






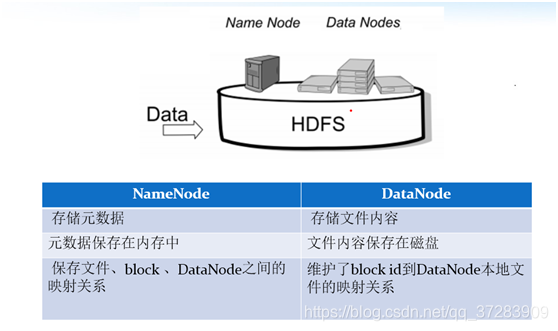
 HDFS采用NameNode作为中心服务器管理文件系统命名空间和客户端访问,NameNode仅在内存中维护文件到DataNode的映射关系。文件操作中,NameNode处理元数据,DataNode处理文件内容的读写。NameNode负责副本放置策略,确保读取效率,同时通过心跳和状态报告监控DataNode健康状态。文件以Block形式存储,Block大小在Hadoop1中为64M,Hadoop2中为128M,可通过配置调整。
HDFS采用NameNode作为中心服务器管理文件系统命名空间和客户端访问,NameNode仅在内存中维护文件到DataNode的映射关系。文件操作中,NameNode处理元数据,DataNode处理文件内容的读写。NameNode负责副本放置策略,确保读取效率,同时通过心跳和状态报告监控DataNode健康状态。文件以Block形式存储,Block大小在Hadoop1中为64M,Hadoop2中为128M,可通过配置调整。
hdfs的基础架构
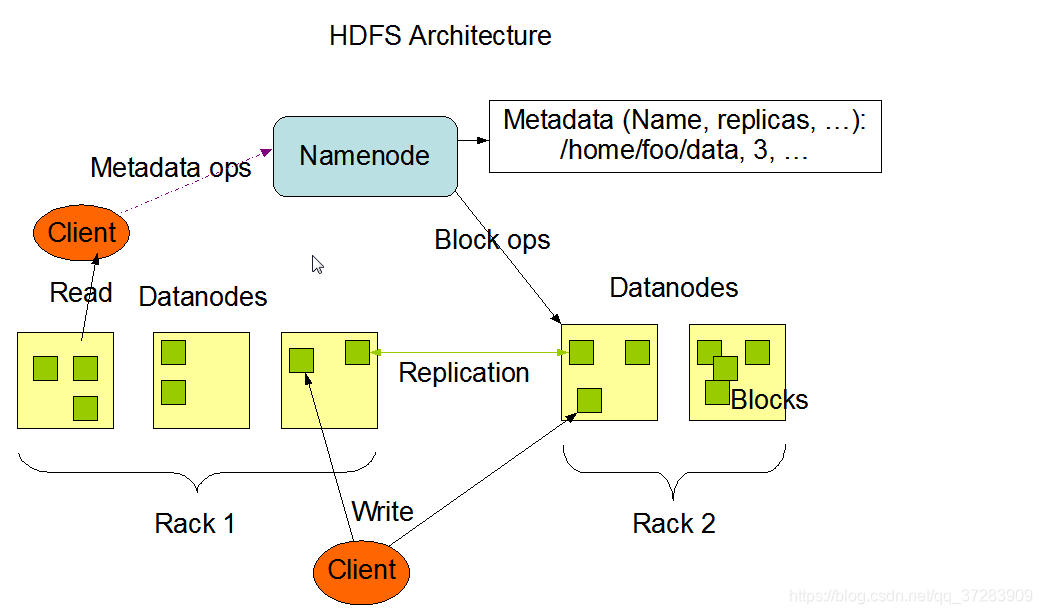
1、 NameNode是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
a.文件名称
b.文件目录结构
c.文件属性 创建时间 权限 副本数
d.文件对应哪些数据块
–>数据块对应哪些datanode节点上
blockmap
nn节点不会持久化存储这种映射关系
dn定期发送blockreport 给nn,
以此nn在【内存】中动态维护这种映射关系!
2、 文件操作,namenode是负责文件元数据的操作,datanode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过Namenode,只询问它跟哪个dataNode联系,否则NameNode会成为系统的瓶颈
3、 副本存放在哪些Datanode上由NameNode来控制,根据全局情况作出块放置决定,读取文件时NameNode尽量让用户先读取最近的副本,降低读取网络开销和读取延时
4、 NameNode全权管理数据库的复制,它周期性的从集群中的每个DataNode接收心跳信合和状态报告,接收到心跳信号意味着DataNode节点工作正常,块状态报告包含了一个该DataNode上所有的数据列表
NameNode与Datanode的总结概述:
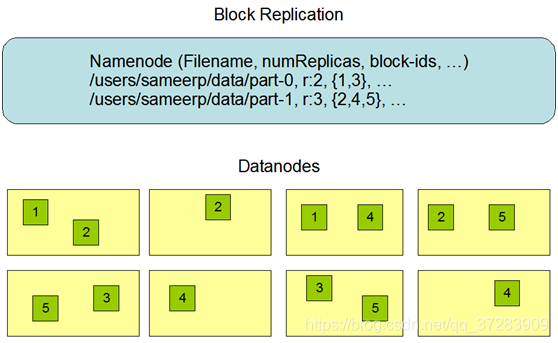
hdfs的文件副本机制及block块存储
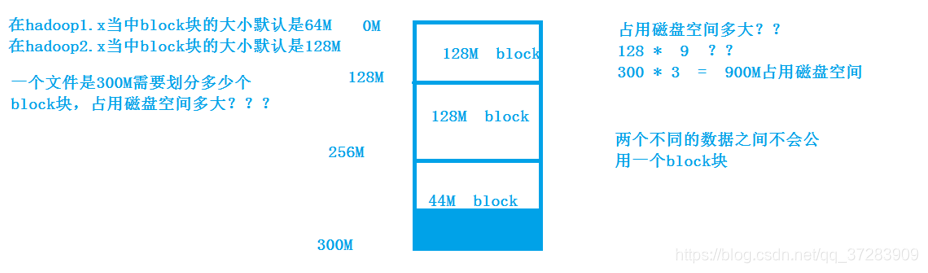
所有的文件都是以block块的方式存放在HDFS文件系统当中,在hadoop1当中,文件的block块默认大小是64M,hadoop2当中,文件的block块大小默认是128M,block块的大小可以通过hdfs-site.xml当中的配置文件进行指定
<property>
<name>dfs.block.size</name>
<value>块大小 以KB为单位</value>//只写数值就可以
</property>

















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









