







 本文详细介绍了HBase的写数据流程,包括预写日志(wallog)、内存写入(memstore)及后续的storefile合并与split过程;阐述了读数据流程,重点解释了如何利用布隆过滤器提高storefile查询效率。
本文详细介绍了HBase的写数据流程,包括预写日志(wallog)、内存写入(memstore)及后续的storefile合并与split过程;阐述了读数据流程,重点解释了如何利用布隆过滤器提高storefile查询效率。
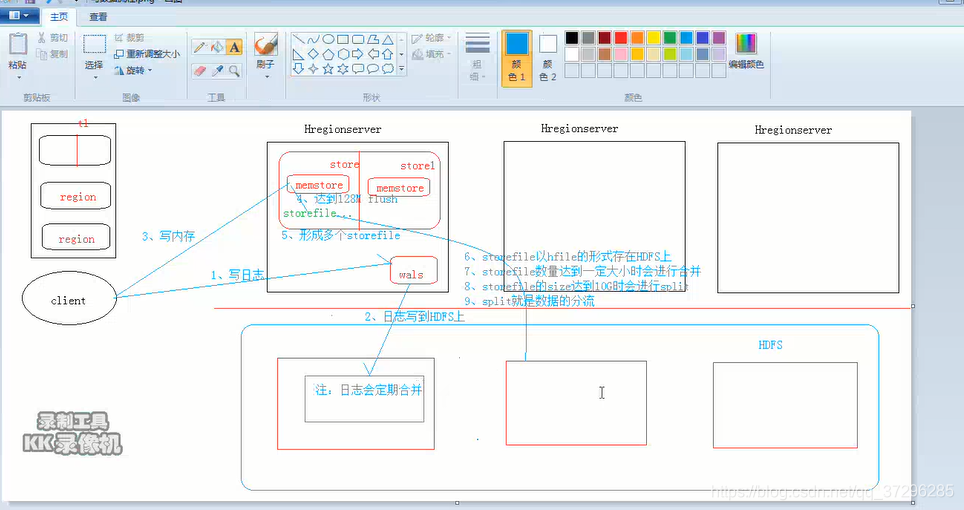
一 写数据流程概述
- 客户端要访问zk,因为zk上存储着root表的位置信息,进而可以一层层的找到需要访问的Hregionserver(通过root表找到meta表,进而确定是哪个Hregionserver)
- 客户端要预写日志(wal log),防止宕机,日志其实存储位置是在hdfs集群上的
注意:日志在hdfs上会定期合并的。 - 客户端要写入到内存(memstore),当达到128M的,会进行刷写磁盘(storefile),storefile的存储位置也是在hdfs集群上的
- storefile的数量达到一定大小的时候会进行合并
- storefile达到10G时会进行split,split就是数据的分流
注意:第4步的原因,当storefile不合并的情况下,容易造成数量过多,影响查找效率
第5步的原因,当一个storfile过大的时候,在一个storefile内部查询,也会影响效率,10个G是效率比较高的一种方式。
二 读数据流程
- 客户端首先要访问zk,zk上存储着root表的信息, 最终找到hregionserver。
注意:root表和meta表是存放在hregionserver上的,这点和hbase的普通表不太一样 - 开始读取hregionsever,首先读取memstore,因为memstore其中存储的是热数据(即最新的数据),如果没有找到想要数据,则再去读取storefile。
那么问题来了,那么多storefile,如何确定去读取哪一个storefile?
解决方案就是布隆过滤器(详解请看第三部分)。
三 布隆过滤器

举例说明:
例如要查找一个URL,我们可以将存放URL的storefile文件的rowkey转成一个二进制数组存储起来,只存储1,不存0,把0位空着,这样我们可以使用这个数组去存储多个storefile文件。
我们当去查找一个URL的时候,不必要去全部扫描所有的storefile文件,仅仅去匹配那个数组就行,当然就算所有的1全部匹配上,也有可能出错,但整体减少的工作量,还是很可观的,误差率咋百分之一左右。
这就是一种空间换时间的做法。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









