




 本文介绍如何使用Scrapy爬虫框架爬取书籍网站的数据,包括书名、价格等信息,并将结果存储为CSV文件。通过scrapy shell进行网页分析,提取书籍详情页链接,并展示在shell中调用view函数进行页面查看的操作流程。
本文介绍如何使用Scrapy爬虫框架爬取书籍网站的数据,包括书名、价格等信息,并将结果存储为CSV文件。通过scrapy shell进行网页分析,提取书籍详情页链接,并展示在shell中调用view函数进行页面查看的操作流程。
本文运用了Scrapy爬虫的知识,爬取了点击打开链接网站中的书籍信息,可以了解到基本Scrapy爬虫框架的使用方法。
一、项目需求:
1、其中每本书的信息包括:书名、价格、评价等级、产品编码、库存量、评价数量。
2、将爬取的结果保存到csv文件中。
二、在前期分析网页页面时,可以用Chrome开发者工具,也可以用scrapy shell<URL>命令,如下:
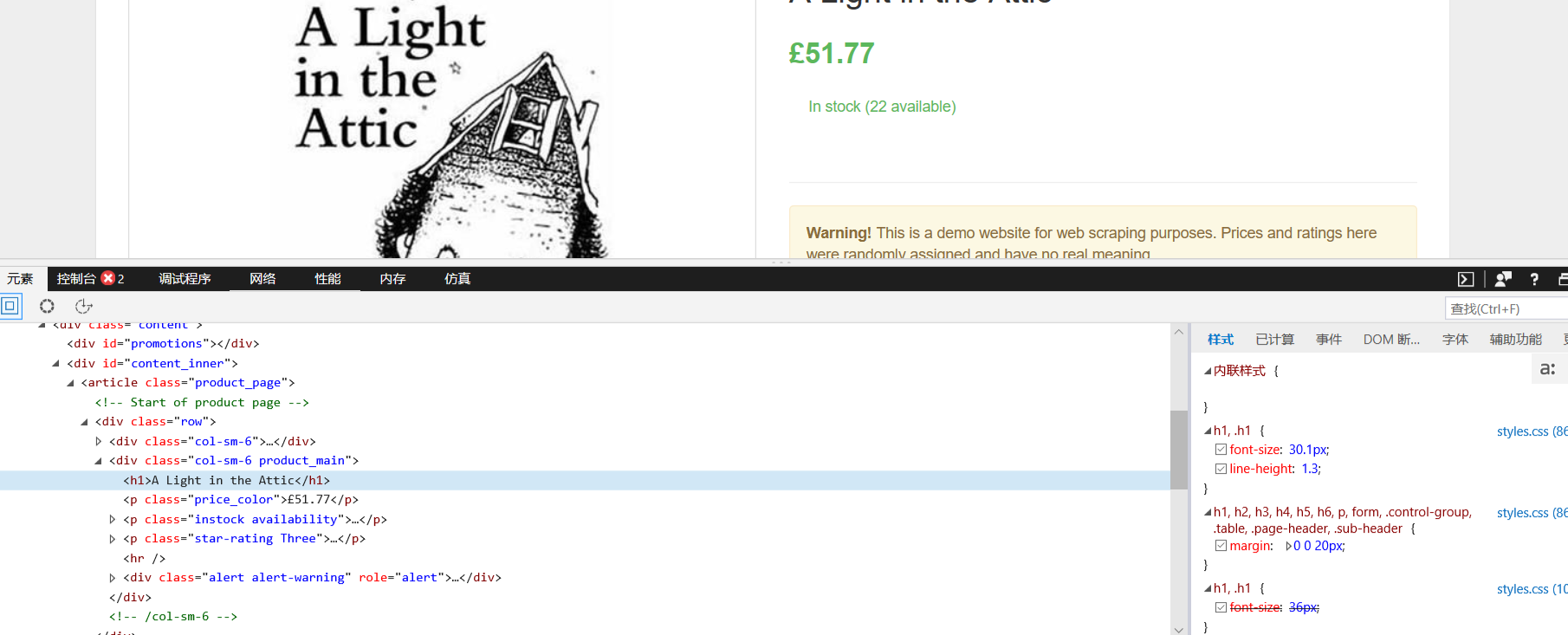
Chrome开发者工具这里不做介绍了,第二种方法在命令提示符下输入scrapy shell<URL>即可在交互式命令下操作一个Scrapy爬虫,如:scrapy shell http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html,(这里操作的是第一本书籍的页面),部分截图如下:

接下来,在scrapy shell中调用view函数,在浏览器中显示response所包含的页面:即输入:view(response)
在进行页面分析时,使用view函数打开的页面要比使用Chrome审查元素工具更加可靠。如下图:
*****************************************************************************************************************************
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1360
1360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









