







论文地址:https://arxiv.org/pdf/2004.10934.pdf
yolov4和yolov5两个模型相继在四五月份出来(尽管后者的名字还存在一些争议),最近正好有一个目标检测的任务要做,就试了试yolov5,只用yolov5s网络的默认参数在自己的数据集上训练就达到了很好的检测效果,速度也相当快(在GTX1070上检测一帧640x640的图像耗时仅仅8ms)。然而yolov5在很大程度上只是从工程上对yolov4进行了优化,也没有相应的论文,所以把yolov4的论文仔细阅读了一下,发现文章里对当前目标检测领域里一些优秀的实践做了较好的归纳,故记录一下文章内容。
先引用一张图
有很多方法可以提升神经网络的准确率,在实践中评判一种方法的好坏主要看两点,一是在大规模数据集上是否work,二是是否有理论依据。我们假设某些具有普适性的方法包括:Weighted-residual-connection(WRC),cross-stage-partial-connections(SCP),cross mini-batch Normalization(CmBN),self-adversarial-training(SAT)以及mish-activation。我们还使用了一些新的tricks,包括Mosaic data augmentation,DropBlock regularization,CIoU loss,设计了一个YOLO-V4,并且在MS coco数据集中取得了新的state-of-the-art的结果:在Tesla V100显卡能达到43.5% AP(65.7% AP)的精度,且达到~65FPS的速度。
主要贡献:
1.开发了一个快速而准确的目标检测模型,仅仅使用一块1080Ti或2080Ti就能够完成训练;
2. 在训练过程中,验证了目标检测的Bag-of-Freebies和Bag-of-Specials对模型的影响;
3. 简化以及优化了一些最新提出的算法,包括(CBN,PAN,SAM),从而使Yolo-V4能够在一块GPU上就可以训练起来。
一个目标检测算法通常包括三个部分:Backbone, Neck和Head
Backbone: 算法的主干网络,主要用于对图像的特征提取,一些常用的分类模型的卷积层部分,可以在Imagenet上进行预训练,如VGG16,19,ResNet-50, ResNeXt-101, Darknet53,和一些轻量级网络,如MobilenetV1,2,3 ShuffleNet1,2;
Neck:特征融合部分,对主干网络的特征层进行加工,使其更加适合于检测任务,主要包括两种:1. additional blocks: SPP,ASPP in deeplabV3+,RFB,SAM; 2 Path-aggregation blocks: FPN, PAN, NAS-FPN, BiFPN, ASFF, SFAM;
Heads(检测头):算法输出的结果,例如直接预测bbox的x,y,w,h以及类别,或是想得到一个heatmap
密集型预测(一阶段方法):
anchor-based: RPN, SSD, YOLO, RetinaNet
anchor-free: CornerNet,CenterNet, MatrixNet, FCOS
稀疏型预测(二阶段方法):
anchor-based: R-CNN系列
anchor-free: RepPoints
Bag of freebies
使用一些训练技巧,在不增加模型前向计算耗时的前提下使模型取得更好的准确度。
首先是一些数据增广的方法
主要有两种:色彩方面的增强(改变图像的像素值),和几何增广。
色彩增广:对比度增广,亮度增广,以及HSV空间增广;
几何增广:随机翻转,随机裁剪,拉伸,旋转;
还有一些改善目标遮挡等问题的数据增广方法。
1.随机裁剪矩形区域,并用0填充,如random erase和CutOut算法;
2.随机裁剪多个矩形区域,如hide-and-seek, grid mask;
3.MIX-UP方法,Mix-up在分类任务中,将两个图像按照不同的比例相加,在目标检测中的做法就是将一些框相加,这些label中就多了一些不同置信度的框。
4.style-transfer GAN做数据增强。
解决数据不均衡的方法
数据不均衡主要表现在两个方面,一是背景类和前景类之间的数据不均衡,二是不同前景类之间的数据不均衡。比较经典的方法包括:two-stage算法中使用的难例挖掘,Focal loss, 以及对于one-hot编码后label没有关联的问题进行label-smooth。
改进损失函数
相较于之前计算独立计算bbox的坐标、宽高的偏差,计算IOU的loss更具优势,后者既考虑到了目标的整体性,还具备尺度不变性。
Bag of specials
一些额外的模块,以增加较少计算量为代价来提升模型的准确率,如特征增强模块。主要包括以下方法:
增大感受野
SPP:主要解决的问题是网络中有全连接层时,不同大小目标区域的特征输入到检测头时维度需要保持一致,具体做法是把特征图划分为固定的块数进行pooling操作
ASPP:
RFB:对同一个特征图使用几个不同dilated ration的空洞卷积操作,提取到不同大小感受野的特征,并进行融合
注意力机制
1.通道注意力:在特征图中引入一个1x1xC的weights,对每个通道赋予不同的权重,C为特征层的通道数,这里有SEnet;
2.空间注意力:在HW维度上加入attention;
通道+空间:同时用到上面两种方法;
特征融合
1.Skip connection:融合低层和高层的信息,如Unet
hyper-column: 使用不同kernel size的卷积融合不同大小感受野的信息,如Inception
2.FPN,ASFF,BiFPN:将深层特征图上采样之后与浅层特征图融合
激活函数
LReLU和PReLU解决输出小于零时ReLU的梯度为零的问题,ReLU6和hard-Swish为量化网络设计的,SELU对神经网络进行自归一化。
后处理
NMS,soft NMS,DIoU NMS
YOLO-v4方法
针对实际生产系统中的高效计算而设计,而不是理论上的指标,提供两种实时的网络选择:
1.对于GPU:CSPResNeXt50 ,CSPDarknet53
2.对于VPU:EfficientNet-lite , MixNet [76] , GhostNet [21] , MobileNetV3
结构选择
在ImageNet分类方面,CSPResNext50比CSPDarknet53好,然而就检测MS COCO数据集上的对象而言,CSPDarknet53比CSPResNext50更好。
对于分类最佳的参考模型对于检测器并非总是最佳的,检测任务不同于分类任务主要表现在:
1.更大的网络输入,用于检测小目标
2.更多的层-以获得更大的感受野来覆盖增大的输入图像
3.更多的参数-为了增强从单张图像中检测出不同大小的多个对象的能力
在CSPDarknet53上添加SPP块,显著增加了感受野,分离出最重要的上下文特征,并且几乎不会降低网络操作速度。使用PANET代替YOLOv3中使用的FPN作为不同深度的特征聚合方法,用于多尺度检测。
最后,选择 CSPDarknet53 为主干网络、SPP模块、PANET路径聚合Neck和YOLOv3(基于锚点的)检测头作为YOLOv4的整体结构。
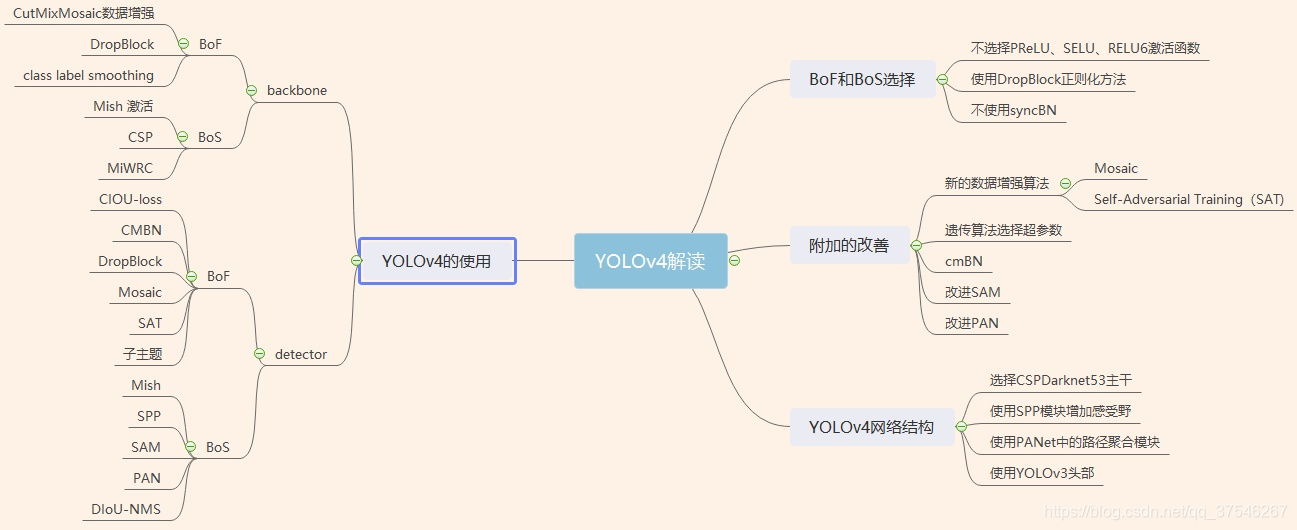
BoF和BoS的选择
为了改进目标检测训练,CNN通常使用以下方法:
激活:ReLU,leaky-ReLU,parameter-ReLU,ReLU6,SELU,Swish或Mish
边界框回归损失:MSE,IoU,GIoU,CIoU,DIoU
数据增强:CutOut,MixUp,CutMix
正则化方法:DropOut, DropPath ,Spatial DropOut或DropBlock
通过均值和方差对网络激活进行归一化:Batch Normalization (BN),Cross-GPU Batch Normalization (CGBN or SyncBN), Filter Response Normalization (FRN), orCross-Iteration Batch Normalization (CBN)
跨连接:Residual connections, Weightedresidual connections, Multi-input weighted residualconnections, or Cross stage partial connections (CSP)
在激活函数方面,PReLU和SELU更难训练,ReLU6是专门为量化网络设计的,因此不选择使用它们。Drop-Block与其他方法相比具有显著优势,选择了DropBlock作为我们的正则化方法。至于标准化方法的选择,由于专注于仅使用一个GPU的训练策略,因此不考虑syncBN。
其他的改善
1。引入了一种新的数据增强方法:Mosaic, and Self-Adversarial Training (SAT)
2.应用遗传算法选择最优的超参数
3.修改了一些现有方法,使我们的设计适合进行有效的训练和检测-改进的SAM,改进的PAN ,以及跨小批量标准化(CmBN)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









