







 本文深入探讨了人脸检测、对齐、表示及识别的技术细节,涵盖了LBP特征、SVR、2D与3D对齐、深度学习网络结构、卡方距离与Siamese网络等关键技术,并讨论了可能的改进方向。
本文深入探讨了人脸检测、对齐、表示及识别的技术细节,涵盖了LBP特征、SVR、2D与3D对齐、深度学习网络结构、卡方距离与Siamese网络等关键技术,并讨论了可能的改进方向。
DeepFace: Closing the Gap to Human-Level Performance in Face Verification
CVPR 2014,FAIR
效果:LFW 97.5% (含2D人脸6个关键点标注)
face detection->face alignment->face representation->face identification
trick:
- face alignment 上采用了2D&3D 对齐。
- face representation自己设计的网络结构。
face detection
通过LBP处理特征,再用SVR学习到fiducial point的位置。
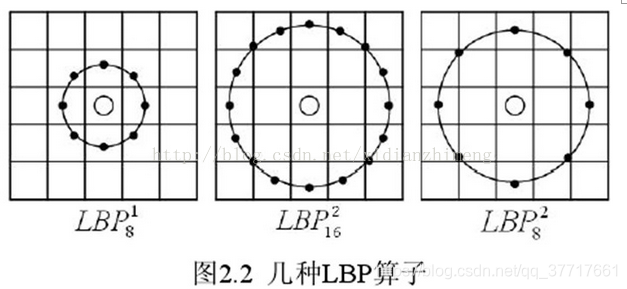
LBP特征
局部二值模式,用于描述图像局部特征的算子。
- 灰度不变性:抵抗线性光照。
- 旋转不变形:抵抗倾斜。
- 改进:圆形LBP,可控两个参数R:半径(决定二维空间尺度)、P:周围pixel个数(决定角度空间分辨率)。
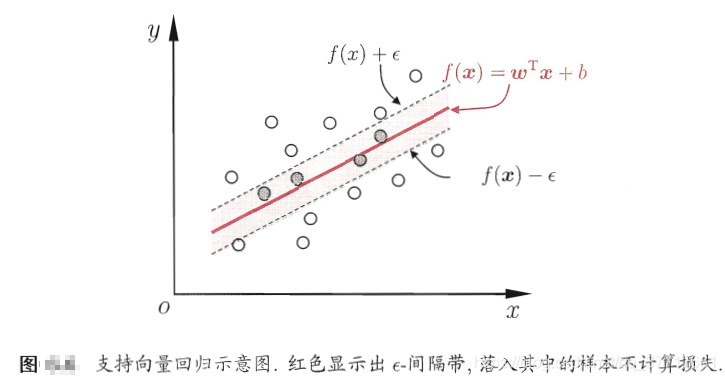
SVR为什么可以学习到fiducial point
SVR寻找一组数据的内在关系,找到一个回归平面,让集合的所有数据到该平面的距离最近。
SVR希望学习到一个函数f(x)即超平面使得与y尽可能接近,w、b是待确定的参数。此时相当于以f(x)为中心,构建一个宽度为2ε的间隔带,若训练样本落入此间隔带,被认为是正确的。
SVR就是SVM做回归用的方法,即输入标签是连续值的时候用的方法。
face alignment
参考论文:How far are we from solving the 2D & 3D Face Alignment problem? (and a
dataset of 230,000 3D facial landmarks),ICCV 2017,在3D标注数据集LS3D上达到接近饱和的性能
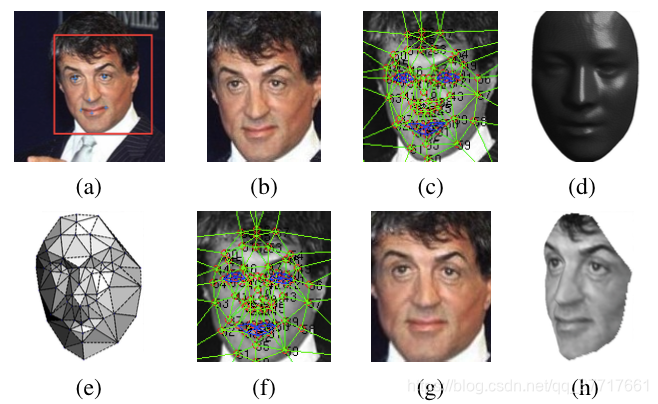
2D对齐(a~b)
基于前面学习到的6个基准点做2D裁剪。
通过堆叠4个HG层的网络生成Heatmaps,使RGB图像增加到67个通道
再用predict和groud truth之间的heatmaps(此处为confidence maps置信图:图像像素包含关键点的概率分布)代替L2损失。
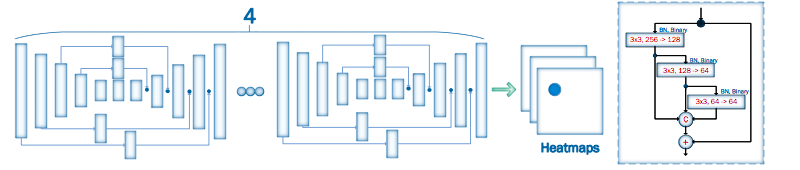
堆叠4个HG层
参考论文:Stacked Hourglass Networks for Human Pose Estimation](https://arxiv.org/pdf/1603.06937.pdf)),ECCV 2016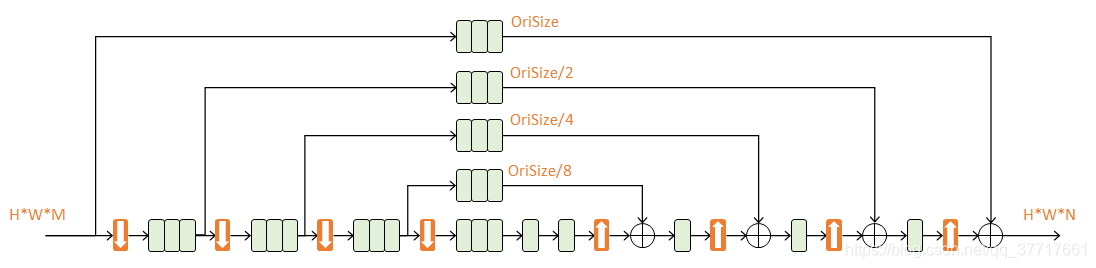
trick:捕捉不同尺度下图片所包含的信息 ,eg:方位、动作、相邻关节点,n阶Hourglass子网络提取了从原始尺度到1/2^n尺度的特征。不改变数据尺寸,只改变数据深度。
输入:单张RGB图像
输出:人体基准点的精确像素位置(67个2D基准点)
residual模块(下部分)提取了较高层次的特种功能,上部分保留了原有层次的信息。
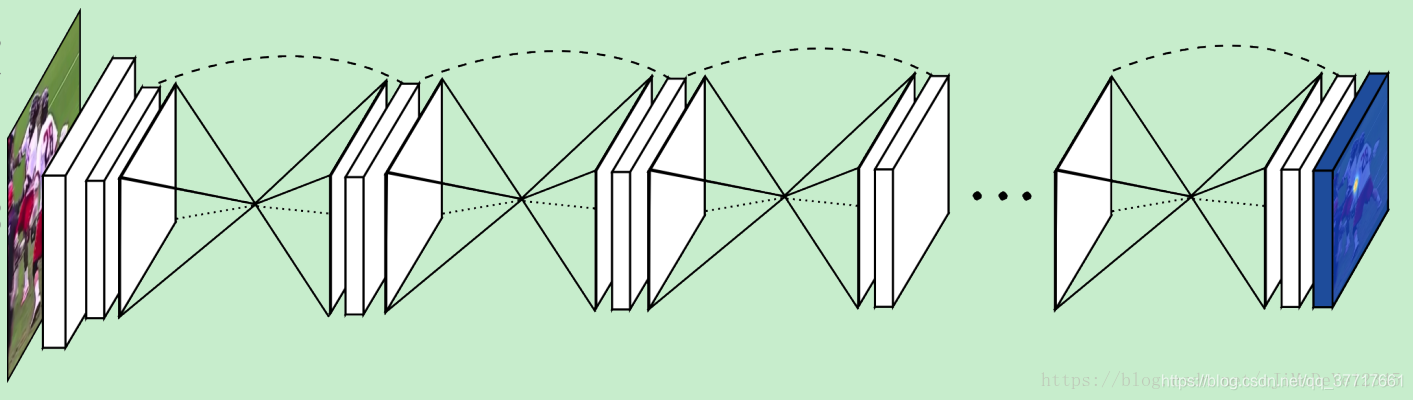
重复使用top-down(可用max pooling、1✖️1卷积)和bottom-up(可用最近邻差值)来推断2D基准点位置。
损失函数:intermediate supervision(中继监督的优化方式,对每个阶段都计算损失,抵抗反向传播的梯度消失,使底层参数也能正常更新)
2D-TO-3D对齐: 基于HG网络
trick:机器生成3D标注的数据集。
输入:RGB图像和2D基准点(67个)
输出:3D基准点
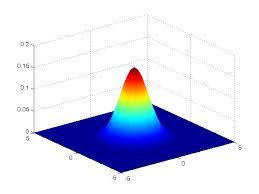
怎么做到的:以每个2D基准点为中心,std为1像素做出对应高斯分布,就能找到3D基准点的位置。
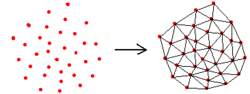
3D对齐(d~g): 基于Delaunay(三角剖分算法)
【定义】三角剖分 [1] :假设V是二维实数域上的有限点集,边e是由点集中的点作为端点构成的封闭线段, E为e的集合。那么该点集V的一个三角剖分T=(V,E)是一个平面图G,该平面图满足条件:
1.除了端点,平面图中的边不包含点集中的任何点。
2.没有相交边。
3.平面图中所有的面都是三角面,且所有三角面的合集是散点集V的凸包(任意点集中两点连线都是三角面)。
我理解的:T = (V,E)
->3D人脸图像->偏转放正
face representation

C1、M2、C3: 低水平特征的提取,边缘特征或者纹理特征。
其中M2降采样,保留显著特征,降低特征维度。
其中卷积层为什么可以提取提低水平特征? 经过特定构造的卷积核对原始图像进行卷积得到的特征图。如图所示:
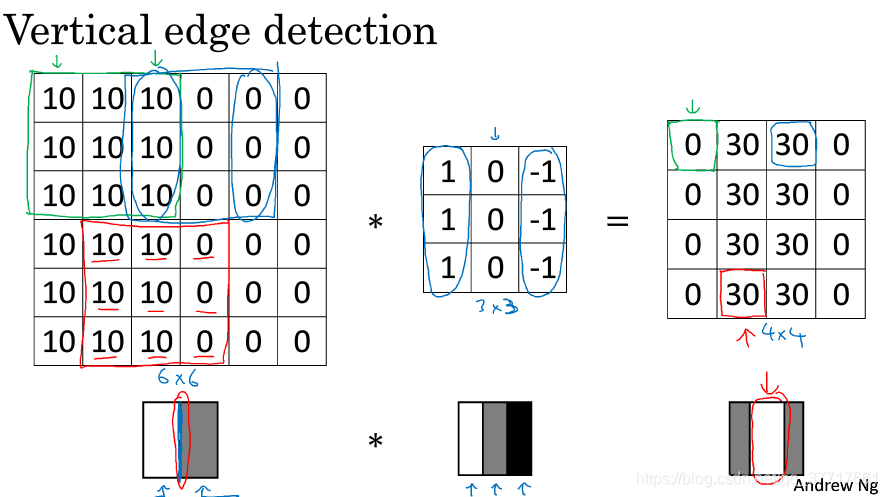
L4~L6:局部连接
每个神经元仅与输入神经元的一块区域相连接,不共享权重,相当于训练能区分不同区域的滤波器。eg:有效增加眼睛和眉毛的区分度。
F7~F8(F8为softmax):全连接层
捕捉较远区域的特征之间相关性。eg:眼睛和嘴巴的相关性
原因是softmax我理解有两个作用,一是取最大值作为预测,二是可以根据概率值得知对应特征之间的联系。
- 归一化、正则化 layer:限定一定的范围,找出图像中的不变量,抵抗几何变换的影响,eg:光照。
face identification
可以使用卡方距离或者Siamese网络
卡方距离
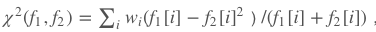
其中参数由线性SVM学得;
Siamese网络
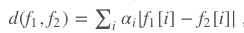
其中参数由标准交叉熵与反向传播方法所训练。
结论:
神经网络能work的一部分原因在于,一旦人脸对齐,人脸区域的特征就固定在某些像素位置上了。
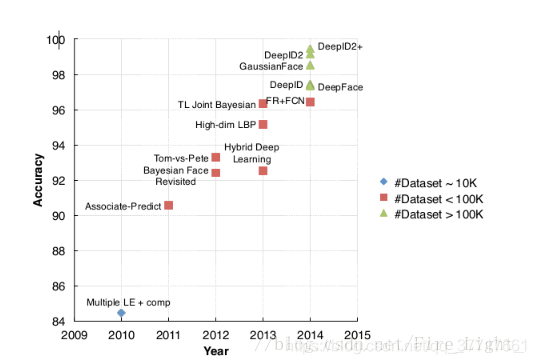
可能改进的方向
1,深度学习(神经网络结构的设计),基于fiducial point的学习,商汤科技在人脸方面的应用,目前已经看到deep learning在人脸表示和人脸特征点定位方面的工作,相信后续会有更多更好的工作出现;
2,大规模人脸搜索相关的应用近来开始被大家关注(比如最近百度上线的人脸搜索),这些应用中除了需要传统的人脸表示,还需要关注如何能够快速准确地在大规模人脸数据库中搜索到相似人脸,当然这部分工作可以借鉴其他视觉搜索中的方法,但人脸可能也会有自己的特殊性;
3,基于3D模型和具有深度信息的人脸识别,川大智胜的方法,在允许使用特殊设备的实际应用中,可以考虑用3D模型和深度信息来提高系统的稳定性;
4,在做人脸识别实际系统时,可以更关注姿态、遮挡、表情变化对于识别效果的影响,对于人脸光照问题,虽然之前学术界关注很多,但是对于实际数据(非实验室采集的光照模拟数据),可能基于大规模训练数据和feature learning就可以比较好的解决,反而是由于目前的人脸表示框架,对于大的姿态变化,遮挡以及表情变化引起的表观改变,很多情况下表现并不好,可能需要重新改变目前的人脸表示方式,比如采用类似推荐论文9中的方式,采用多个局部模型而不是一个整体模型来进行表示,还可以考虑一些人脸姿态/表情矫正方法;
5,可以考虑创建一个更大的人脸库(如果能达到真正意义上的大规模数据就更赞了),设计一个更加合理全面的评测协议;
LFW数据集介绍:无约束自然场景人脸识别数据集,该数据集由13000多张全世界知名人士互联网自然场景不同朝向、表情和光照环境人脸图片组成,共有5000多人,其中有1680人有2张或2张以上人脸图片。每张人脸图片都有其唯一的姓名ID和序号加以区分。

















 9417
9417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









