









最近在学习Python可视化的相关知识,闲来无事,做了这个东西,就写下来啦,GO~~~~~~~
1.导出QQ聊天记录
1.1 PC端QQ聊天记录导出:
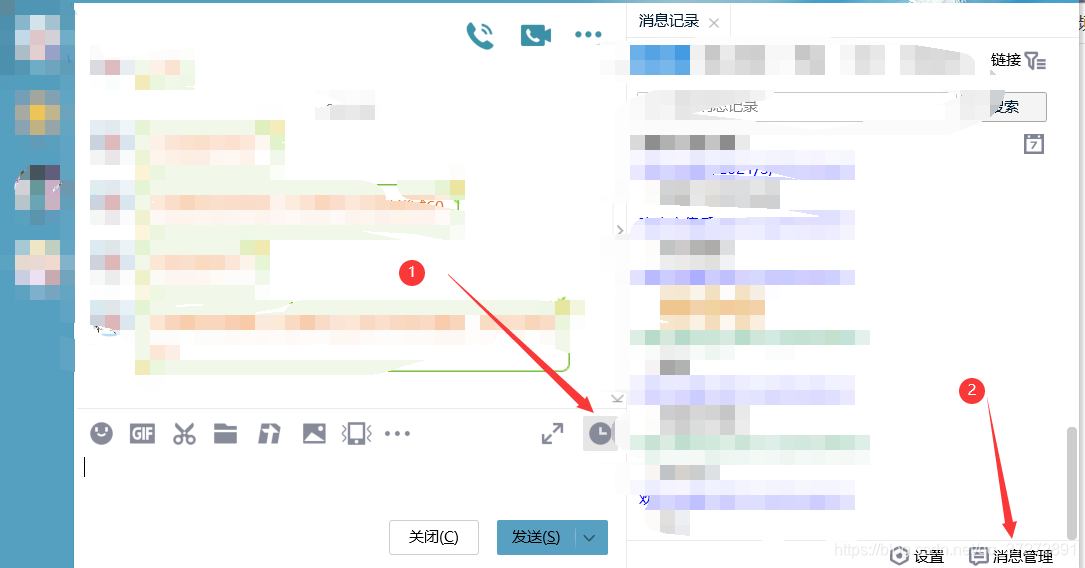
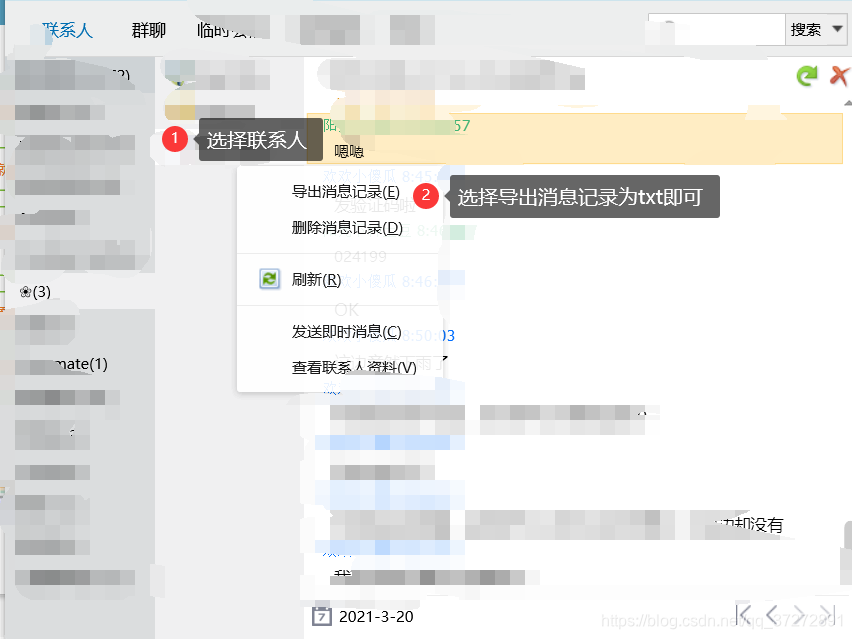
1.2 手机QQ记录导出
现在手机QQ端貌似不能直接导出,可以采用备份到电脑,然后再同步的方式来进行。
在手机QQ端,主页左划-->右下角-->选择设置-->点击通用-->点击聊天记录设置-->备份聊天记录到电脑
然后恢复聊天记录即可。
2.QQ聊天记录处理
2.1 读取QQ聊天记录
直接open聊天记录,然后,分析聊天记录,发现前八行为没有用处的消息头,切掉即可
f = open('test.txt',encoding='utf-8')
f_1 = f.readlines()#读取qq聊天记录
del fl[:8] #删除备份的QQ聊天记录的消息前八行2.2 删除QQ聊天记录时间线
在聊天记录中,存在着非常多的时间记录,根据观察,发现,每个时间记录后都跟着的是“昵称”,可以根据昵称为索引,删除即可
for i in f_1:
if i.find('对象昵称')>1:
f_1.remove(i)#删除
if i.find('自己昵称')>1:
f_1.remove(i)2.3 删除其它无关词
在QQ聊天记录中存在着“嗯嗯”,“请使用最新版本手机QQ查看”等无关词,删掉即可。
采取方法为:将列表转化为字符串,用replace函数删除。
strf = ' '.join(f_1)
list1 = re.findall(r'/.{2,3}', strf)
list2 = re.findall(r'\[.+?\]', strf)
set1 = set(list1)
set2 = set(list2)
for item in set1:
strf = strf.replace(item, '')
for item in set2:
strf = strf.replace(item, '')
strf = strf.replace('请使用最新版本手机QQ查看', '')
strf = strf.replace('请使用最新版手机QQ体验新功能', '')
strf = strf.replace('成功的接收了离线文件', '')
strf = strf.replace('嗯嗯', '')
strf.replace('\n','')
#此处参考了大佬 https://blog.youkuaiyun.com/haoyu_/article/details/79113846 的文章3.选择词云形状
如果想生成心形词云,就需要将心形词云的图片,想生成她的样子的词云,就需要她的样子的图片。选择合适的图片后,将图片背景转化为白色。
因为在词云的生成过程中,相当于是用一个罩子,覆盖底层的图片,进行喷绘,for example:

比如这个心形图片,其它部分为白色,设置白色部分不上字云,其它部分就不上了。
白色的RGB为#FFFFFF,当然,你也可以设置为其它颜色,在代码中修改即可。
from PIL import Image
def transparence_white(img):
sp = img.size
width = sp[0]#获取图片宽度
height = sp[1]#获取图片高度,对宽高形成的每一个像素点进行设置
for yh in range(height):
for xw in range(width):
dot = (xw, yh)
color_d = img.getpixel(dot) # 与cv2不同的是,这里需要用getpixel方法来获取维度数据
if (color_d[3] == 0):
color_d = (255, 255, 255, 255)
img.putpixel(dot, color_d) # 赋值的方法是通过putpixel
return img
img = Image.open('I_LOVE_YOU.png')
img = transparence_white(img)
# img.show() # 显示图片
img.save('mask.png') # 保存为mask,后面用
4.分生成词云
采用jieba库进行分词,以及wordcloud库进行词云制作。
word_list = jieba.cut(strf, cut_all=True)
word = ' '.join(word_list)
mask = np.array(image.open("mask.png"))
wordcloud1 = wordcloud.WordCloud(
mask=mask,
background_color='#FFFFFF',#如果mask颜色为其它色,做响应转变即可
# 若想生成中文字体,需添加中文字体路径
font_path="Alibaba-PuHuiTi-Heavy.otf"
).generate(word)
#返回对象
image_produce = wordcloud1.to_image()
#保存图片
wordcloud1.to_file("love_you.jpg")
#显示图像
image_produce.show()5.展示
5.1 原始版本

5.2 修饰版本

6.附完整代码
import re
import jieba
import wordcloud
import numpy as np
import PIL.Image as image
from PIL import Image
def transparence_white(img):
sp = img.size
width = sp[0]
height = sp[1]
for yh in range(height):
for xw in range(width):
dot = (xw, yh)
color_d = img.getpixel(dot) # 与cv2不同的是,这里需要用getpixel方法来获取维度数据
if (color_d[3] == 0):
color_d = (255, 255, 255, 255)
img.putpixel(dot, color_d) # 赋值的方法是通过putpixel
return img
def world_cloud(path,lover_nickname,you_nickname,mask_path,word_cloudpath=''):
f = open(path, encoding='utf-8')
f_1 = f.readlines()
for i in f_1:
if i.find(you_nickname) > 1:
f_1.remove(i)
if i.find(lover_nickname) > 1:
f_1.remove(i)
strf = ' '.join(f_1)
list1 = re.findall(r'/.{2,3}', strf)
list2 = re.findall(r'\[.+?\]', strf)
set1 = set(list1)
set2 = set(list2)
for item in set1:
strf = strf.replace(item, '')
for item in set2:
strf = strf.replace(item, '')
strf = strf.replace('请使用最新版本手机QQ查看', '')
strf = strf.replace('请使用最新版手机QQ体验新功能', '')
strf = strf.replace('对方已成功接收了您发送的离线文件', '')
strf = strf.replace('嗯嗯', '')
strf.replace('\n', '')
word_list = jieba.cut(strf, cut_all=True)
word = ' '.join(word_list)
mask = np.array(image.open(mask_path))
wordcloud1 = wordcloud.WordCloud(
mask=mask,
background_color='#FFFFFF',
# 若想生成中文字体,需添加中文字体路径
font_path="Alibaba-PuHuiTi-Heavy.otf"
).generate(word)
# 返回对象
image_produce = wordcloud1.to_image()
# 保存图片
wordcloud1.to_file(word_cloudpath)
# 显示图像
image_produce.show()
OVER


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









