







 本文介绍了Spark SQL如何支持外部数据源,包括内置和第三方数据源的使用,如CSV、JSON、Hive、MySQL等。通过DataFrame/Dataset接口,实现了数据的读取和写入。详细阐述了BaseRelation、RelationProvider、TableScan等相关接口,以及Catalog API在管理metadata中的作用,如查询数据库、注册视图、检查表缓存和UDF。
本文介绍了Spark SQL如何支持外部数据源,包括内置和第三方数据源的使用,如CSV、JSON、Hive、MySQL等。通过DataFrame/Dataset接口,实现了数据的读取和写入。详细阐述了BaseRelation、RelationProvider、TableScan等相关接口,以及Catalog API在管理metadata中的作用,如查询数据库、注册视图、检查表缓存和UDF。
简介:
随着Spark1.2的发布,Spark SQL开始正式支持外部数据源。Spark SQL开放了一系列接入外部数据源的接口,来让开发者可以实现。
这使得Spark SQL支持了更多的类型数据源,如json, parquet, avro, csv格式。只要我们愿意,我们可以开发出任意的外部数据源来连接到Spark SQL。之前大家说的支持HBASE,Cassandra都可以用外部数据源的方式来实现无缝集成。
引入:
在没有DF/DS时Core,SQL,Streaming,MLlib等框架的数据通过rdd共享
Core,SQL,Streaming,MLlib等框架 ==> RDD ==> (现在)DataFrame/Dataset 打通整个Spark生态栈的利器
如json、csv、hdfs、hive、jdbc、s3、parquet、es、redis、cassandra、hbase.......都可以转化为DF/DS处理
以上数据对于Spark来说分为两大类:build-in、3th-party
build-in:不需要加载什么,可以直接使用。如:json、parquet...
3th-party:需要加载第三方的包,辅助网站:https://spark-packages.org/
DF外部数据源的两大好处:
read and write
示例:
build-in 3th-party
spark.read.format("csv/json/com.ruoze.com.XXX").load()
df.write.format("").save()
dept : hive/sparksql
emp : mysql
读MySQL中emp表的数据:
val empDF = spark.read.format("jdbc")
.options(Map(
"url"->"jdbc:mysql://ruozehadoop000:3306/sqoop?user=root&password=123456",
"dbtable"->"emp",
"driver"->"com.mysql.jdbc.Driver")).load()
读hive/sparksql中dept表的数据:
val deptDF = spark.table("dept")
即可通过DateFrame直接操作dept和emp表
读取MySQL中emp表数据并创建为临时表emp_mysql
CREATE TEMPORARY TABLE emp_mysql
USING org.apache.spark.sql.jdbc
OPTIONS (
url "jdbc:mysql://ruozehadoop000:3306/sqoop?user=root&password=123456",
dbtable "emp",
driver "com.mysql.jdbc.Driver"
)
将empDF的数据写到MySQL中:
empDF.write.mode("overwrite").format("jdbc")
.option("url", "jdbc:mysql://ruozehadoop000:3306/sqoop?user=root&password=123456")
.option("dbtable", "test_emp").option("user", "root")
.option("password", "123456")
.option("driver","com.mysql.jdbc.Driver").save()
PPD介绍: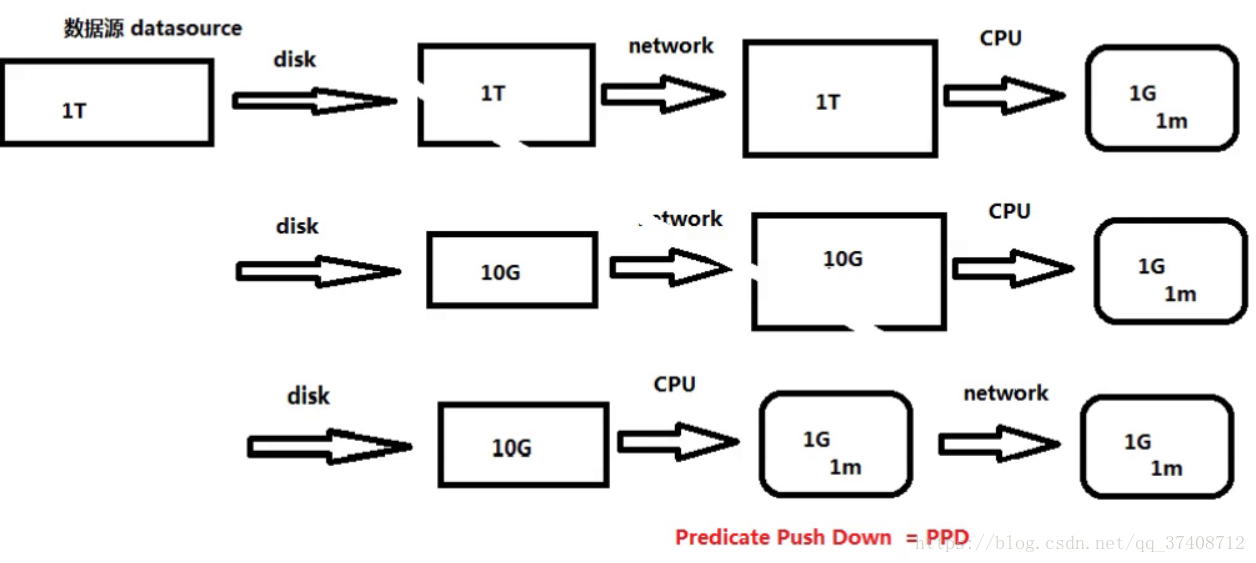
abstract class BaseRelation <== 定义外部数据源数据的schema信息
trait RelationProvider <== 产生BaseRelation 的 Relation
trait TableScan //对应图第一行的方式 <== 思考:如何更有效的读取外部数据源的数据
def buildScan(): RDD[Row]
trait PrunedScan {//对应图第二行的方式 <== 只读取需要的列,数据量小了很多
def buildScan(requiredColumns: Array[String]): RDD[Row]
}
trait PrunedFilteredScan {//对应图第三行的方式 <== 将计算提前,减少网络传输的数据
def buildScan(requiredColumns: Array[String], filters: Array[Filter]): RDD[Row]
}
trait InsertableRelation {//有这个接口才能把数据写回去
def insert(data: DataFrame, overwrite: Boolean): Unit
}
Catalog API:
DataSet 和Dataframe API 支持结构化数据分析,而结构化数据重要的是管理metadata。这里的metadata包括temporary metadata(临时表);registered udfs;permanent metadata(Hive metadata或HCatalog)。
早期Spark版本并未提供标准的API访问metadata,开发者需要使用类似show tables的查询来查询metadata;而Spark 2.0 在Spark SQL中提供标准API 调用catalog来访问metadata。
访问Catalog
建立SparkSession,然后调用Catalog:
val catalog = sparkSession.catalog
查询数据库
catalog.listDatabases().select("name").show()
listDatabases可查询所有数据库。在Hive中,Catalog可以访问Hive metadata中的数据库。listDatabases返回一个dataset,所以你可以使用适用于dataset的所有操作去处理metadata。
用createTempView 注册Dataframe
早期版本Spark用registerTempTable注册dataframe,而Spark 2.0 用createTempView替代。
df.createTempView("sales")
一旦注册视图,即可使用listTables访问所有表。
查询表
catalog.listTables().select("name").show()
检查表缓存
通过Catalog可检查表是否缓存。访问频繁的表缓存起来是非常有用的。
catalog.isCached("sales")
默认表是不缓存的,所以你会得到false。
df.cache()
catalog.isCached("sales")
现在将会打印true。
删除视图
catalog.dropTempView("sales")
查询注册函数
catalog.listFunctions().
select("name","description","className","isTemporary").show(100)
Catalog不仅能查询表,也可以访问UDF。上面代码会显示Spark Session中所有的注册函数(包括内建函数)。

















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









