









简介
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。(当然,我们最喜欢的是Elasticsearch)
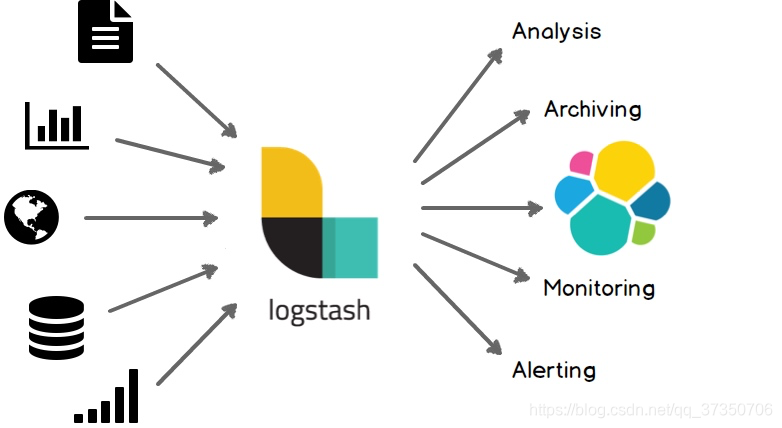
输入:采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
过滤器:实时解析和转换数据
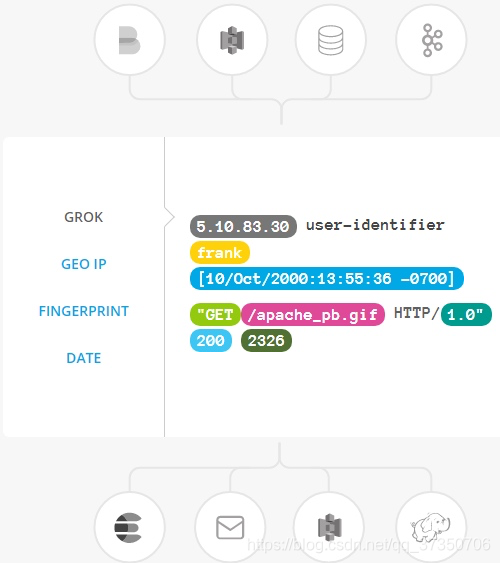
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响:
利用 Grok 从非结构化数据中派生出结构
从 IP 地址破译出地理坐标
将 PII 数据匿名化,完全排除敏感字段
整体处理不受数据源、格式或架构的影响
输出:选择你的存储,导出你的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
安装
去官网下载Logstash https://www.elastic.co/cn/downloads/logstash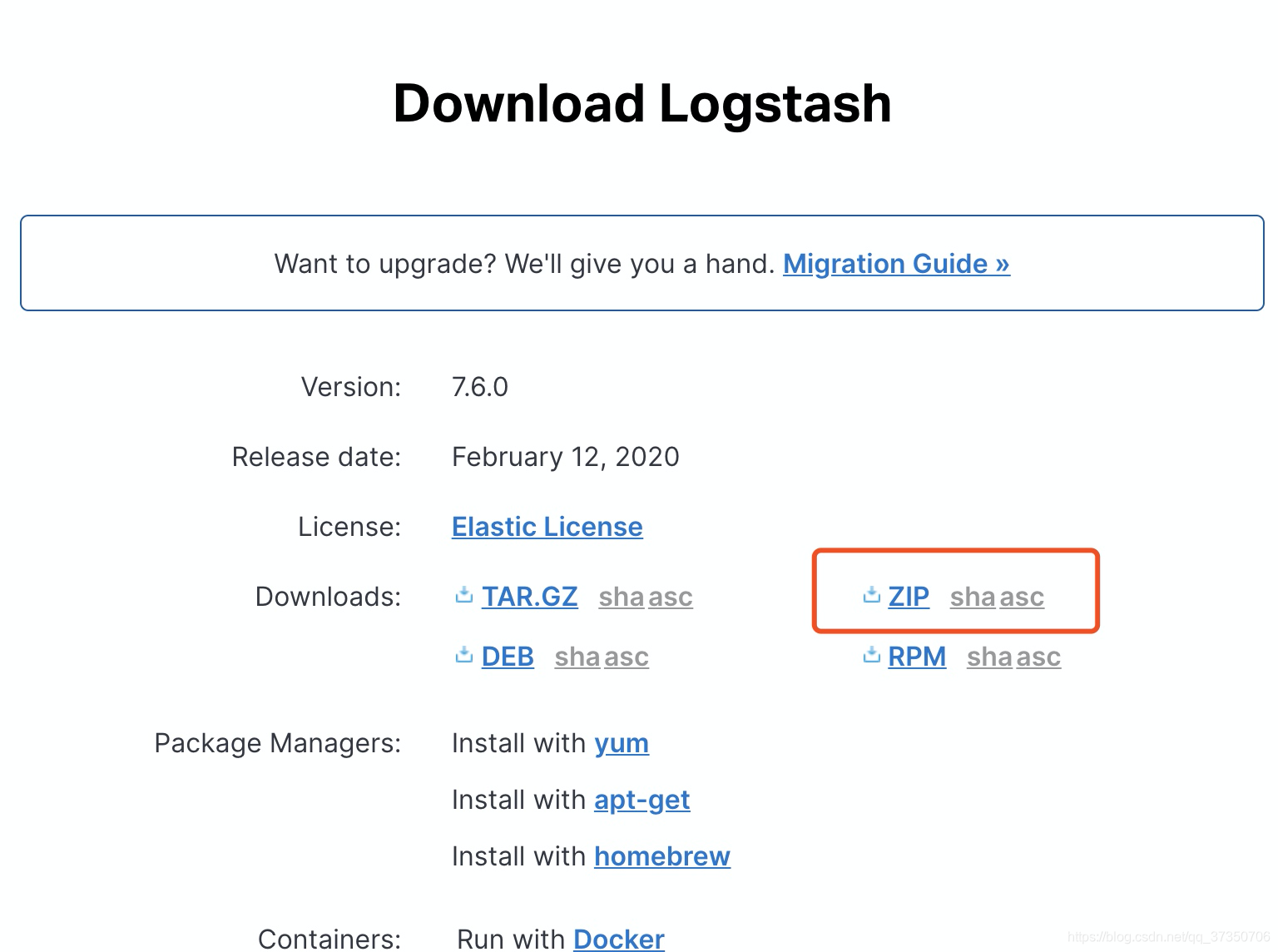
解压后 放在你喜欢的位置。这里建议放在Elasticsearch同级目录下
首先,让我们通过最基本的Logstash管道来测试一下刚才安装的Logstash
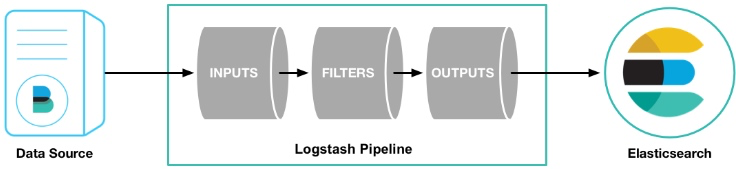
Logstash管道有两个必需的元素,输入和输出,以及一个可选元素过滤器。输入插件从数据源那里消费数据,过滤器插件根据你的期望修改数据,输出插件将数据写入目的地。
接下来,允许Logstash最基本的管道,例如:
bin/logstash -e 'input { stdin {} } output { stdout {} }'(画外音:选项 -e 的意思是允许你从命令行指定配置)
启动以后,下面我们在命令行下输入"hello world"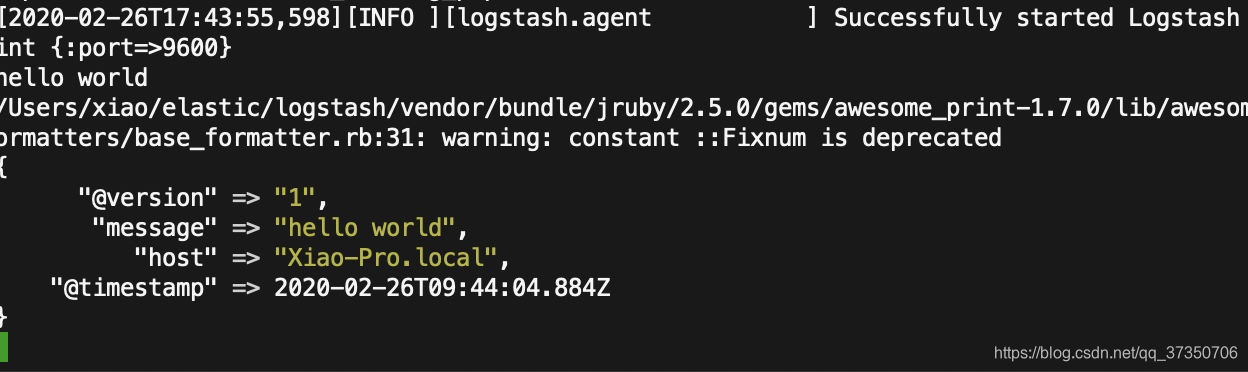
这样我们的最基本Logstash管道测试成功了!
在现实世界中,一个Logstash管理会稍微复杂一些:它通常有一个或多个input, filter 和 output 插件。
input {}
filter {}
output {}
我们去logstash 的config目录下创建一个logstash.conf文件。编辑它
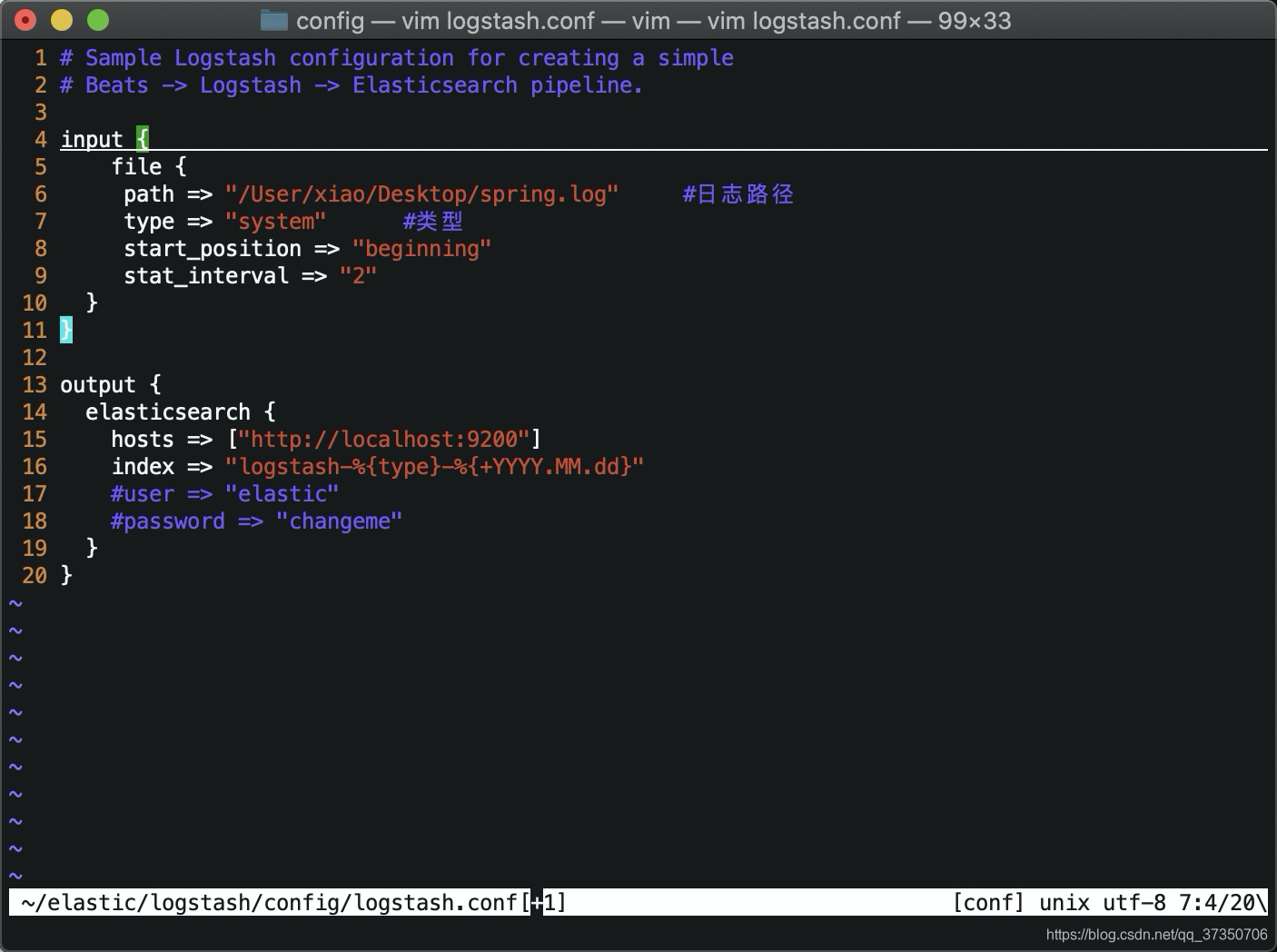
这个是我一个简单的spring启动日志。我就没用filter
去启动这个配置
到bin目录下
./logstash -f ../config/logstash.conf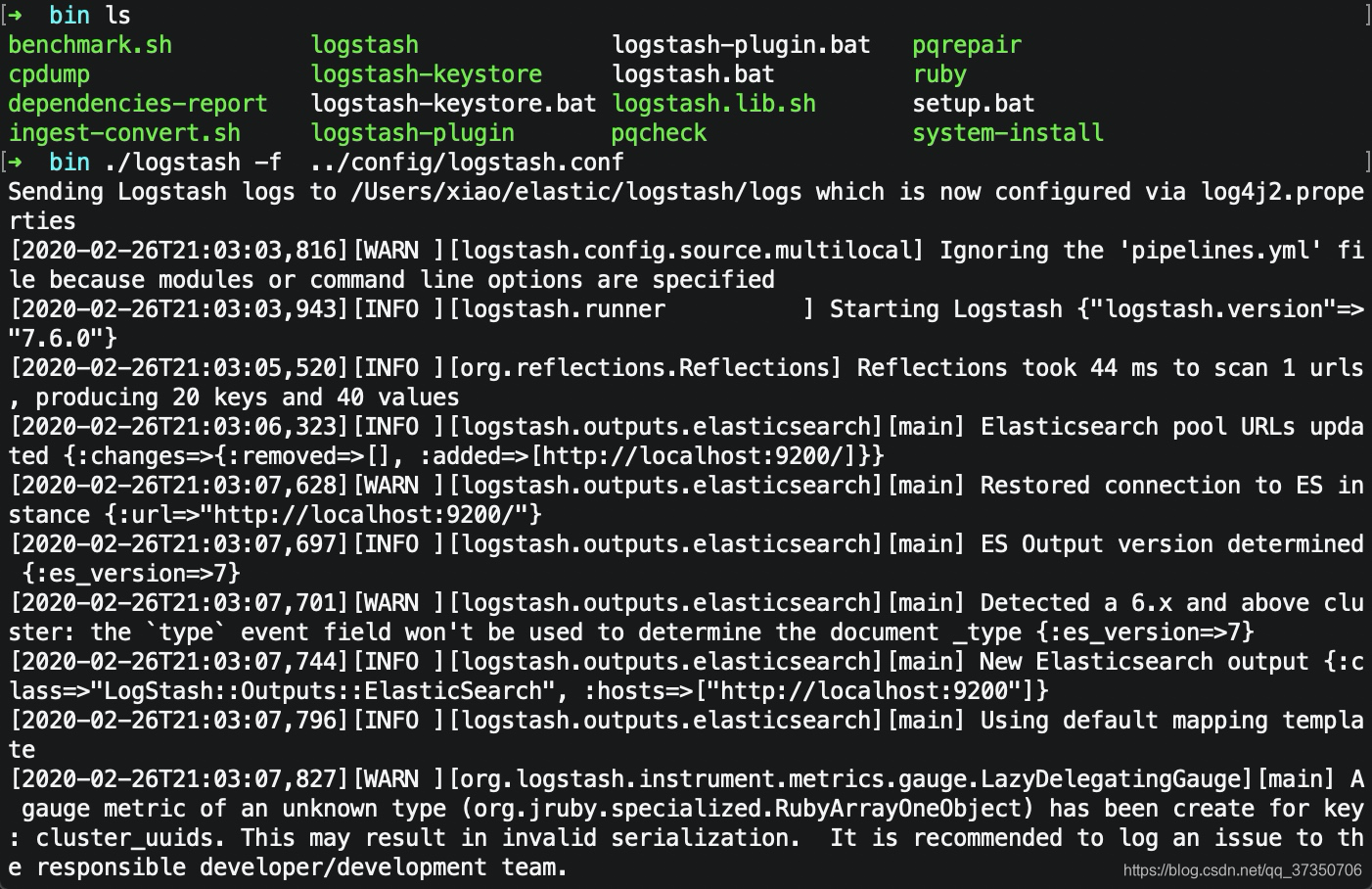
我们去http://localhost:5601/的kibana管理台 Logs 下 就可以看到我们的日志信息了
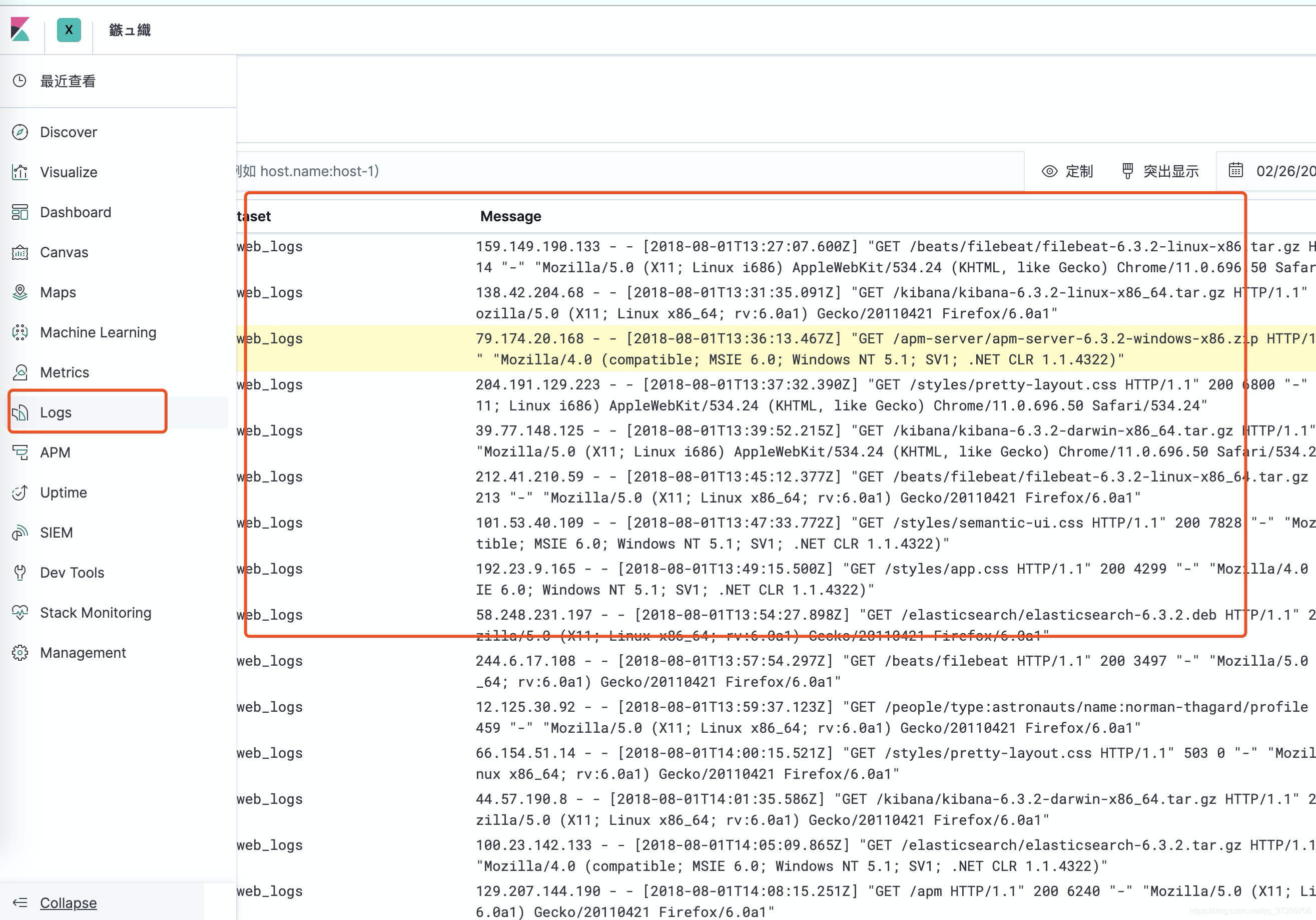
可以进行定制的筛选 突出显示
好了Logstash简单的配置和使用我们就算入门了!
其他就交给大家深入研究了。
这个是我的个人微信公众号 有兴趣可以关注一下 也会分享一些技术性文章


















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









