







环境
我的环境是:python3.5 + scrapy 2.0.0
爬取内容和思路
爬取内容:微博热搜的关键词,链接,以及导语,即简要概述热搜内容的一小段话
思路:
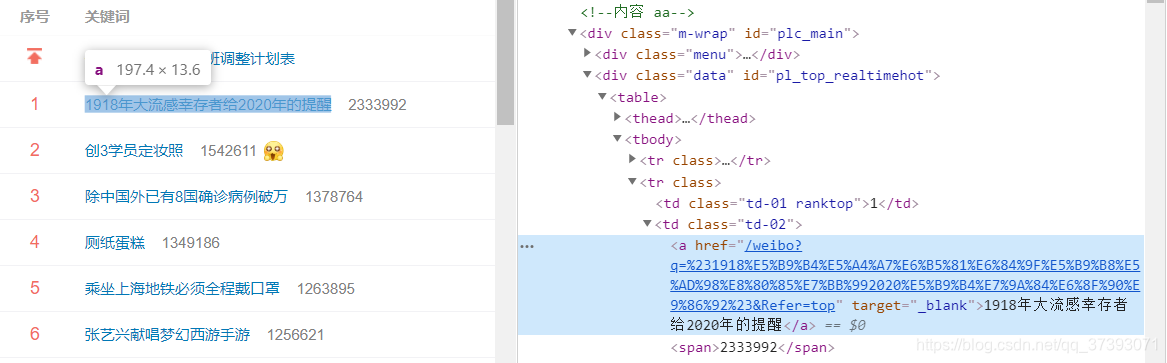
- 对于热搜链接:通过热搜关键词所在标签的属性再加上前缀即可(如图1)
- 对于关键词:进入关键词所在链接,一般会有一个如图2所示的位置,根据标签解析出内容;如果没有,存入“无”
- 对于导语:也是在关键词链接里边(如图3),通过解析获得;如果没有,爬取页面中的一条微博截取
- 对于推荐类(如图4):一般是广告之类,不在所爬取范围之内,可以在提取关键词链接时,通过标签最后位置是否为 “荐” 进行一个过滤
- 关于文件保存,先将所爬取内容根据 关键词,导语,链接 的方式写入本地 txt
- 关于邮箱发送,在 pipelines 文件中重写 close_spider 函数,将保存在本地的 txt 文件发送给你想要发送的邮箱
关于最后一点,真滴是让我最头疼的一部分,我这次使用的 scrapy 自带的 mail 模块进行发送,踩坑无数,这部分调试占用了很大部分时间



实现
文件结构
具体实现
主要工作在 weiboresou.py items.py 以及pipelines.py
# weiboresou.py
# -*- coding: utf-8 -*-
import scrapy
import time
from ..items import WeiboItem
header = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
class WeiboresouSpider(scrapy.Spider):
name = 'weiboresou'
allowed_domains = ['s.weibo.com']
start_urls = ['https://s.weibo.com/top/summary?cate=realtimehot']
def parse(self, response):
base_url = 'https://s.weibo.com/'
resouurlList = []
templist = response.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr')
#将广告删掉
#广告判断标准:后边标志是‘荐’
for temp in templist[:40]:
if(len(temp.xpath( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











