







 本文探讨了单目3D物体检测中离散输出表示的局限性,提出将离散输出转化为深度空间概率分布,以考虑维度差距和深度不确定性。实验表明,这种方法显著提升了检测器的性能,尤其是在召回率方面。
本文探讨了单目3D物体检测中离散输出表示的局限性,提出将离散输出转化为深度空间概率分布,以考虑维度差距和深度不确定性。实验表明,这种方法显著提升了检测器的性能,尤其是在召回率方面。
Title: 深入研究单目 3D 物体检测的输出表示
Abstract
单目 3D 对象检测旨在从单个图像中识别和定位 3D 空间中的对象。最近的研究取得了显着的进展,而所有这些研究都遵循基于 LiDAR 的 3D 检测中的典型输出表示。
然而,在本文中,我们认为现有的离散输出表示不适合单目 3D 检测。具体来说,单目3D检测只有二维信息输入,而需要输出三维检测。这一特性表明单目 3D 检测本质上不同于具有相同维度输入和输出的其他典型检测任务。尺寸差距导致估计深度误差的下限较大。
因此,我们建议将现有的离散输出表示重新表示为根据深度的空间概率分布。这种概率分布考虑了由于缺乏深度维度而导致的不确定性,使我们能够准确、全面地表示 3D 空间中的物体。
大量的实验展示了我们的输出表示的优越性。因此,我们将我们的方法应用于 12 个 SOTA 单目 3D 探测器,持续将其平均精度 (AP) 相对提高约 20%。源代码将很快公开。
==问题导读==:
所谓的离散输出指的是什么?
所谓的深度的空间概率分布指的是什么?怎么得到和利用?这么做有什么直观地好处?
一、Introduction
为了提高准确性,先前的工作做了很多尝试,包括利用估计深度图、几何性质以及网络设计
所有先前的单目作品都采用了早期检测任务中出现的典型输出表示 ,即2D框检测与对应的3D框,其中3D框被视为最终结果。然而,这种离散输出表示忽略了单目 3D 检测和其他检测任务之间固有的巨大差距。如表1所示,我们总结了不同检测任务的输入/输出及其在源域中的维度。对于单目3D检测,需要推理高维3D框,而只有低维信息输入。这个差距在其他两个检测任务中并不存在,我们的定量实验证明正是维度差距导致单目3D检测的检测精度较低。

作者分析了深度误差,得出结论:深度误差随着深度的增长呈指数增长。我们还展示了一个理论下界,它呈二次方增加(详细推导请参见第 3.2 节)。 SOTA 探测器中的深度误差和理论下限都表明,对于不靠近的物体,估计深度无法准确。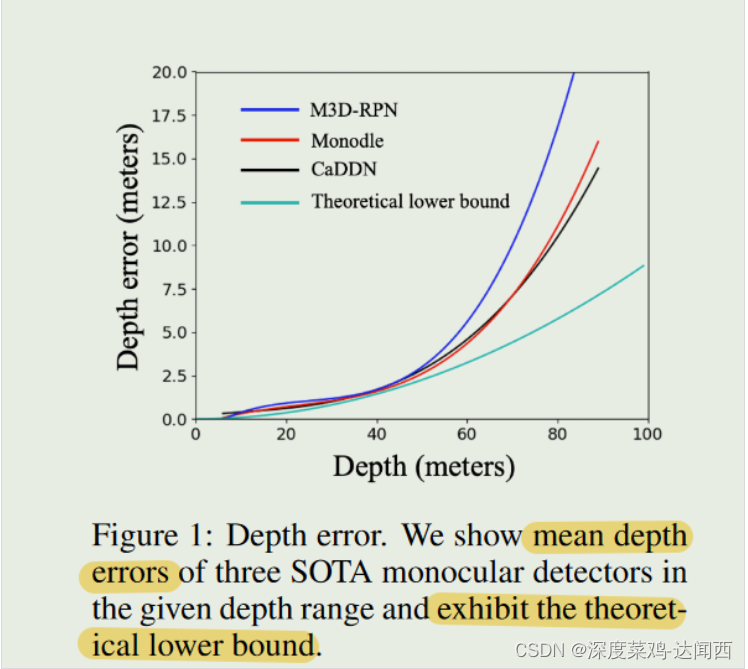 从固有的尺寸差距和由此产生的大深度误差的角度来看,我们认为现有的离散深度预测表示对于单目 3D 检测来说并不是最优的。大的深度误差意味着预测的深度具有很大的不确定性,由此产生的离散3D框预测不能准确、全面地表示3D空间中的物体状态。因此,在本文中,我们的目标是重新制定单目 3D 检测的输出表示,以考虑固有的维度差距和深度不确定性。
从固有的尺寸差距和由此产生的大深度误差的角度来看,我们认为现有的离散深度预测表示对于单目 3D 检测来说并不是最优的。大的深度误差意味着预测的深度具有很大的不确定性,由此产生的离散3D框预测不能准确、全面地表示3D空间中的物体状态。因此,在本文中,我们的目标是重新制定单目 3D 检测的输出表示,以考虑固有的维度差距和深度不确定性。
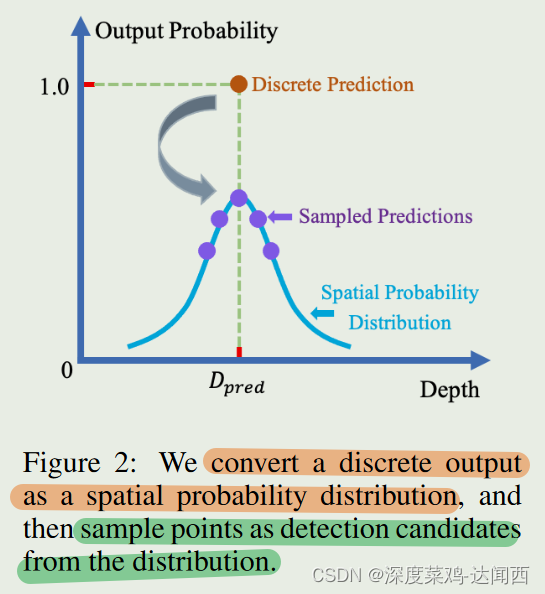
我们的重新表述包括两个步骤:
-
首先,如图 2 所示,我们使用正态分布将每个离散检测输出转换为空间概率分布,其中标准差随着深度的增长而增加。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









