









 这篇博客介绍了数据预处理的重要步骤,包括检查并处理缺失值,用平均值填充天津地区的常住人口和GDP数据,删除北京数据的重复值,并通过绘制盒图展示并处理异常值。最后,将北京和天津数据合并成一个完整的数据集。
这篇博客介绍了数据预处理的重要步骤,包括检查并处理缺失值,用平均值填充天津地区的常住人口和GDP数据,删除北京数据的重复值,并通过绘制盒图展示并处理异常值。最后,将北京和天津数据合并成一个完整的数据集。
# encoding:utf-8
# 数据预处理
# 读取数据
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
Font = FontProperties(fname="C:\Windows\Fonts\msyh.ttc") # 字体
BJ_data = pd.read_csv('北京地区信息.csv', encoding='GBK')
TJ_data = pd.read_csv('天津地区信息.csv', encoding='GBK')
# 数据预处理
# 1. 判断有没有空值
# print(BJ_data.isnull())
# print(TJ_data.isnull().value_counts())
# 对缺失值进行填补,通常有三种方式:1.直接删掉 2.人工填补 3.不管
population1 = TJ_data['常住人口(万人)'].mean()
# 平均值填充, 还有拉格朗日,牛顿等插值方式进行填充
population2 = 81.60
GDP = TJ_data['GDP(亿元)'].mean()
values = {
'常住人口(万人)': population2,
'GDP(亿元)': GDP
} # 字典形式填充数据
TJ_data = TJ_data.fillna(value=values) # 使用fillna方法
# print(TJ_data.isnull().value_counts())
# 2.重复值处理
# print(BJ_data.duplicated()) # 判断是否有重复值,判断是否存在两行数据一致
BJ_data = BJ_data.drop_duplicates()
# print(BJ_data.duplicated())
# print(TJ_data.duplicated())
# 3. 异常值处理
# print(BJ_data)
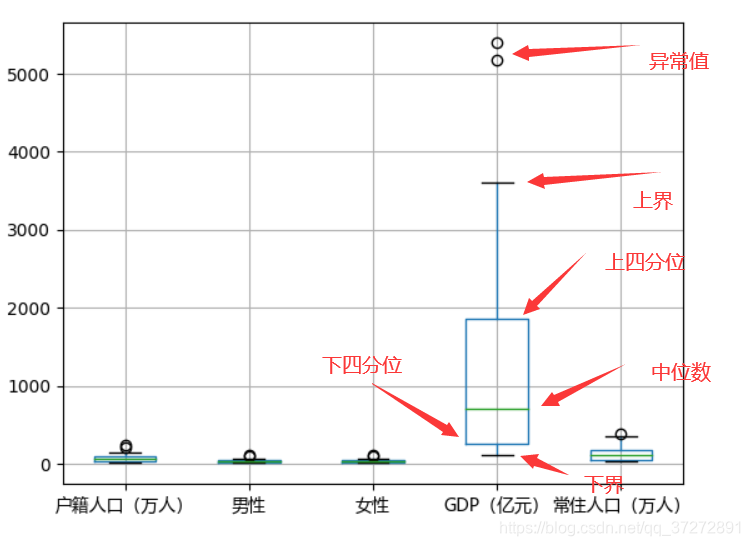
# 盒图 上界,上四分位,中位数,下四分位,下界
BJ_data.boxplot(['户籍人口(万人)','男性','女性','GDP(亿元)','常住人口(万人)'])
plt.xticks(FontProperties=Font)
plt.show()
# 4. 数据合并
con_data = pd.concat([BJ_data,TJ_data],ignore_index=True) # ignore_index:是否重新组织索引
print(con_data)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









