




 本文详细介绍了文本分类的过程,包括预处理(如分词、去除停用词)、文本表示(如布尔模型、向量空间模型)、特征降维、分类器(如决策树、SVM)和分类性能评估。
本文详细介绍了文本分类的过程,包括预处理(如分词、去除停用词)、文本表示(如布尔模型、向量空间模型)、特征降维、分类器(如决策树、SVM)和分类性能评估。
传统的文本分类过程通常包括训练模块和分类模块如下图所示:一般来讲文本分类过程包括预处理、文本表示、特征降维、训练分类器和分类性能评估。
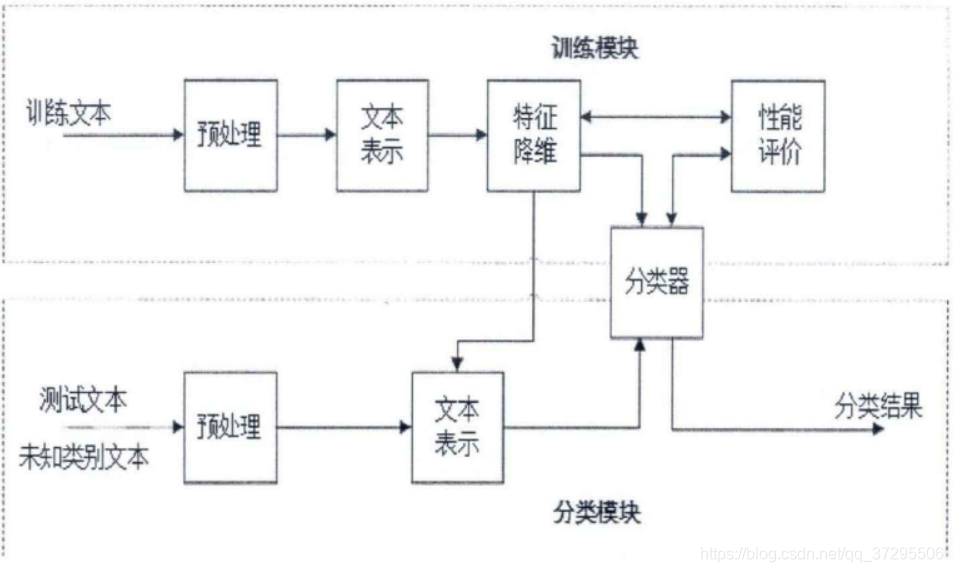
文本分类过程图
1、文本分类预处理
由于计算机很难直接处理网络上存在的大量半结构化或结构化的文本数据,所以在文本分类之前需要对这些数据进行相应的预处理。
文本的预处理包括文本分词、去除停用词(包括标点、数字和一些无意义的词)、词义消歧、统计等处理。中文与英文相比,在分类上关键的区别是在数据集的预处理阶段。对中文文本进行分类之前,首先要进行分词处理,而英文文本单词与单词之间则有空格进行分割,无需进行分词。近几年,中文文本的分词技术主要有三类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词。
A、基于字符串匹配的分词方法
该方法也成为机械分词方法,其主要思想
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4646
4646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









