




 本文档详细介绍了如何使用Scrapy框架创建一个爬虫项目,爬取书籍网站的数据。首先创建Scrapy项目并定义书籍信息的Item类,接着在Spider中实现了书籍列表页面和书籍详情页面的解析函数,提取所需链接和书籍信息,最终成功保存数据到CSV文件。
本文档详细介绍了如何使用Scrapy框架创建一个爬虫项目,爬取书籍网站的数据。首先创建Scrapy项目并定义书籍信息的Item类,接着在Spider中实现了书籍列表页面和书籍详情页面的解析函数,提取所需链接和书籍信息,最终成功保存数据到CSV文件。
上文中我们了解到了如何在网页中的源代码中查找到相关信息,接下来进行页面爬取工作:
1、首先创建一个Scrapy项目,取名为toscrape_book,接下来创建Spider文件以及Spider类,步骤如下: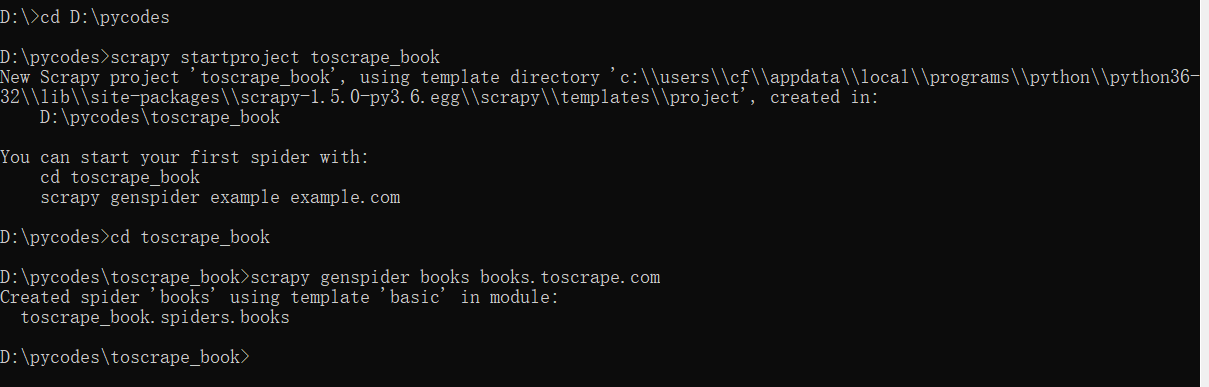
整个Scrapy框架建于D盘下的pycodes文件夹中,并在文件夹下的Spider文件中建立一个名为books的爬虫文件。
2、在实现Spider之前,先定义封装书籍信息的Item类,在toscrape_book/items.py中添加如下代码:
class BookItem(scrapy.Item):
name=scrapy.Field() #书名
price=scrapy.Field() #价格
review_rating=scrapy.Field() #评价等级,1-5星
review_num=scrapy.Field() #评价数量
upc=scrapy.Field() #产品编码
stock=scrapy.Field() #库存量3,接下来按照5步完成BooksSpider。
(1)继承Spider创建BooksSpider类(已完成)。
(2)为Spider取名(已完成)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









