







 本文深入探讨了Hash表的构建过程,包括选取合适的Hash函数和处理冲突的方法,以及顺序查找、折半查找等基本查找算法的特点。理解这些概念对于提高数据检索效率至关重要。
本文深入探讨了Hash表的构建过程,包括选取合适的Hash函数和处理冲突的方法,以及顺序查找、折半查找等基本查找算法的特点。理解这些概念对于提高数据检索效率至关重要。



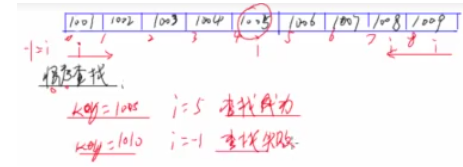
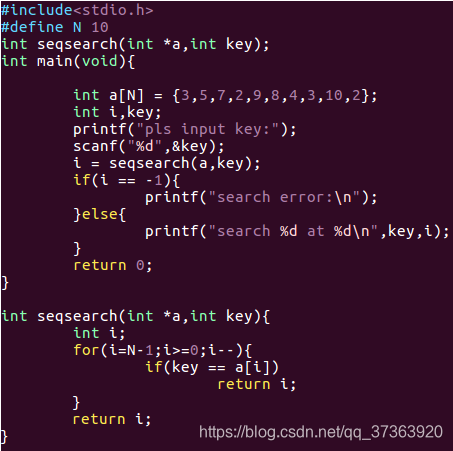
一般顺序表的第0个位置不放数据 ,作为监视哨 , 要把查找的key放到监视哨里面
从后往前查找, 如果查找到, 把对应索引返回, 如果没有查找到 , 我们的key因为是查找本体值, 所以一定能查找到, 当查找从最后到1为止没有查找到时, 那么key肯定相等肯定能查找到,返回索引0 所以如果返回是0表示查找失败, 非0表示成功
顺序查找 :从前到后 , 或者从后到前按着顺序一个 一个去查找,


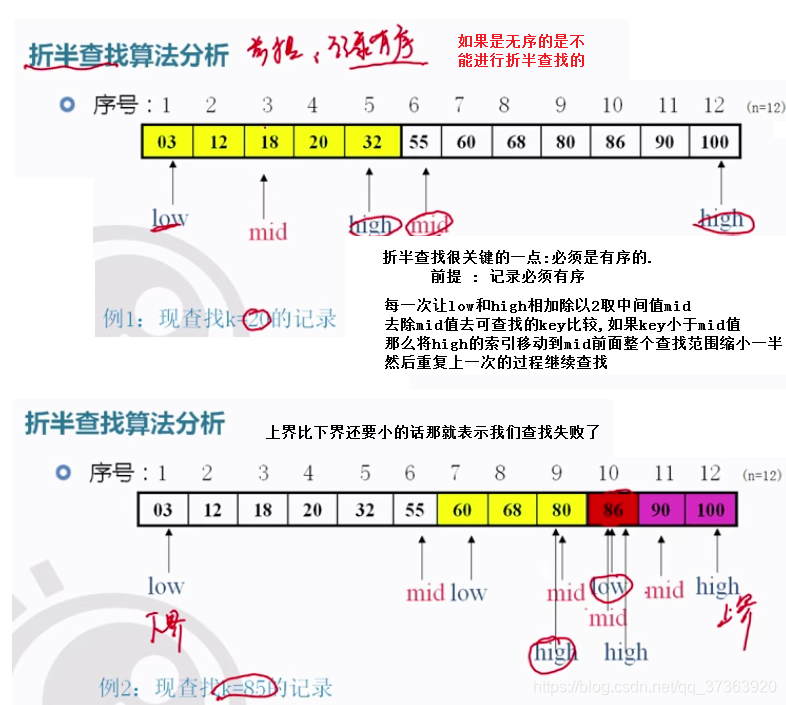
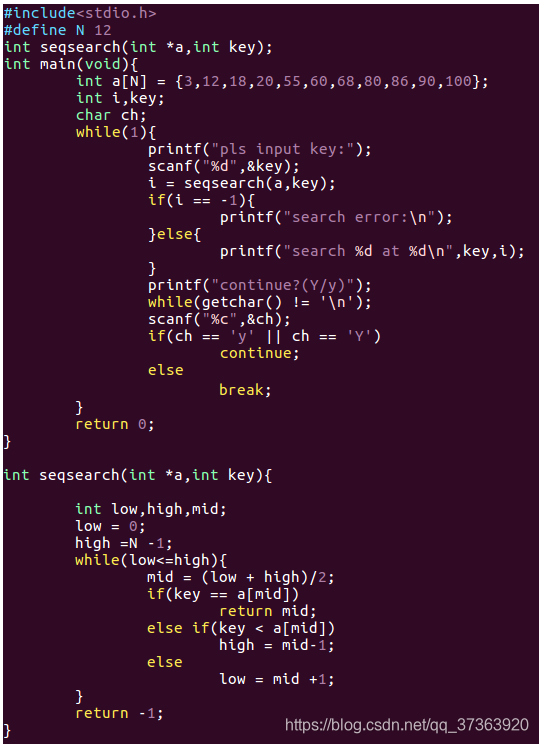
折半查找的特点:
1.它要求记录必须有序
2.查找效率要高


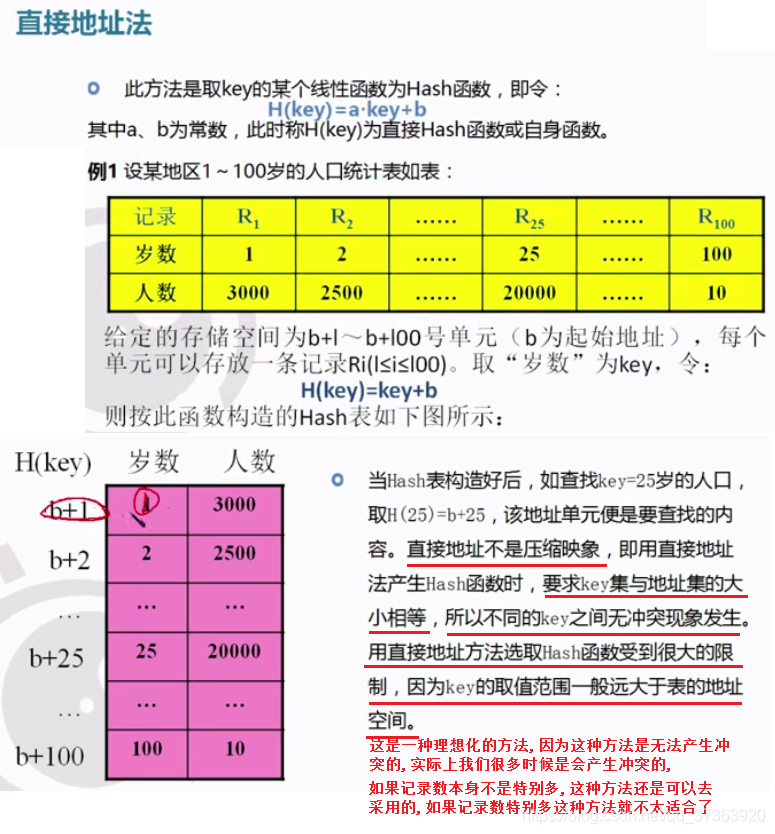
存储记录时 有意的将我们的每一个key, 通过某种方式算出来它的地址,将这个记录存到某一个地址里面去, 这样我们的记录key和这个记录本身的相对位置就会有一种联系, 那么将来我们查找,只要给出一个key就可以马上知道这个key得地址,继而可以取出这个数据
以这种方式存储起来之后, 这个存储的空间就是我们Hash表的空间
在一个存储空间当中每个记录的key和它存储位置有着某种关系那么这样的一个存储空间就称之为Hash表空间,一定是个Hash表空间
Hash表空间的key一定和它的位置有某种关系

就相当于中国人给孩子取名字,中国的汉字是有限的,会有很多人的名字相同,而在我们构造Hash表的过程中也是类似的, 不同的数据在通过Hash函数算出这个Hash地址的时候,会出现,不同的key会得到相同的Hash地址,这意味着我们需要将这两个不同的记录放在同一个地址的位置,这就不行了,一个空间只能放一个数据,这种情况我们叫冲突,所以在构建Hash表的时候呢不仅要选取一个恰当的Hash函数而且当我们选取这个Hash函数在存储记录的过程中出现了冲突之后,我们必须要处理这个冲突.
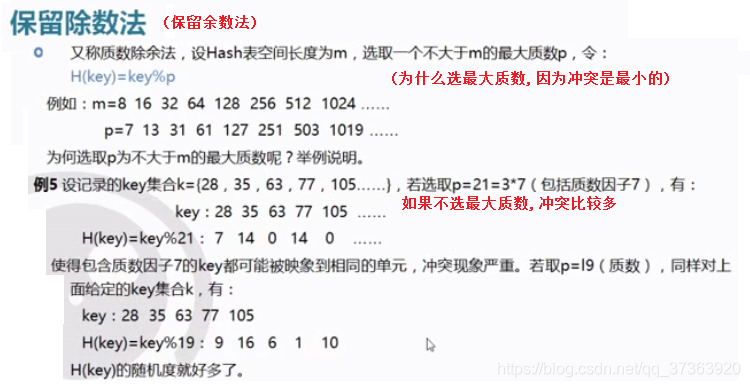
当我们遇到冲突的时候要处理冲突 (冲突是不可避免的)
建立Hash表 两个重点:
- 如何选取Hash函数
- 如何处理冲突
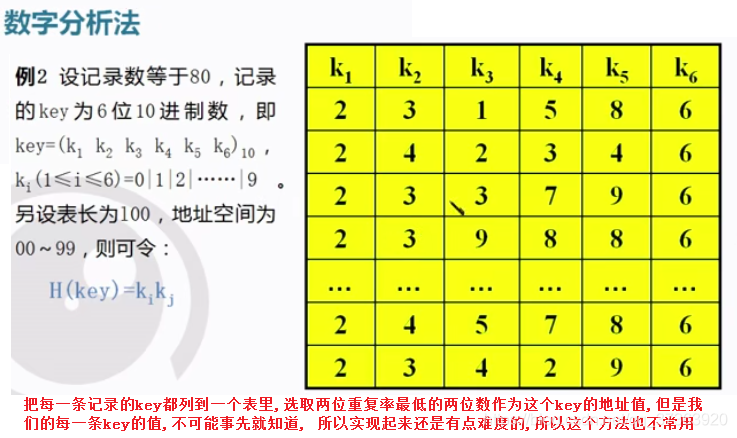
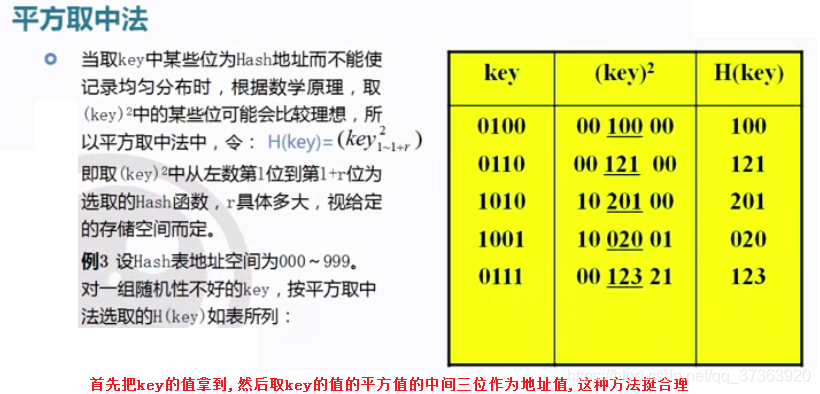
这两个的都有现成的, Hash函数有很多, 处理冲突也有很多的方法

建立Hash表有两个关键点:
1.选取一个恰当的Hash函数
2.处理冲突的方法
























 1866
1866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









