






随着大模型应用的深化,向量数据库正在成为连接非结构化数据与智能应用的核心枢纽。在实际落地时,常用来:用户提问 → 向量化 → 向量库检索 → 拼接上下文 → 大模型生成回答
价值总结
-
语义理解:突破关键词匹配局限,实现概念级检索
-
效率提升:百万级向量检索耗时<50ms
-
上下文增强:为LLM提供精准的增强信息
-
动态适应:支持实时数据更新和增量学习
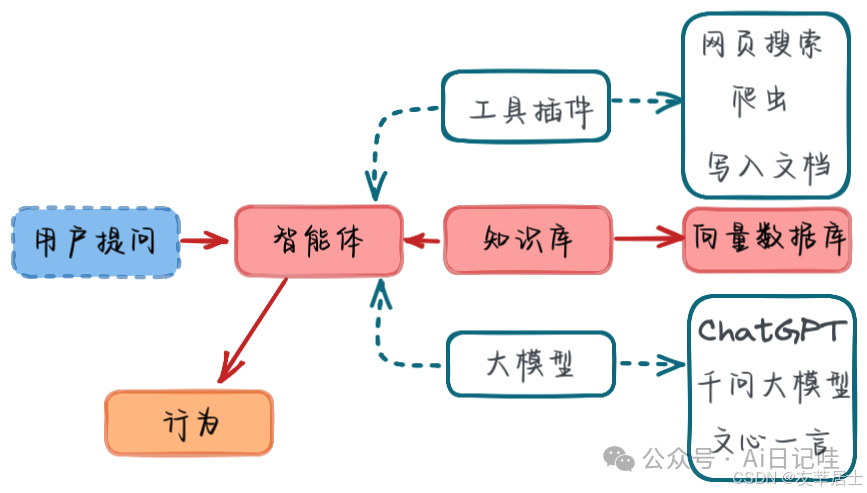
下面,让我们一起来了解一下究竟什么是向量数据库,向量数据库的原理是什么?
一、什么是向量数据库
一句话概括:向量数据库的核心是把文本转换为向量,然后存储在向量数据库中,并提供向量相似性检索
当用户输入问题时,将问题也转化为向量,在向量数据库中查找最相似的上下文向量,最后将文本返回给用户。
举个例子:
当有一份文档需要 GPT 处理时,假设这份文档是客服培训资料或操作手册,可先将这份文档的所有内容转化为向量,并存储到向量数据库中。
然后当用户提出相关问题时,把用户的搜索内容转换为向量,在向量数据库中搜索最相似的上下文向量,再返回给 GPT。
这样不仅能大幅减少 GPT 的计算量,提高响应速度,更重要的是能降低成本,并避开 GPT 的 tokens 限制。
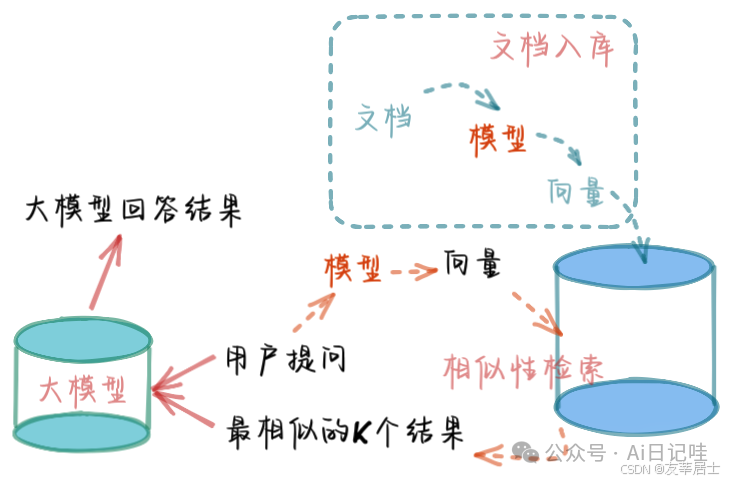
再举个例子:
当和 ChatGPT 之间有一段很长的对话时,可以将过去的对话以向量的形式保存起来。
当向 ChatGPT 提问时,将问题转化为向量,对过去所有的聊天记录进行语义搜索,找到与当前问题最相关的 “记忆”,一起发送给 ChatGPT,从而极大提高 ChatGPT 的输出质量。
二、向量数据库的技术原理
前面简单介绍了什么是向量数据库,接下来,让我们一起来了解一下向量数据库的技术原理!
2.1 词嵌入技术
传统数据库一般通过不同的索引方式(如 B Tree、倒排索引)和关键词匹配等方法实现,本质上基于文本精确匹配,语义搜索功能较弱。
例如,搜索 “小狗”,只能获取带有 “小狗” 关键词的结果,无法得到 “柴犬”“哈士奇” 等结果。
因为 “小狗” 和 “柴犬” 是不同关键词,传统数据库无法识别它们的语义关系。
可以使用模型提取不同关键词的特征,得到特征向量,不同向量之间可通过内积或余弦判断其相似关系,这样就可以使用特征向量进行语义搜索。

我们将关键词转换为特征向量的过程称为Embeding。
2.2 距离度量
下面,我们来了解一下如何度量两个向量的相似度。目前常见的向量相似性的度量方法有三种:
欧氏距离
余弦相似度
点积
欧式距离
欧式距离表示两个向量的距离,计算公式如下:
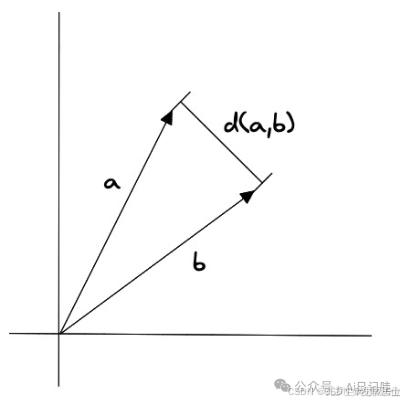
欧式距离可以反应两个向量之间的绝对距离,适用于需要考虑向量长度的相似度计算。
例如,在推荐系统中,需要根据用户的历史行为来推荐相似的商品,这种情况下,需要考虑用户历史行为的数量,而不仅仅是用户历史行为相似度。
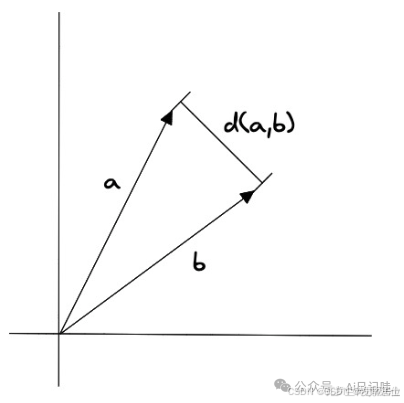
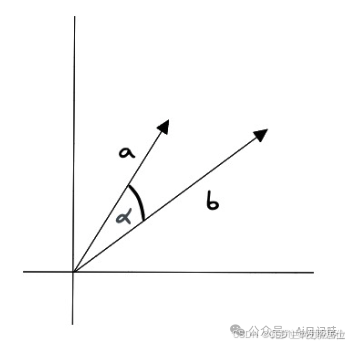
余弦相似度
余弦相似度表示两个向量之间夹角的余弦值,计算公式如下:
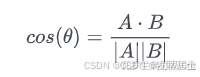
其中,和表示两个向量的模长,和表示向量,表示点积。
余弦相似度因为对向量做了归一化,所以对长度并不敏感,适合计算文档相似性。
点积
点积是指两个向量之间的点积值,计算公式如下:
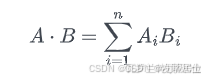
其中和表示向量,和表示向量的第个元素。
点积的有点是计算速度快,元素相乘并相加即可,同时兼顾了长度和方向,适用于图像识别、语义检索等场景。将归一化后的向量做点积,实际上就是余弦相似度。
2.3 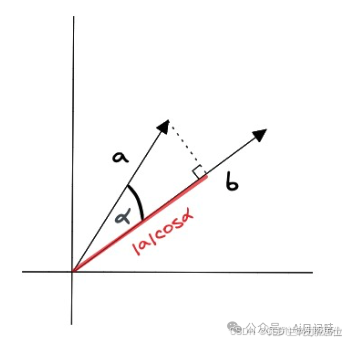 相似性检索
相似性检索
我们知道,可以通过比较向量之间的距离来判断他们相似度,那么如何将其应用到真实场景中呢?
想要在海量的向量中找到和查询向量最相似的向量,最朴素的方法是:查询向量和数据库中的所有向量都进行一次计算,然后从中找出来距离最小的TopK个向量。
朴素方法的好处是,召回的向量一定是全局最相似的,缺点也很明显,就是计算量太大,太耗时。
所以,我们需要一种高效的算法来解决这个问题。
目前,业界主流的方法是通过构建图索引的方式来时间最近邻检索,比较有名的是Hierarchical Navigable Small Word(HNSW)算法。
HNSW是一种基于图的近似最近邻搜索算法,主要用于在极大量的候选集中快速找到与查询点(Query)最近邻的K个元素。其结构如下:
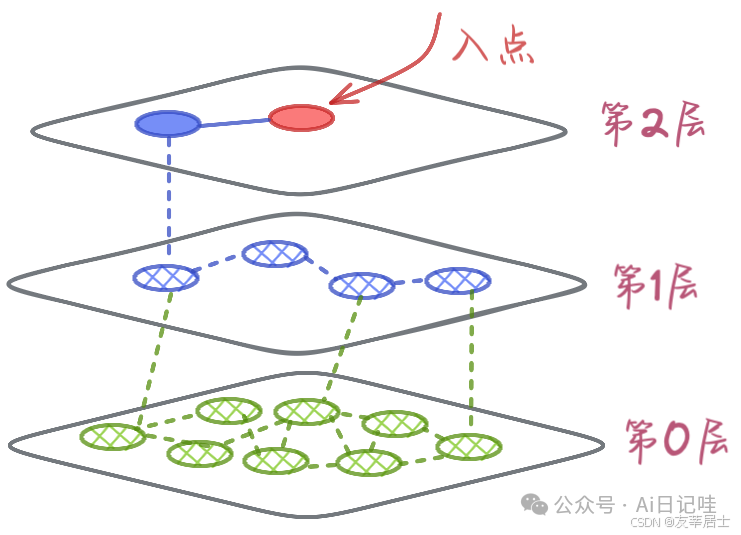
下面简述一下HNSW算法步骤:
建库(构建索引)
初始点选取:
在整个向量集合范围内,通过随机的方式确定一个点作为建库的初始点。这个初始点是后续构建层次结构的起始核心,它的选择完全是随机性的,不受向量自身属性的影响,为整个索引结构提供了一个起始的参照点。
构建超平面:
在确定初始点后,对于其余的向量点,按照特定的顺序将它们插入到合适的层中。在这个过程中,每一个点都会被赋予一个层号,这个层号清晰地表明了该点在整个层次结构中的位置。每一层都可以看作是一个独立的空间划分,不同层的点在后续的搜索和检索过程中有着不同的作用和意义。这个分层的过程是基于向量之间的某种内在关系或者预设的规则进行的,以构建出一个具有层次化特征的索引结构。
邻居选择:
运用启发式选边策略为每个点挑选邻居。这种策略会综合考虑向量之间的多种因素,例如向量的方向、模长以及在空间中的分布情况等。通过这样的方式,能够确保每个点的邻居具有多样性,避免邻居点过度集中在某个局部区域。这种多样性的邻居结构有助于在后续的检索过程中更全面、准确地找到与查询点相似的向量,提高算法的检索效率和准确性。
检索(最近邻检索)
顶层搜索启动:
当进行检索操作时,给定一个查询点,首先从索引结构的最顶层开始搜索。最顶层作为整个层次结构的起始搜索层,包含了相对较为宽泛的信息。从这一层开始搜索可以在较大范围内快速筛选出可能与查询点相关的区域,减少不必要的搜索范围,提高搜索效率的同时避免陷入局部最优解。
最近邻确定:
通过计算查询点与其他点之间的余弦相似度或距离等度量方式来确定最近邻。余弦相似度能够衡量两个向量在方向上的一致性,距离度量则可以从空间位置的角度反映向量之间的接近程度。根据具体的应用场景和数据特点选择合适的度量方法,准确地找出与查询点在语义或空间上最接近的点,这些点将作为检索结果的重要候选。
搜索加速:
在搜索过程中,利用剪枝和优先队列等技术提高搜索速度。剪枝技术可以根据一定的规则,在搜索过程中提前排除那些明显不可能是最近邻的分支,减少不必要的计算和搜索。优先队列则可以按照某种优先级顺序对搜索过程中的中间结果进行排序和存储,优先处理最有可能成为最近邻的点,进一步加快搜索速度,使整个检索过程更加高效。
HNSW 算法具有高效性,通过构建多层超平面将高维数据点组织成层次化结构,降低查找最近邻时间复杂度至O(log n)。
具有近似性,采用小世界导航图结构使搜索结果有近似性且可通过调整参数平衡近似程度与搜索性能。
同时还具有可扩展性,能轻松支持新增、删除数据点及高维空间搜索。
三、总结
本文主要介绍向量数据库的原理与实现,内容涵盖向量数据库的基本概念、相似性搜索算法、相似性测量算法。
向量数据库是一个新兴领域,当前大部分向量数据库公司的估值因 AI 和 GPT 的发展而快速增长。
技术选型建议
| 场景特征 | 推荐数据库 | Spring集成方案 |
|---|---|---|
| 超大规模数据 | Milvus | Milvus Java SDK |
| 实时性要求高 | Redis | Spring Data Redis + RediSearch |
| 多模态数据 | Weaviate | Weaviate Java Client |
| 云原生部署 | Pinecone | REST API调用 |
| 开源可控 | Qdrant | gRPC接口集成 |

















 6008
6008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









