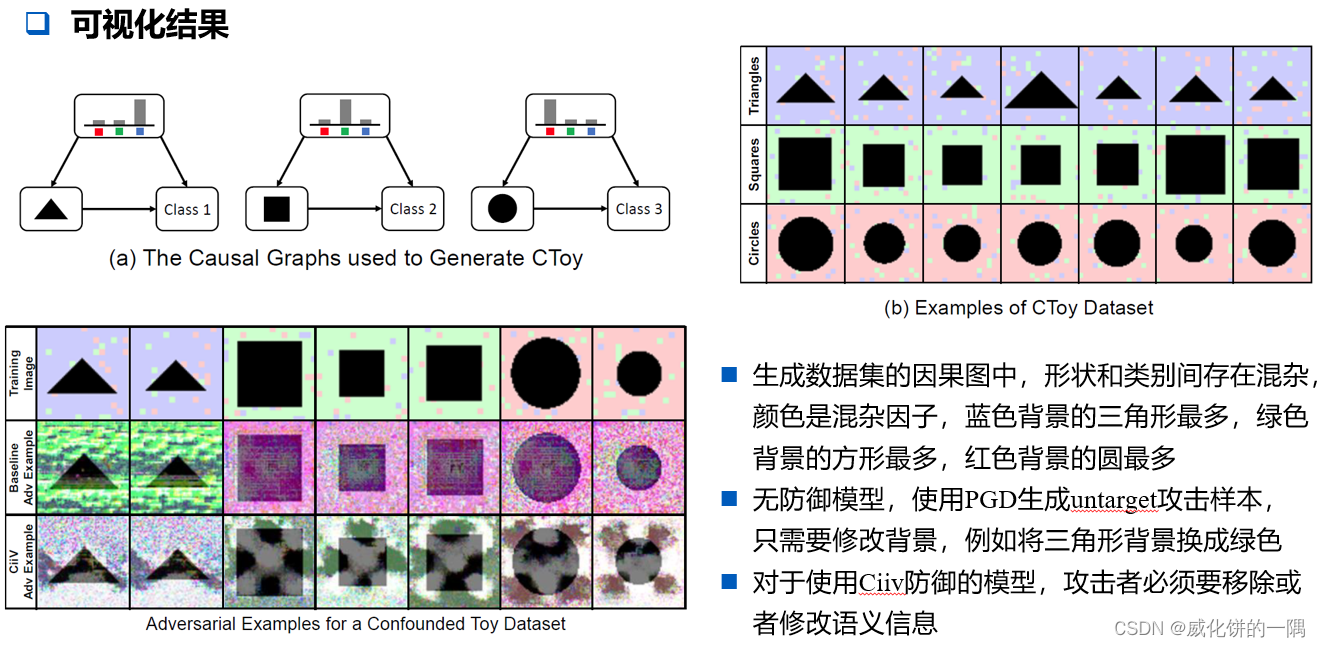
review
发现这篇文章有更新的版本投稿到了ICLR,但是撤稿了,有三个审稿人的意见,见openreview。求问,对抗样本研究方向,不承认对抗样本存在的假设吗,还是说需要不依赖这些假设进行方案设计?对假设进行严格的证明?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









