







前言
之前已经搭建过一个hadoop集群(搭建方法),在这个集群的基础上进行改进,引用Zookeeper来进行自动故障转移!
后续搭建Yarn-HA!!!点我!
搭建目标

HA简介
所谓HA(High Available),即高可用(7*24小时不中断服务)。
Hadoop集群有HDFS和YARN!Hadoop的HA指HDFS和YARN必须保证可用性强(不能轻易故障,保持24h可用)!
以HDFS为例:
必须进程: Namenode(1个) Danonode(N个)
可选进程: SecondaryNamenode (1个)
HA的核心: 保证Namenode和RecourceManager不能故障或在故障后可以快速容灾恢复!
HA的实现(以HDFS为例)
①为了避免Namenode的单点故障,可以启动多个Namenode!
②保证多个Namenode进程元数据必须同步
元数据: fsimage。 Namenode在格式化时,会生成空白的fsimage文件,此时让Namenode将格式化后的fsimage文件拷贝到另一个Namenode上即可!
edits:Namenode将edits文件发送给Journalnode,其他的Namnoede自己从Journalnode同步edits文件!
注意:
a)journalnode进程采用paxos协议设计,适合运行在奇数台机器!
b)如果要实现HA,至少要启动3台Journalnode!
c)如果启动了Journalnode,那么没有必要,也不能再启动 SecondaryNamenode
③当启动了多个Namenode时,只能选择其中的一个作为active状态的NN
其余的Namenode都只能作为standby状态
采用状态是为了标识哪个namenode是正在工作的,可以为客户端提供服务的NN,只有active状态的
NN可以接收客户端请求!
原则: 不能出现脑裂现象(不能同时出现两个active状态的namenode)
- 为什么要格式化?
格式化是为了:
①生成Namenode工作的目录(存放元数据)
②格式化是为了生成fsimage文件,每次NN启动都会先读取fsimage中的元数据
③为了生成Namenode的id和clusterId,所有的 Datanode在启动是都会根据clusterId向Namenode上报
HDFS的自动故障转移
①借助zookeeper集群
②一般采用sshfence,需要配置两台Namenode所运行机器的ssh互相联通
配置Zookeeper集群
1. 将压缩所包解压后修改cof文件名
重命名/opt/module/zookeeper-3.4.10/conf这个目录下的zoo_sample.cfg为zoo.cfg
mv zoo_sample.cfg zoo.cfg
2.在 /opt/module/zookeeper-3.4.10/目录下创建一个目录
mkdir -p zkData
3. 配置zoo.cfg文件
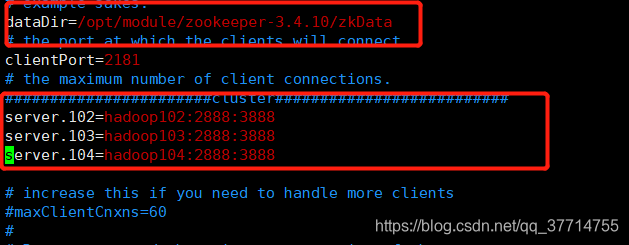 指定dataDir
指定dataDir
dataDir=/opt/module/zookeeper-3.4.10/zkData
指定服务端id以及leader端口号和选举互相通讯时端口号
#######################cluster##########################
server.102=hadoop102:2888:3888
server.103=hadoop103:2888:3888
server.104=hadoop104:2888:3888
配置参数解读
Server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
B是这个服务器的IP地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
4. 集群模式下配置一个文件myid
这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
在/opt/module/zookeeper-3.4.10/zkData目录下创建一个myid的文件
此文件为该节点的serverid 注意不能有空格和空行

这里配置的主机是hadoop102,为了方便所以配置为102!id可以随便起名字,原则是数字且不能重复。
vim myid
分发后再对每个节点上的myid进行修改!
配置并且启动zookeeper集群
@hadoop102 zookeeper-3.4.10]# bin/zkServer.sh start
@hadoop103 zookeeper-3.4.10]# bin/zkServer.sh start
@hadoop104 zookeeper-3.4.10]# bin/zkServer.sh start
Zookeeper遵循poxos协议,必须半数以上启动,集群才可用,当集群启动半数以上时开始选leader,一般来讲id大的有优势,以三台为集群来为例,如果102,103启动成功,则103为leader,104再启动后,只能作为follower,如果103挂掉,这个时候重新选举,
如果选举成功,推测是104为leader,其他的均为follower。
此为先启动
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









